In this article, I will be presenting and explaining an Open XML SDK Library based ExcelReader class for importing Excel data to a generic list through the object model mapping.
Introduction
The generic list with an underlying data model is the most favorable collection structure used for the data application development due to its true object oriented programming nature. It's also the best form for importing data from the Microsoft Excel spreadsheet to applications and databases. This article and sample application shows a C# class that populates a generic list with the data retrieved from the Excel data file. The article especially addresses these topics:
- Using Microsoft Open XML SDK library and merge DLL files to the main assembly. No Office Interop or other third party tool is needed.
- Obtaining data values from the Excel Workbook shared string table.
- Handling the empty spreadsheet cell issue during row iterations.
- Detecting used range to eliminate the empty row processing.
- Mapping spreadsheet data to object model with friendly column names instead of index numbers.
- Standardizing the string to primitive data type conversions.
Running Sample Application
The downloaded source contains everything for running the sample application with the Visual Studio 2010 - 2013. An Excel file is included in the downloaded source with the sample data shown below:
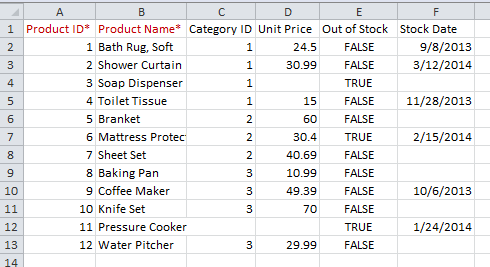
Here is the corresponding plain object model for the sample data:
public class Product
{
public int ProductID { get; set; }
public string ProductName { get; set; }
public int? CategoryID { get; set; }
public Decimal? UnitPrice { get; set; }
public bool OutOfStock { get; set; }
public DateTime? StockDate { get; set; }
}
To see the data import in action, you can run the sample application in debug or release mode. The imported data results can be shown as a formatted string on a console window or in another Excel worksheet window using the GenericListOutput class that is included in the sample application.
Overview of Data Import Function
The GetDataToList function in the ExcelReader.cs class file performs the major tasks of importing data from an Excel file to a generic list using the syntax:
public IList<T> GetDataToList<T>(string filePath,
Func<IList<string>, IList<string>, T> dataMappingFunctionName);
public IList<T> GetDataToList<T>(string filePath, string sheetName,
Func<IList<string>, IList<string>, T> dataMappingFunctionName);
The function is designed to import data from a single sheet to a single generic list at a time. The first overloaded version always takes the first worksheet in the Excel file. If you have multiple sheets, you can call the second overloaded version with explicit sheetName values multiple times to create corresponding multiple List objects for your models.
The dataMappingFunctionName points to a function that conducts the mapping of spreadsheet field data to object model under the hood. We will be discussing the data mapping details later.
As demonstrated in the sample application, to import data from the Excel file to the List with the Product model, just call this line of code by passing the file path (excelPath) and the name of the delegated data mapping function (AddProductData):
IList<Product> dataList = ExcelReader.GetDataToList(excelPath, AddProductData);
Using Open XML SDK Library
If we develop a server application that needs to import the data from an Excel file, it's not a good practice to use the Office InterOp library for Excel. Third party tools, such as Aspose, function well but have the licence limit and may be an overkill if used just for reading the data from the Excel. Although the Open XML SDK for Office is not so developer-friendly, it's a standardized and mature tool from the Microsoft development network family. Using the tool could be an excellent choice for the Excel related .NET programming work if we can well handle some hassles.
Two Open XML SDK Library assemblies, DocumentFormat.OpenXml.dll and WindowsBase.dll, are needed for obtaining the Excel data. The sample application includes two files with the Open XML SDK version 2.5 in the lib folder. These files are working fine for Excel 2007 - 2013 spreadsheet files and Visual Studio 2010 - 2013 projects with .NET Framework 4.0 and above. If you use .NET Framework versions below 4.0, you can download and install the Open XML SDK version 2.0, replace the two DLL files with the version 2.0 files, and then re-reference them in the project.
An automatic assembly merge process can be used in some situations requiring one consolidated executable or DLL file for easy deployment as shown in the sample application.
-
Setting two DLL files as resource files on the Resources tab of the project Properties page. This will create the Resources.* file group under the project's Properties folder.
-
Adding the following event handler routine code into the startup class:
System.Reflection.Assembly CurrentDomain_AssemblyResolve
(object sender, ResolveEventArgs args)
{
string dllName = args.Name.Contains(',') ?
args.Name.Substring(0, args.Name.IndexOf(',')) : args.Name.Replace(".dll", "");
dllName = dllName.Replace(".", "_");
if (dllName.EndsWith("_resources")) return null;
var obj = new Object();
System.Resources.ResourceManager rm = new System.Resources.ResourceManager
(obj.GetType().Namespace + ".Properties.Resources",
System.Reflection.Assembly.GetExecutingAssembly());
byte[] bytes = (byte[])rm.GetObject(dllName);
return System.Reflection.Assembly.Load(bytes);
}
-
Raising the event in the initiating routine or constractor of the startup class:
AppDomain.CurrentDomain.AssemblyResolve +=
new ResolveEventHandler(CurrentDomain_AssemblyResolve);
Getting Cell Values from Shared String Table
The Excel stores potentially repeated string data values in the shared string table XML structure in a workbook for the performance improvement purpose. The worksheet cells are assigned index numbers that point to the shared string table node values. You don't have to care how to get real data values from worksheet cells if working with the Office InterOp. But when using the Open XML SDK Library, you need to check the cell data type attributes and obtain the data items from the shared string table through index numbers stored in cells.
The GetCellValue function in the ExcelReader class checks that if the value of the DataType property for a cell object is SharedString, then the real data item will be retrieved from the SharedStringTable object. The below code snippet shows the logic:
if (cell == null) return null;
string value = cell.InnerText;
if (cell.DataType != null)
{
switch (cell.DataType.Value)
{
case CellValues.SharedString:
var sstPart =
document.WorkbookPart.GetPartsOfType<SharedStringTablePart>().FirstOrDefault();
value = sstPart.SharedStringTable.ChildElements[Int32.Parse(value)].InnerText;
break;
}
}
return value;
Adding Empty Cells into Spreadsheet Rows
When getting a data row from the object with the DocumentFormat.OpenXml.Spreadsheet.Row type, any cell with empty value is not included due to the underlying XML node structures. This causes a major issue on iterating cells for the column mapping in rows. The Open XML SDK library does not provide any solution for the issue. Consumers need to add their own code to handle it. Fortunately, the DocumentFormat.OpenXml.Spreadsheet.Cell class has the CellReference property that can be used to match the built-in column names and thus facilitates inserting empty cells at the missing positions.
To easily detect missing cells, all built-in column names are firstly cached to a generic list during the iteration for the custom header row. The GetColumnAddress called in the loop is a simple function to return letter part of the Cell.CellReference value (See downloaded source for details).
var columnLetters = new List<string>();
foreach (Cell cell in wsPart.Worksheet.Descendants<Row>().ElementAt(0))
{
columnLetters.Add(GetColumnAddress(cell.CellReference));
}
The GetCellsForRow function in the ExcelReader class will then add empty cells at positions where they are missing in a spreadsheet row and return an enumerable containing the complete number of cells. Note that the logic checks the missing cells in positions of the beginning, middle, and end of any particular row.
private static IEnumerable<Cell> GetCellsForRow(Row row, List<string> columnLetters)
{
int workIdx = 0;
foreach (var cell in row.Descendants<Cell>())
{
var cellLetter = GetColumnAddress(cell.CellReference);
int currentActualIdx = columnLetters.IndexOf(cellLetter);
for (; workIdx < currentActualIdx; workIdx++)
{
var emptyCell = new Cell()
{ DataType = null, CellValue = new CellValue(string.Empty) };
yield return emptyCell;
}
yield return cell;
workIdx++;
if (cell == row.LastChild)
{
for (; workIdx < columnLetters.Count(); workIdx++)
{
var emptyCell = new Cell()
{ DataType = null, CellValue = new CellValue(string.Empty) };
yield return emptyCell;
}
}
}
}
Detecting Used Range
Unlike the Office InterOp, there is no Range object in the Open XML SDK library. The WorksheetPart.Worksheet.SheetDimention also doesn't work based on my attempts. Detecting and bypassing the empty rows are necessary since Excel worksheets sometimes leave empty rows after users remove entire data in the spreadsheet rows. In such cases, errors or inefficient iterations will occur during the data transport.
The GetUsedRows function shows how to find the rows having at least one cell value and return those rows as an enumerable no matter what the empty row position is.
private static IEnumerable<Row> GetUsedRows(SpreadsheetDocument document, WorksheetPart wsPart)
{
bool hasValue;
foreach (var row in wsPart.Worksheet.Descendants<Row>().Skip(1))
{
hasValue = false;
foreach (var cell in row.Descendants<Cell>())
{
if (!string.IsNullOrEmpty(GetCellValue(document, cell)))
{
hasValue = true;
break;
}
}
if (hasValue)
{
yield return row;
}
}
}
Data Mapping Function
The data mapping functionality depends on spreadsheet columns, object model properties, and data types. The optimal approach is to delegate the mapping process to a function that is passed as a parameter for calling the ExcelReader.GetDataToList function. In the sample application, the AddProductData function performs the data mapping and then loading the data into the Product object:
private static Product AddProductData(IList<string> rowData, IList<string> columnNames)
{
var product = new Product()
{
ProductID = rowData[columnNames.IndexFor("ProductID")].ToInt32(),
ProductName = rowData[columnNames.IndexFor("ProductName")],
CategoryID = rowData[columnNames.IndexFor("CategoryID")].ToInt32Nullable(),
UnitPrice = rowData[columnNames.IndexFor("UnitPrice")].ToDecimalNullable(),
OutOfStock = rowData[columnNames.IndexFor("OutOfStock")].ToBoolean(),
StockDate = rowData[columnNames.IndexFor("StockDate")].ToDateTimeNullable()
};
return product;
}
The mapping function is actually called within the iteration of spreadsheet rows and return a full data object which will in turn be added to the output generic list.
resultList.Add(addProductData(rowData, columnNames));
There are some add-in features provided by the ExcelReader class to make the data mapping and type conversions convenient and efficient. The following sections will discuss two of these features in details.
Mapping Data with Column Names
Using column names, instead of indexes, for mapping and entering data is a very user-friendly and easy maintenance approach. Column sequences can be ignored both in the data source files and during the mapping process. To make this work, we need to create a generic list to cache the custom column names:
var columnNames = new List<string>();
foreach (Cell cell in wsPart.Worksheet.Descendants<Row>().ElementAt(0))
{
columnNames.Add(Regex.Replace
(GetCellValue(document, cell), @"[^A-Za-z0-9_]", "").ToLower());
}
The column names added to the list items are alpha-numeric only, symbol free except the underscore which is a valid character for C# object property names, and all lower cases. This is a very robust feature in that column names can be set in spreadsheets with any cases, spaces in any positions, and any symbols. Looking back at the source Excel spreadsheet screenshot, you can see asterisks appended to the column names such as "Product Name*" indicating the required field. You can also see all user-friendly column names such as "Out of Stock" instead of "OutOfStock". The mapped output will correctly show the Product object properties ProductName and OutOfStock for these examples.
The steps of the case-insensitive mapping can further be tuned by adding a List class extension method IndexFor into the ExcelReader class so that we can use the extension method instead of calling the native IndexOf and ToLower methods from each items in the data mapping function.
public static int IndexFor(this IList<string> list, string name)
{
int idx = list.IndexOf(name.ToLower());
if (idx < 0)
{
throw new Exception(string.Format("Missing required column mapped to: {0}.", name));
}
return idx;
}
String to Primitive Data Type Conversions
All cell values retrieved from a spreadsheet are in the form of string which needs to be explicitly converted to the types of data model properties if the underlying data type is not the string. The ExcelReader class provides the String class extension methods making the type conversion code neat and centralized:
ToInt32()ToDouble()ToDecimal()ToDateTime()ToBoolean()ToGuid()
Each method also has its nullable version, for example, ToInt32Nullable(). You can see how easy to use the conversion methods in the AddProductData function code shown before. You can also add your own methods for any other type conversions if needed.
It's worth noting that, for date/time entries in the Excel spreadsheet, if the column or cell is not explicitly set as the text format, the Excel will output the OLE Automation date/time (OADate format, a.k.a., the number of Double type referencing to the 12/31/1899 midnight). Below is an example of how the converter handles the situation when the OADate format date/time is received:
public static DateTime? ToDateTimeNullable(this string source)
{
DateTime outDt;
if (DateTime.TryParse(source, out outDt))
{
return outDt;
}
else
{
if (IsNumeric(source))
{
return DateTime.FromOADate(source.ToDouble());
}
return (DateTime?)null;
}
}
Although the code in the sample AddProductData function only maps the data for a simple object model, you can use the same scenario for mapping a pretty complex object containing hierarchical structures. Just make sure that the model properties and all child object properties match the spreadsheet columns for your planed data transport.
Summary
The ExcelReader class presented here is easy to use, powerful, and free of Office InterOp for importing the data from an Excel spreadsheet to a generic list. I hope that the article and sample application are helpful for developers who need to work on the similar areas.
History
- 8th May, 2014: Initial version

