Introduction
The method-refactoring strategy dubbed Replace Method with Method Object
is very useful and merits a quick review, to set the background for the discussion to follow. There are many good explanations of the strategy available on the Web. My
understanding and appreciation of it was deepened by reading the article at the preceding link.
The problem that motivates using this strategy is, "a long method [or code sequence within a method] that uses [many] local variables" so that one cannot readily
decompose it into many smaller methods that have short parameter lists.
Closely related is the situation in which existing methods have too many parameters. A couple of other approaches can be used to reduce the numbers of parameters
passed:
- The Introduce Parameter Object strategy entails grouping a set of
parameters that "naturally go together" into a new class or structure. In theory, after doing this, one should notice behavior that also naturally goes with the
data, which can lead to additional beneficial refactoring.
- The Preserve Whole Object strategy suggests that if several properties
of an object are being passed as parameters to a method, why not pass the entire object?
If neither of the above approaches seems satisfactory, "replace method with method object" can be engaged as "heavy artillery" that will help resolve even the
stickiest situations. This article and the associated code are aimed at helping with the application of this strategy.
Background
I tend to have reservations about the "preserve whole object" strategy, because there is a huge difference between passing a reference to an object and passing
a snapshot of selected property values from that object. If I pass (by value) a snapshot of property values, the called method can do what it wants with that limited
amount of data without risk of inadvertently changing the state of the original object; but if I pass a reference to the original object, the called method can cause
all sorts of havoc. Taking into account factors like collaborating with other developers in real time and multiple people making changes to the code over a possibly
long period of time, it just seems safer to me to expose to methods only the data they genuinely need to access.
"Introduce parameter object" runs up against a wall when the number of parameters that one wants to group together becomes large. This same wall is actually
incorporated as a "feature" of the "replace method with method object" strategy as it was originally articulated: "Give the new class a constructor that takes the
source object and each parameter." If that constructor is going to have to take more than some small number n - probably around n=5, as a matter of personal taste -
parameters, no, that is not something that I want to do. While calling a constructor (or any method) that's excessively endowed with parameters may be viewed as
a necessarily sub-optimal part of an overall improvement to be yielded by applying a given strategy, it is also going to involve trading one "code smell" for another,
and one might earnestly hope for a better alternative. "Too many parameters" is one of the problems that I definitely want to solve - not one that I am willing to
embrace as part of a long-term solution to other problems.
It seems clear (to me) that one of the fundamental questions that should be dealt with, but that is frequently glossed over, is,
"What is wrong with a method (or constructor) having a lengthy parameter list? Why does this make code hard to read,
understand and maintain?" Complaining about inherent code complexity and low level
of abstraction may have its place, but for the purposes of this discussion I will assume that there isn't much we can do about those problems. So we have some large
amount of data that needs to be dealt with on a piecemeal basis at some point, or perhaps multiple points. At the very least, we need to stuff all of that data, all
at once, into an object so that it is more convenient to work with.
C#'s object initializer syntax can be an aid, along with good naming practice. Let's assume that we are creating a new "parameter object" class and have control of
naming properties. Further, we understand the code and can develop meaningful property names, yielding good naming that promotes understanding for the next person who
comes along, or for ourselves a few days / weeks / months in the future. Then we can associate each parameter (in its new incarnation as a property) with a name that
gives it as much meaning as possible in the context of the new class that we are creating. The same applies if we are creating a "method object" that's going to help
us refactor a long, complicated method that already takes too many parameters, our would end up doing so if we used a less potent approach to refactoring.
So, because we are creating a method object or parameter object and giving its properties very meaningful names, by using object initializer syntax instead of
passing positional parameters to a method, we're able to display more information to the reader of our code - specifically, strong hints about what the bits of data
we're collecting together will mean and how they will be used in the new context of the method object.
To ensure that this is point is made clear, consider this method signature that I just grabbed from a question posted on Code Review Stack Exchange that concerns
too many parameters...?:
XmlNode LastNArticles(
int NumArticles,
int Page,
String Category = null,
String Author = null,
DateTime? Date = null,
String Template = null,
ParseMode ParsingMode = ParseMode.Loose,
PageParser Parser = null);
A call to the method might look like this:
var node = LastNArticles(20, 5, Categories.Miscellaneous, currentAuthor, selectedDate, null,
ParseMode.Strict, selectedParser);
Regardless of whether such a call is considered "clear enough" or not by someone who already has some knowledge of the code and the application of which it is a part,
wouldn't it be easier to understand if we could, and did, specify explicitly what parameter each argument value gets assigned to? One could write:
var node = LastNArticles(
NumArticles: 20,
Page: 5,
Category: Categories.Miscellaneous,
Author: currentAuthor,
Date: selectedDate,
ParseMode: ParseMode.Strict,
Parser: selectedParser);
This is already legal C# syntax, although we aren't usually encouraged to use it for the purpose illustrated above. (Notice that we can omit the initialization of
Template because the method signature specified a default value for that parameter. With the parameters explicitly named, we could also rearrange their order, listing
them alphabetically or according to some other scheme that makes it easier to look up the value to which a given parameter was initialized.)
And this looks very much like object initializer syntax, the biggest difference between the two being whether one uses an assignment operator or a colon to match the
parameter names with the values being assigned.
If we were constructing a parameter object for this method, it might be called ArticleSearchParameters and might be initialized like this:
var parameters = new ArticleSearchParameters
{
Author = currentAuthor,
Category = Categories.Miscellaneous,
Date = selectedDate,
NumArticles = 20,
Page = 5,
ParseMode = ParseMode.Strict,
Parser = selectedParser
};
Although this is to essentially the same effect in terms of providing information to both code and the reader as the method call shown earlier, it is syntax that we are
more used to seeing in C# - and that won't be flagged as "redundant" by style-checking tools!
Before we rush off to start creating new classes and structures to replace lengthy parameter lists, we do well to pause and consider that the semantics surrounding
method parameters are significantly richer than those related to object creation. With methods, we have in, ref and out parameters,
and the method signature also explicitly states which parameters are required and which are optional, with default values supplied if argument values aren't passed to
the optional parameters. And we give up all of that, when we use either of the "introduce parameter object" or the "replace method with method object" strategies!
"What can be done so that we don't have to give up the advantages of method specification and call semantics in moving to the use of objects
to pass parameters?"
was the question that led me down a path of design and development that led to the creation of something potentially useful: a MethodObjectHelper class that
provides specific purposeful infrastructure, along with a small number of custom attribute and exception types; and an associated standard pattern for creating a robust method
object that doesn't require giving up the benefits associated with method signatures and calls as an unfortunate side-effect. Admittedly, in this approach, the analogs
to ref and out parameters are imperfect; and in fact, everything requires just a bit more thought, ceremony and typing than specifying method
signatures and calls (which are rendered economical via their inclusion in C# as direct syntactic features of the language) - but I think the code and associated
patterns may be of benefit. So, I am hereby publishing this "system," and will see how many in the C# development community agree with me. And I don't see any reason why
VB.NET developers couldn't also use this, with appropriate translation. :)
I'll put the MethodObjectHelper class front and center, and call what I am going to describe the MOH-assisted approach to the "replace method with
method object" process and outcome.
MethodObjectHelper and the associated attributes, exceptions and code artifact miscellanea are available as a download, and if I were to try to explain how
they work in detail, this would become a very long article (that no one would read). Instead, I am going to explain how to use them to build a MOH-assisted method object
class in a very straightforward, algorithmic (clearly defined, step-by-step) manner.
Using the code
Step One: Construct a method signature, if you don't already have one. Please consider all of the usual options and use them freely:
- Which parameters, if any, need to be declared as
ref or out parameters? - Which parameters must be initialized by the calling code, and which ones can be given default values so that initialization by the calling code is optional?
- What should the return value and type of the method be, if any?
If you already have a Big Ugly Method (BUM) that takes far too many parameters, so much the better, because you can skip a step, or at least you are somewhat ahead of
the game. If the existing method is currently referencing values in its context that are currently "global" from its perspective, access to those will have to be
preserved by adding them to its parameter list. (Things may have to apparently get worse before they get better.)
Step Two: Construct a class in which each of the parameters to the BUM resulting from the first step becomes a property. It is appropriate, at this stage, to actually
start coding the class; just create a property with the same type and name as each of the BUM's parameters. Give them all the public access modifier - although
they won't actually be visible to external code at run-time under normal circumstances, due to a trick of the implementation that will be explained later. In
parameters need
only a get accessor - for now, just trust me on that point. Ref and out parameters should have both get and
set accessors. Unless your method signature specifies the return type as void, also create a property, called Result or
ReturnValue, representing the return value.
For now, make all of the accessors empty; we'll do something special with them in a later step.
Step Three: Decorate the properties created in step two with attributes that will define how they are used. In and ref parameter
properties need to
be decorated with the ParameterProperty attribute. Ref and out parameter properties must be decorated with the
ResultProperty
attribute. Notice that ref parameters have to be decorated with both attributes.
The ResultProperty attribute is parameterless.
ParameterProperty has one required parameter, which sets a Boolean property called MustBeInitialized.
- If you pass
true,
the decorated property must be initialized when the method object is used - which I call its invocation or activation time; like a method, (unless it ends up being
treated as data container, which is not particularly recommended, although possible) the method object will have a very brief lifetime. - If you pass
false, the decorated property can be left uninitialized by the code that
invokes / activates the method object.
As with optional method parameters, each optionally-initialized property should have a default value, which can be specified
in one of two ways:
- The most straightforward way is to set the
ParameterProperty attribute's DefaultValue property to the desired default value for the
decorated property.
This value can be "a constant expression, typeof expression or array creation expression" (to quote the error message that appears if you try to assign anything else)
that is consistent with the attribute property's type.
- If those restrictions are too confining, any default value that can be assigned to the decorated property can be set in code. There is a particular point in the
flow of control where it makes sense to do this, which I will mention at the appropriate point further along in these instructions. If you find it necessary to
resort to this technique, it will be a good idea to assign true to the
ParameterProperty attribute's DefaultValueSetInCode property,
which has a
documentary purpose: It redirects a reader of the code to look for the default-setting code in the appropriate and customary place, and it serves notice that the
developer didn't just (sloppily, and potentially disastrously) omit assigning a default value to the property.
Step Four: As you may have guessed, the ParameterProperty and ResultProperty attributes serve practical, functional purposes, in that
code in the MethodObjectHelper class actually uses them at run-time. To use the MOH-assisted approach that I am here presenting, it is
essential that every method object have an instance of the MethodObjectHelper class. The helper instance is inserted via composition, using this code
(please copy and paste):
protected readonly MethodObjectHelper _methodObjectHelper = new MethodObjectHelper();
The most significant "why?" question likely to arise when considering that line of code is, "Why does the field have protected access?" The answer is that method
object classes can be base classes (inherited or derived from) and every method object instance requires exactly one MethodObjectHelper instance.
Step Five: The method object must have an explicit default constructor. Here again, I will ask you to copy and paste:
protected MethodObject()
{
}
Of course, please replace the instances of "MethodObject" with the name of your class, which I hope is very descriptive. As guidance on naming your
class, consider this example: If the method you are
replacing was named, or would have been named, Gonkulate, your method object class should be named Gonkulator. :)
Step Six: Use a method that extracts the name of a property from an expression that accesses the property to provide a complete set of property names as
public static readonly strings. Here is an example:
public static readonly string NameOfName = MemberInfoHelper.GetMemberName(() => Instance.Name);
The names of all of the parameter and result properties that you have defined should be provided in a similar manner.
In executing this step, you will also need to have a static instance of your class available for the property name extractor method to work with. Here's the code for
that instantiation (please copy and paste, then replace the class name):
private static readonly MethodObject Instance = new MethodObject();
Step Seven: The time has come to write the special method that provides public access to the functionality of the method object class. I suggest creating two overloads
which use different types of data transfer objects to help with input and output, as well as to enforce the requirements that were expressed via attributes when the
the parameter and result properties were developed. I prefer the name Invoke for this method; you could also call it something else if you prefer - but please be
consistent. :)
The overloads of Invoke (by whatever name) are short boilerplate-ish methods that call the Activate method in the helper object, which does
all of the interesting and useful infrastructure tasks, like validating the data transfer objects, initializing parameters, binding output data (ref and out parameters,
essentially) to the calling context, and invoking the single entry point method that is provided by the method object - which a future step deals with; don't worry
about it now.
I will provide the code for both overloads here (with most intra-code comments removed, for brevity) so that you can compare and contrast them. The only aspect in which
your implementation should vary from the code given here is in the parameter value defaulting code that follows the verification that the first argument isn't null.
public static string Invoke(
Dictionary<string, object> parameterValueByName,
Action<Dictionary<string, object>> bindResultValueByName = null)
{
if (parameterValueByName == null)
{
throw new ArgumentNullException(MethodObjectHelper.ParameterInitializer);
}
if (!parameterValueByName.ContainsKey(NameOfTimestamp))
{
parameterValueByName.Add(NameOfTimestamp, DateTime.Now);
}
var instance = new MethodObject();
instance._methodObjectHelper.Activate(instance, parameterValueByName, bindResultValueByName);
return instance.Result;
}
public static string Invoke(
dynamic parameterPackage,
Action<dynamic> bindResultPackage = null)
{
if (parameterPackage == null)
{
throw new ArgumentNullException(MethodObjectHelper.ParameterInitializer);
}
if (!DynamicHelper.ContainsProperty(parameterPackage, NameOfTimestamp))
{
parameterPackage = DynamicHelper.SetPropertyValue(parameterPackage, NameOfTimestamp, DateTime.Now);
}
var instance = new MethodObject();
instance._methodObjectHelper.Activate(instance, parameterPackage, bindResultPackage);
return instance.Result;
}
There is a rationale for providing both overloads, with their characteristic data transfer object types. Briefly: It is safer to use
Dictionary<string, object> objects but more convenient (and readable) to use anonymous, dynamic objects. Please compare these
short examples, which display the two techniques:
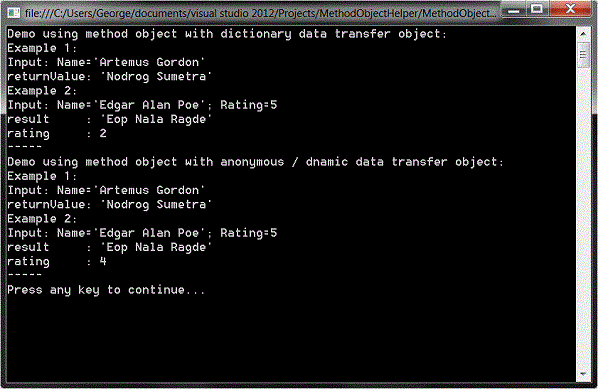
var returnValue = MethodObject.Invoke(
new Dictionary<string, object>
{
{ MethodObject.NameOfName, "Artemus Gordon" },
{ MethodObject.NameOfRating, 0 }
});
var returnValue = MethodObject.Invoke(
new
{
Name = "Artemus Gordon",
Rating = 0
});
The practical difference is that in the first case, if you make a mistake in typing the dictionary key / parameter property name, Visual Studio will immediately notify
you; but when defining an anonymous object, you can give the properties any names you like and Visual Studio cannot verify that they match anything in particular, or
that they conform to any restrictions other than those imposed on property names by the C# language specification. Taking this and the relative amount of typing that one
option requires in comparison to the other into account, a decision can be be made whether to support one usage or the other, or both. Thus, either one or both of the Invoke
method overloads should be included, depending on your decision - or whether you elect to defer the decision, in which case I recommend supporting both variants
in the interim.
Notice that (mainly for the sake of brevity) the above examples omit results-binding action parameters.
Doesn't providing both Invoke overloads and supporting both data transfer object types encourage inconsistency? Perhaps, but would it necessarily be a harmful
inconsistency? And it's worth noting that code written to use one approach can be easily modified to use the other; for example, the process of modifying code that
uses the dictionary to use the anonymous object instead involves mainly the use of the Delete and/or Backspace keys. So, "first draft" code can easily be written
using the safer dictionary-based approach and "cleaned up" later to use the more readable anonymously-typed-object-based approach.
The MethodObjectHelper.Activate method performs run-time validations that will quickly, pro-actively and decisively inform
the developer (or, depending on whether or how exceptions are handled, possibly application users) of any errors that were made in setting up and using the method object
class - in general, any harmful deviation from the rules and procedures articulated in this article. It's too bad that Visual Studio and the compiler can't currently do
this checking, but the comprehensive validations performed by the helper class are the next-best thing.
(Some readers may not know that dynamic objects in .NET are really just thinly-wrapped Dictionary<string, object> instances. That fact and
some of its ramifications come to the fore when developing and testing code like this - which would be interesting to explain at length but, sadly, not directly relevant
to this article. The DynamicHelper class provided with the downloaded code may be of some interest to readers.)
Earlier, I committed to pointing out where the defaulting of parameters to values that can't be assigned to the ParameterProperty attribute's
DefaultValue property should be done. Just in case you missed it: There is an example of that above, where in both Invoke overloads the code
arranges to default the Timestamp property to DateTime.Now.
Notice the very brief and private (local to the Invoke method) existence of the MethodObject instance. It is not intended, in normal situations,
to be exposed to external code. In unusual situations, however, it might be necessary to return most or all of the object's properties as result data - in which case, the
instance itself could simply be returned by the Invoke method. It's possible to control access to the object's features so that no methods and no property
set accessors are publicly exposed, which is the convention that's followed in the examples in this article and the accompanying downloadable code, and that I tend to
recommend. The object can thus behave strictly as a (read-only) data transfer object from the perspective, and for the purposes, of external code.
As a final note on this step, I will briefly discuss results-binding actions. They're just delegates that are intended to take the values of any ref /
out parameter analogs (result properties), which are automatically packaged up for export by the helper class's Activate method after the
method object's code has been invoked (that action to be shortly discussed below), and copy those values into variables in the calling context, after optionally doing any
necessary / appropriate computing on them. Unlike in an actual method call, where this is done (minus optional computing) automatically, when using a MOH-assisted
method object, a little bit of explicit code must be supplied to do the job. It's a small price to pay, and it isn't needed in all circumstances; in fact, like the use
of ref and out parameters with method calls, it can be "religiously" avoided, if that's your preference.
Step Eight: The MethodObjectHelper class's Activate method is very powerful, but it requires you to make one change, at this point,
to the implementation of your parameter and result properties. (Recall that we left those as simple as possible, earlier; it is now time to expand and complete the
coding of the accessor bodies.) It is required that those properties use a dictionary in the MethodObjectHelper class as their backing store, and a couple
of methods, GetValue and SetValue, are provided to facilitate this. Below is an example of the fully-fleshed-out code for one property -
showing that arbitrary code can be included in the property accessors, as usual; but where ordinarily one might use a class field as a backing store, GetValue
and SetValue are used instead.
[ParameterProperty(false, DefaultValue = 3)]
[ResultProperty]
public int Rating
{
get { return (int)_methodObjectHelper.GetValue(NameOfRating); }
protected set
{
var adjustedValue = Math.Min(Math.Max(value, 1), 5);
_methodObjectHelper.SetValue(NameOfRating, adjustedValue);
}
}
In the example, Rating is used as a ref method parameter analog, in that it is used for both input to and output from the method object,
so it makes sense
that it should have a set accessor. Method code (yet to be written / discussed) within a method object instance may, or will, need to modify whatever
initial value Rating was given in its role as a parameter, or its default value, 3.
Set accessors need to be public or protected unless you want to seal the class, thus preventing inheritance. I think it is
wisest to observe
the convention of making them protected. This way, if an instance of the method object class is ever returned from an invocation - which is certainly
possible - it will be read-only to external code.
If the method object class ends up with additional properties that are not parameter or result properties (aren't decorated with the ParameterProperty and/or
ResultProperty attribute(s)), they may, but are not required to, use the MOH's dictionary as a backing store; using it is a requirement only for parameter and
result properties.
Step Nine is the one in which we finally supply action to the software "machine" that we have so painstakingly constructed. This is the step in which the
writing of the method code begins. I can't predict or prescribe what the method code will or should look like; it will necessarily vary widely and wildly from one
implementation to the next. However, it is possible to state, or define, that there will be exactly one instance method that will be automatically invoked by the helper
object's Activate method, and (as with a program's Main method) all other code within the method object that executes between the binding of
imported values to parameter properties and the bundling of result property values for export must be run by that single automatically-invoked instance method.
An attribute is used to tell Activate which method to invoke. Here is an example:
[InvokeOnActivation]
protected void Compute()
{
}
I have called the entry-point method Compute. (Obviously, if you choose to rename the method I have called Invoke to Compute,
you'll have to pick a different name for this method.) The name is functionally irrelevant; it's the InvokeOnActivation attribute that enables
Activate to identify and invoke the method.
Further restrictions are that the method must return void and take no parameters. This makes perfect sense, given that the parameter properties of the
method object are
effectively this method's parameters and that its main job is to compute and set the values of the result properties. The Invoke method can return the
principal return
value (stored in a result property named, according to convention, Result or ReturnValue), and if there are other exports, analogous to
ref and out parameters, those are made available - along with the method object's principal return value - to the results-binding delegate that
the calling code optionally passes to Invoke. Of course, it is also possible that no values will need to be returned, in which case the Invoke
method should return void, provide no results-binding action parameter and pass none to the Activate method. (All of the variations available
via a normal method call are easily and handily covered.)
For emphasis: It doesn't matter whether Invoke returns void or a value of some type, and it doesn't matter whether it has a required
results-binding delegate parameter, an optional results-binding delegate parameter, or no such parameter; those details must be determined by the needs of the
particular implementation.
Is there a Step Ten? Yes, there is. This is the step in which the original code gets carefully and lovingly refactored within the confines of the method object
class. Although it requires very little explanation within this article, it is perhaps the most important step, the one that all of the other explanation and the related
code serves to facilitate. The technique under discussion is all about freeing that code from problematic tight and complex coupling with its context so that it will be
much easier to manipulate it into whatever form is best for the long-term benefit and well-being of the application.
At this step, you will also need to modify the original contextual code to invoke the method object instead of whatever it was doing before (calling a method with
a large number of parameters?), of course.
Step Eleven requires you to test your code, debug it if necessary, and ultimately ensure that it works as you intend.
Conclusion
Here is a quick summary of the refactoring steps in outline form:
- Construct the signature of a completely independent method; or if you're working with an existing method, modify its signature as needed to ensure its complete
independence.
- Construct a class having a property corresponding to each parameter of the method signature created in step 1 and the return value, if any. (By convention, name
the property that represents the return value
Result or ReturnValue.) - Decorate the properties with attributes.
- Properties corresponding to
in parameters must be decorated with the ParameterProperty attribute.
- The required parameter is
mustBeInitialized, which expresses whether the invoking code must provide an initial value for the parameter. - The property
DefaultValue should be set if mustbeInitialized = false was specified. - If there is a need to use a default value that can't be assigned to
DefaultValue, set DefaultValueSetInCode = true and plan
to set the default value in code, later on.
- Properties corresponding to
out parameters and the original method signature's return value (if any) must be decorated with the
ResultProperty attribute. - Properties corresponding to
ref parameters must be decorated with both the ParameterProperty attribute and the
ResultProperty attribute, as described above.
- Declare and initialize a protected read-only field that contains a
MethodObjectHelper instance. - Define an empty default constructor for the method object class that has
protected access. - Provide the name of each property as a static readonly string. (See the article and example code for how-to recommendations.)
- Provide one or two overload(s) of the public static
Invoke method, following the examples and detailed discussion given above. The Invoke
method (which you can rename if you prefer) must:
- Ensure that the parameter-initializer parameter is not null. [Required.]
- Take care of any necessary intra-code assignment of default values to parameter properties. [Optional.]
- Create a method object instance and pass it, along with the parameter-initializer object and the results-binding action parameter, if used, to the method
object helper instance's
Activate method. [Required.] - Return the value of the
Result / ReturnValue property, if appropriate. [Optional.]
- Ensure that all parameter and result properties use the method object helper instance's internal dictionary as a backing store, accessing it via the
GetValue and SetValue methods. - Create one protected void method that takes no parameters and decorate it with the
InvokeOnActivation attribute. This method is the entry point for
all computing to be done by the method object. (Consider naming this method Compute by convention.) The method must ensure that values are assigned
to all result properties. - Refactor the original code to either be contained in, or be called by, the entry point method defined in the previous step. Modify contextual code to invoke the
method object.
- Test your code and ensure that it works correctly.
If you have a need to execute the "replace method with method object" refactoring strategy, please consider using the code and process introduced in this article as
an aid to creating a successful outcome with relative ease, using a thoroughly standardized but very flexible approach.
Is the MOH-assisted approach to replacing methods with method objects a wondrous boon or a @#$% exercise in over-engineering? You decide.

