The source code has been updated, to download the new version, please go here. Thanks!
1. Introduction
In this article, I am going to introduce a novel algorithm for frequent subtree mining problems as well as basic concepts of this field. The algorithm, called CCTreeMiner, was first proposed in my master’s thesis (written in Chinese and my tutor was LiuLi) in 2009 and it is able to mine frequent, closed or maximal of ordered or unordered induced subtree patterns against transactional, occurrence or hybrid based threshold types. The major contributions are: first, a root occurrence match which holds Apriori property is introduced for occurrence based support counting; Secondly, a necessary and sufficient condition is found for both closed and maximal tree patterns.
2. Who is Audience?
It is better for the readers of this article to have some basic ideas about subtree mining problem, at least be comfortable with concepts like tree structure, subtree, closed-subtree, maximal-subtree, support, preorder-representation, ordered tree and etc.
I am trying my best to make this article as easy to read as possible, but subtree mining is probably not an very easy problem on itself and English is not my native language. So, I am sorry for any would-be frustrations:)
3. Background
3.1 Related Definitions
Here are some important concepts related to this article. Be aware, they are informal but reminders for those who have background or a quick start for those who have not.
Tree: A tree is an acyclic connected graph, it is made of a set of nodes (or vertices) connected by edges. There are basically two kinds of them namely rooted tree and free tree. A rooted tree is well formed, that is, it contains one unique node called root which has no parent. This article is focus on rooted tree. For a free tree to be converted to a (unique) root tree, see Ruckert et al. [4], Nijssen et al. [3], and Chi et al. [1, 2] .
Parent-child relationship: A node p is said to be the parent of a node c if there is an edge starts from p and points to c.
Sibling: A parent may have zero to many children and the set of children of the same parent are siblings.
Fanout: A node’s fanout (or degree) is the number of its children.
Leaf: A node without any child is called a leaf. Obviously, a leaf is zero degree.
Path: A path between two nodes is the set of edges that make them connected. As a tree contains no cycle, this path is unique.
Ancestor-descendant relationship: The ancestors of a node are the nodes (not include itself) on the path starts at the root and down to that node while the descendants of a node are those that take it as ancestor.
Tree Size: The size of a tree is the number of nodes it contains.
Tree Depth: The depth of a tree is the number of edges on the longest path starting at root.
Depth of Node: The depth of a node is the number of edges between the root and this node.
Ordered and Right-Most: A tree is ordered if there is a predefined ordering among every set of siblings, that is, each child of a parent in the tree has a predefined position against its siblings and we say the one positioned at the rightmost the rightmost child of its parent. On the contrary as for an unordered tree, the positions of siblings simply do not matter.
Right-Most Path: In an ordered tree, a node’s rightmost path (if it is not a leaf) is the path directing to its rightmost child and the leaf of this rightmost path is called the rightmost leaf of the node.
Rightmost Leaf: As for the tree, its rightmost leaf is defined as the rightmost leaf of its root.
Preorder String Representation for Trees (see Luccio et al. [9, 10]): This representation maps a tree to a unique encoding string. The rule is, following a preorder traversal and records each node of a tree while traversing forwardly and marks every edge while backtracking.

Canonical Representation of Unordered Tree: For an unordered tree to be preorder represented: the positions among any siblings could be different and as a result, the same set of siblings with different positions among them could produce dissimilar preorder string representations for the same unordered tree. To deal with this, we need to select one unique representation to denote an unordered tree. For example, we may use the lexicographically largest/smallest preorder string to represent an unordered tree. This formalized representation is called canonical form (see Chi et al. [1]).
3.2 Frequent Subtree Mining - the Problems
3.2.1 The mining objects: Frequent, closed or maximal
The problem of frequent subtree mining can be generally stated as: given a tree (also known as transaction) database Tdb and a set of constraints (usually minimum times of appearances), return a set F that contains all subtree patterns in Tdb that satisfy these constraints. The widely applied constraint is frequency, following is the definition.
Frequent: The support (discussed next) of a subtree is a value against a given constraint. We say a subtree pattern is frequent if its support satisfies the constraints.
There are problems (see Chi et al. [11]) about frequent subtree mining tasks, so instead of mining frequent subtrees, the following are sometimes applied.
Closed: A frequent subtree is closed if none of its super trees has the same support as it has.
Maximal: A frequent subtree is maximal if none of its super trees is frequent.
To make a distinction between a tree (transaction) in Tdb and a frequent subtree in F (they are all trees), we call a transaction as a Text Tree Pattern (short for text tree or text pattern) and a frequent subtree as Frequent Tree Pattern (frequent pattern). We denote a pattern as n-pattern if its tree size is n.
3.2.2 Types of Subtrees
Different types of subtrees should be explained before continue and generally speaking, there are three of them:
Bottom-up subtree (see Valiente [5]):
If Ts is of this kind of subtree of T, then:
1. The root Rts of Ts must be a node Nt of T;
2. If Nt has a descendant in T, Rts will have the same one in Ts and no more no less.
3. Finally, every parent-child relationship among Nt’s descendants is also kept in the descendants of Rts in Ts.
Induced subtree (see Chi [6]):
If Ts is of this kind of subtree of T, then:
1. The root Rts of Ts must be a node Nt of T;
2. If there is a parent-child relationship among two descendants of Rts in Ts, the same relationship among two descendants of Nt must be found in T.
Embedded subtree:
If Ts is of this kind of subtree of T, then:
1. The root Rts of Ts must be a node Nt of T;
2. If there is a ancestor-descendant relationship among two descendants of Rts in Ts, the same relationship among two descendants of Nt must be found in T.
Base on their definitions, it’s not difficult to understand that there is a partially ordered relationship among
them: A bottom-up subtree implies that it is also an induced subtree while an induced subtree implies that
it is also an embedded subtree but the opposites may not be true.
3.2.3 Support Defination
Generally speaking, there are three of them:
Transaction Based Support: This support type provides a transactional level threshold s and requires that a subtree is frequent iff it appears at least in s different transactions in the given database.
Occurrence Based Support: In this case, the threshold is the number of occurrences of a subtree in the given database.
Hybrid Support: This support type is a combination of the above two: a subtree pattern is frequent iff it meets a transactional based threshold as well as an occurrence based threshold.
3.2.4 Troubles of Occurrence Based Support
Based on the downward-closure lemma (also known as Apriori property, see Agrawal & Srikant [7]), every sub-pattern of a frequent pattern is also frequent. However, this does not hold in subtree patterns.
1. Apriori property is not hold.
In the following example, pattern A^ has only one occurrence, but its supper-pattern AB^^ has 3 occurrences: [0, 1], [0, 1] and [0, 3]; its super-pattern AB^B^^ also has 3 occurrences: [0, 1, 2], [0, 1, 3] and [0, 2, 3]. Thus, Apriori is broken which states a pattern’s support should be larger than or equal to any of its super patterns.
One of the major problems about subtree mining is combinatorial explosion of the number of possible candidate subtree patterns and we have to find smart ways (pretty much all about pruning) to reduce the enumeration space.
Obviously, the problem would be much bigger if Apriori (anti-monotone) property failed which means we cannot use it to prune.
2. The counting problem with occurrence.
It’s not difficult to see that the number of super-patterns in this case is of factorial complexity. As a rule of thumb, you have to think carefully about feasibility if the complexity of an algorithm is larger than O (10!).
3.2.5 Root Match Occurrence
Definition: Any two occurrences of pattern P in tree T should not have the same root and for those that do have, one and only one of them can have contribution to root occurrence based support. Follow this restriction; the downward-closure lemma shall be kept.
So far, on the basis of my limited knowledge and information, I don’t know anyone else has already defined such a rule of counting for occurrence-based support. So for now, I shall describe it as a contribution of my work in this article.
In the following, when we say occurrence, we are referring root-based occurrence.
4. CCTreeMiner
CC stands for connection & combination.
4.1 Mechanisms
CCTreeMiner is inspired by the following observations:
1. Any rooted tree pattern whose root has a fanout of n can be divided into n different subtree patterns and each one has the identical root with fanout of 1.
2. Every one of such divided sub patterns, if larger than 2, can be further divided into two sub patterns: a 2-pattern rooted at the same root with its only child as leaf and a subtree pattern rooted at that single child.
3. Recursively repeat step 1 and 2 and eventually, in a top-down manner, the original pattern shall be decomposed to a set of 2-patterns.
Follow the opposite operations, any tree pattern larger than or equal to 2 can be built with a set of 2-patterns in a bottom-up manner. This is the main idea behind CCTreeMiner. Here are some definitions used by the algorithm.
Given a tree database Tdb and a restriction of threshold:
F: The set of frequent subtree patterns.
Fn: The set of frequent n-patterns.
F2Di: The set of frequent 2-patterns and each of them has at least one occurrence at depth i.
FDi: The set of frequent patterns and each of them has at least one occurrence at depth i.
RDi: The set of frequent patterns and each of them has at least one occurrence at depth i and the fanout of its root is 1.
In the following, when we say a pattern at depth i we mean that this pattern has at least one occurrence at i which further means that the depth of the root of this occurrence is i.
4.2 Pseudo Code
4.3 Supper Pattern Extension
In CCTreeMiner, there are two ways to extend a super pattern, combination and connection.
4.3.1 Combination
Given an n-pattern Px and a m-pattern Py which share the same root, then a new pattern Pxy of size n + m – 1 can be generated by combining the roots of Px and Py.
The material to be prepared before doing Combination at depth i is RDi, it serves as a collection of seeds from which all frequent patterns that have any occurrence at i are to be generated. The strategy of enumeration is depth-first: A frequent pattern is to be extended further until all its newly found super patterns have been fully extended. In other word, if a new frequent pattern f is discovered then f is to be combined to form possible new patterns with each item in RDi.
I am not going to formally prove it here but: first, any pattern larger than 2 at i is a combination, by root, of some patterns from RDi, which means it can be generated by a depth traversal of RDi; secondly, pruning of infrequent patterns, which means stop further iteration of traversal at any infrequent pattern and prevent infinite traversal; thirdly, if a pattern at i is infrequent, all its supper patterns at i are also infrequent, so pruning it won’t make us losing any frequent pattern. As a result, combination at depth i can generate all frequent patterns that have at least one occurrence at i and all frequent subtree patterns can be generated by CCTreeMiner.
4.3.2 Connection
Given a 2-pattern P2 with leaf l and an n-pattern P which roots at l, then a new (n + 1)-pattern Pnew can be generated by connecting the leaf of P2 and the root of P.
The materials to be prepared for Connection are F2Di and FDi+1. The connection method enumerates each frequent 2-pattern in F2Di against frequent patterns in FDi+1 to generate every possible supper patterns and calculates their support. As a matter of fact, with all frequent 2-patterns at depth i and all frequent patterns at depth i+1, an enumeration between the two set will produce RDi, the input for the next round of iteration for combination.
Lemma 1: A frequent pattern P is closed iff there is at least one occurrence that has no match of any other pattern.
Lemma 1 is obvious; it’s actually the definition of closed subtree. The problem is how to meet this condition in algorithm. Here is how:
Lemma 1.1: After connection at depth i, for a pattern T, if there is no occurrence match of T and there is occurrence(s) of T at depth i + 1, then T is closed.
Lemma 1.2: After connection at depth i, for a closed pattern M, if the number of its occurrences above i (i is not included) is smaller than support threshold, then M is maximal.
Recursively following combination and connection in a bottom-up manner, if a frequent pattern has any supper-pattern which is an occurrence-match or not but frequent, it should have been found in the previous combination or connection steps, and if not, the pattern should be closed or maximal respectively (I have proved this in my thesis in Chinese and I hope there was no mistakes). If closed or maximal are the subjects, lemma 1.1 and 1.2 are used in CCTreeMiner.
4.4 Prune
4.4.1 Prune for frequent subtree mining tasks
As have been discussed, Tdb is scanned in a bottom-up manner starting from the second deepest depth up to 0 and during which, any un-extended pattern shall be generated and tested for frequency if and only if its first (the deepest one) occurrence is found. While the algorithm is running, the occurrences of any pattern generated fall into two sets distinguished by the value of CurrentDepth, the ones above or equal to it and those not. The latter (set of occurrences deeper than CurrentDepth) will not be considered in generating any new supper patterns (new means that it does not have any occurrence below CurrentDepth, otherwise it should have been generated and thus, should not be described as new) since following the depth-first enumeration in Combination steps, all of them shall have been generated already. So, for any new pattern to be generated, its upper-bound of support is determined by the size of the former set (the number of occurrences above or equal to CurrentDepth) which size is named as RemainingSupport. Further more, when CurrentDepth is given and for any frequent pattern, if its remaining support is smaller than threshold, then it can be pruned.
4.4.2 Prune for closed and/or maximal subtree mining tasks
A frequent pattern cannot be extended to generate any closed supper pattern if it has occurrence-match. This strategy is used to prune when closed or maximal is the case.
5. Experiments
None so far. I am not a full time researcher and I use my spare time to think and code CCTreeMiner. I haven’t been able to compare CCTreeMiner with other algorithms because it takes lot of time to learn them and study the code.
Any way, a forest (Tdb) generator is provided and you can get your experiments. I would appreciate if you could be kind enough to show me your results if any. I’ll be talking about forest generator and how to use the code for a while.
6. Conclusions
This article tries to explain mechanisms about CCTreeMiner, a methodology dealing with subtree mining problems. It first introduced related concepts of this field and then unique materials of CCTreeMiner. It explained basic ideas, enumeration methodology, and pruning strategy. It discussed sufficient and necessary conditions for both closed and maximal subtrees and how to apply them. Further more a root-based occurrence is introduced which makes occurrence-based support counting feasible.
6.1 Other benefits
There are other benefits of the algorithm:
First, CCTreeMiner scans Tdb once and once only and it’s not necessary to load the whole database into memory.
Secondly, for any pattern to be generated for support testing, it must have at least one occurrence in Tdb.
Thirdly, for each round of iteration, the increase of new pattern is NOT bound by 1 as most other approaches.
Finally, CCTreeMiner is not a specific algorithm that solves a particular subtree mining problem, but a framework. Despite induced subtree (the focus of this article), it can (at least I am quite curtain now) also mine bottom-up and embedded subtree types as well. And all of the three types can be against frequent, closed or maximal of ordered or unordered subtree patterns of transactional, occurrence (root based) or hybrid based threshold types. The possibility of mining bottom-up and embedded subtree will be discussed in the next section.
7 What to do next?
As I have mentioned, CCTreeMiner is a framework. But it would be weak to pronounce it if it could only deal with induced subtrees. In this section, I will be discussing feasibilities of mining bottom-up and embedded subtree types.
7.1 Bottom-up subtree
An occurrence is bottom-up iff the number of indexes of its preorder representation is equal to the number of descendants of its root in its text tree. For a bottom-up subtree pattern, all of its occurrences should be bottom-up. It is not so hard to apply these checks based on mechanism of CCTreeMiner. As a bottom-up tree is an induced tree, their pruning strategies are the same.
7.2 Embedded subtree
In case of embedded subtree type, the downward-closure lemma is also workable for root occurrence match. As for combination, the role is just the same. But for connection, the original parent-child relationship should be extended to ancestor-descendant one: the leaf of an occurrence of a frequent 2-pattern can be connected to any of its descendants. To know if a node is a descendant, we might use scope (for details, see Zaki [8]).
So, next I shall try to refactor the code and add bottom-up and embedded to the toolbox.
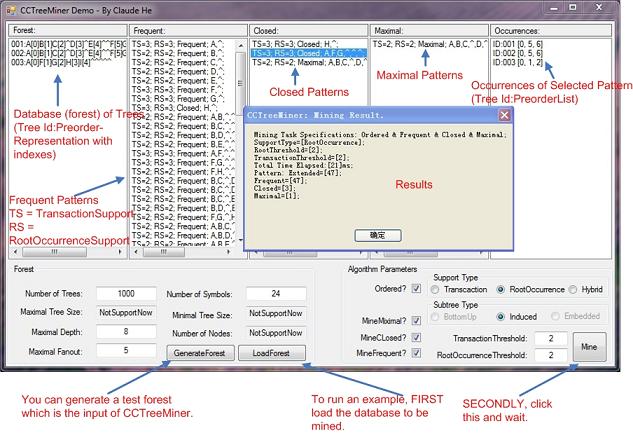
8. Using the code
The input of CCTreeMiner has two parts: a set of parameters and a tree database.
The parameters needed include subtree-type, support-type, ordering, and thresholds. I have encapsulated these parameters into a class and I don’t believe there would be many problems using it but definitely, you should understand their meanings beforehand.
The input database is a collection of text trees (or transactions) that should be in their correct preorder representation as CCTreeMiner requires. Your transaction class and node class should implement ITextTree interface and ITreeNode interface respectively.
public interface ITreeNode : IComparable<ITreeNode>
{
}
public interface ITextTree
{
}
I have written a demonstration which shows you how to do it. In this demo, my instances of transactions are converted from text file while each line is a preorder string representation for a text tree and each node is simply a letter. However, if your domain problems are more complicated than letters, then you will have to develop your own convertor as nothing can be done (without a crystal ball) to predict your specific domain problems. To make it more clear, the convertor should be able to build correct preorder relationships among each node of your transaction.
public class MyTree : ITextTree
{
}
public class MyTreeNode : ITreeNode
{
}
Using the code is easy:
List<ITextTree> myForest = new List<ITextTree>();
CCTreeMiner ccTreeMiner = new CCTreeMiner();
MiningParams param = new MiningParams();
ccTreeMiner.Mine(myForest, param);
References
[1] Chi, Y., Yang, Y., Muntz, R. R.: Mining Frequent Rooted Trees and Free Trees Using Canonical Forms, UCLA Computer Science Department Technical Report CSD-TR No. 030043.
[2] Chi, Y., Yang, Y., Muntz, R. R.: HybridTreeMiner: An Efficient Algorithm for Mining Frequent Rooted Trees and Free Trees Using Canonical Forms, The 16th International Conference on Scientific and Statistical Database Management (SSDBM'04), June 2004.
[3] Nijssen, S., Kok, J. N.: A Quickstart in Frequent Structure Mining Can Make a Difference, Proc. of the 2004 Int. Conf. Knowledge Discovery and Data Mining (SIGKDD'04), August 2004.
[4] Ruckert, U., Kramer, S.: Frequent Free Tree Discovery in Graph Data, Special Track on Data Mining, ACM Symposium on Applied Computing (SAC'04), 2004.
[5] Valiente, G.: Algorithms on Trees and Graphs, Springer, 2002.
[6] Chi, Y., S. Nijssen, R. R. Muntz, J. N. Kok / Frequent Subtree Mining- An Overview.
[7] Agrawal, R., Srikant, R.: Mining sequential patterns. Paper presented at the Proceedings of the 11th International Conference on Data Engineering, Taipei, Taiwan, March 6-10 (1995)
[8] Zaki, M. J.: Efficiently Mining Frequent Trees in a Forest, Proc. of the 2002 Int. Conf. Knowledge Discovery and Data Mining (SIGKDD'02), July 2002.
[9] Luccio, F., Enriquez, A. M., Rieumont, P. O., Pagli, L.: Exact Rooted Subtree Matching in Sublinear Time, Technical Report TR-01-14, University Di Pisa, 2001.
[10] Luccio, F., Enriquez, A. M., Rieumont, P. O., Pagli, L.: Bottom-up Subtree Isomorphism for Unordered Labeled Trees, Technical Report TR-04-13, University Di Pisa, 2004.
[11] Chi, Y., Yang, Y., Xia, Y., Muntz, R. R.: CMTreeMiner: Mining Both Closed and Maximal Frequent Subtrees, The Eighth Pacific Asia Conference on Knowledge Discovery and Data Mining (PAKDD'04), May 2004.
History
1. First published: Apr. 9. 2014.

