2017-10-13: A newer article with many additional comparison, a new way to store convex hull points and much more: Fast and improved 2D Convex Hull algorithm and its implementation in O(n log h)
Introduction
This article is about an extremely fast algorithm to find the convex hull for a plannar set of points. It also show its implementation and comparison against many other implementations.
This article is the 1st of a series of 3
What is a Convex Hull
According to Wikipedia: In mathematics, the convex hull or convex envelope of a set X of points in the Euclidean plane or Euclidean space is the smallest convex set that contains X. For instance, when X is a bounded subset of the plane, the convex hull may be visualized as the shape formed by a rubber band stretched around X.
You can see a sample of a simple Convex Hull in Diagram 1. The red line is the Convex Hull.
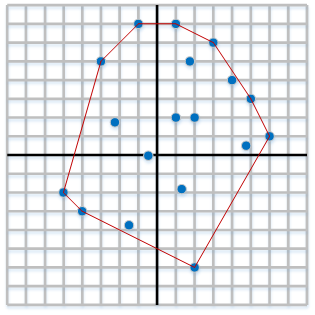
Diagram 1 : Example of a Convex Hull in Red
There are many algorithms that exist to find the convex hull in 2 or 3 dimensions. The Wikipedia enumerates many of these: http://en.wikipedia.org/wiki/Convex_hull_algorithms.
A lot of people have already tried to find a fast algorithm for many years now. Many have found excellent ones. Lately performance has reached O(n log h) where h is the number of points forming the convex hull. Today, I propose an algorithm of that order, in fact I re-explain, in other words, what was found in 2007 by Liu and Chen. I also present its implementation and compare it with a few other algorithms. I will explain here, how it works and why it is very fast.
Motivation
I recently needed to find the convex hull for a large set of points. The simple implementation found in C# was very slow and crashes for a lot of data. There was also some code not written in C# that I could have used. But I wanted one in C# that was quick and reliable. I did not understand every aspect of algorithms found on the web or was too lazy to try to understand them. I thought that I had a good idea and wanted to verify it. I decided to write my own algorithm. Also, I had few other requirements that I wanted to meet at the same time: keep the original points in the same order without having to make a copy of them and being able to multithreading it.
Background
This article involves some basic knowledge in mathematics and geometry like quadrants and slope calculations. But you can understand the main concept although you don't remember any of those.
Knowledge of “dichotomy search” could also help understand the concept and the code provided.
There is also a multithreaded portion that could be skipped without compromising the main comprehension.
Liu and Chen Convex Hull Algorithm
Another Convex Hull Algorithm. This has no initial sorting, no tangent calculation, it works differently. According to tests, it seems to be extremely fast with few more tricks/advantages...
Speed
Until today, the "Chan" algorithm was the latest O(n log h) Convex Hull algorithm, where h is the number of vertices forming the convex hull. I thought that its implementation was recognized as the fastest one. But I think that the "Liu and Chen" algorithm would be either faster or very close to Chan. Actually I would have to test both algorithms in the same language to ensure proper comparison but I'm missing time. I will show results in a different language, Chan in "C" and "Liu and Chen" in C#.
Other Requirements
Existing implementation of “Chan” algorithm that I found does in-place permutation of points to quickly find the Convex Hull. That technique modifies the original points' set order. The requirement of my project was to keep the order of the original set. In order to do so with algorithms like “Chan” we would be to make a copy of the full set of points before calling it. The time required is very fast but it takes 2x the number of points in memory which could be undesirable for very large set of points in a low memory system.
Also, my requirements also have the possibilities of finding the Convex Hull for a list of list of points, which was not directly implemented in Chan and Hull. I implemented that possibility while keeping the usual way of feeding the algorithm with a list, or array of points.
Characteristics of Liu and Chen Convex Hull
Advantages of this Liu and Chen Convex Hull algorithm implementation
- O(n log h), same order as the best actual algorithm
- Results set is separate from the original set of points. Input stay unchanged.
- Maintain small memory usage.
- Could easily be multithreaded (first pass on every thread and second pass on at least 4 threads). Code provided uses both ways (single and multi-threaded).
- No expensive calculations (no sine, no cosine, no tangency, etc.). Only slope calculation (subtraction and division) and its usage is highly minimized.
- Could be called from any IReadOnlyList<Point> (Point[], list<Point>, …) or from any IReadOnlyList< IReadOnlyList<Point>>. Example: Array of points or Array of Array of points.
Other advantages that result from the previous ones
- Output sensitive algorithm. I mentioned here only because other authors have already written it in their own article. To my opinion, I think that any algorithm that mention "h" in its order (ex: "O (n log h)") should be, by default, "output sensitive".
Disadvantages of this implementation of Liu and Chen Convex Hull algorithm:
- Not in place. Results set is separate from the original points which in cases where points reordering is not an issue, it will take unnecessary additional memory
Validation of Liu and Chen Algorithm (Results 5 circles)
I verified my algorithm against an implementation of the Chan Hull found on the internet from Pat Morin from the University of Carleton. That code helped me out a lot to fix my bugs. I want to say a very warm “Thank you” to Pat Morin for having shared its code. At the end of tests, I realized that Pat Morin algorithm implementation had a little bug that occurs when the number of points is small.
All those tests were conducted with the algorithm implemented in single thread. But I also implemented my algorithm as multithreaded, in fixed 4 threads (Ouellet4) which is around 4x faster than my single thread algorithm. I also did another implementation where I do the first pass with all threads and the second pass with 4 threads (OuelletAll).

Diagram2 : Comparison chart of the 4 implementations of 2 algorithms (Chan - “Liu and Chen”)
Diagram 2 shows a comparison chart of 5 implementations of 3 different algorithms. Points used are calculated from 5 circles with random center and with random quantity of points. Each circle has a fixed but random radius. I preferred to use that test instead of a single circle because I thought my algorithm could be a little bit less efficient in those circumstances. All the code used is provided in the download.
Liu and Chen Algorithm Principle
“Liu and Chen” algorithm is developed for 2D coordinated. It could possibly also work for more dimensions but I’m not sure that it would be possible and efficient as it is in 2D.
Note: looking at the example section will help understand the following text.
The algorithm is split in 3 main parts that occurs sequentially:
- First pass - Quadrant definition (find left, top, right and bottom)
- Second pass - Set every hull point per quadrant
- Combination - Combine each hull points quadrant
The algorithm is based on a plan in X and Y with 4 virtual quadrants. Each quadrant has a root point (see Diagram 3). At school we learn that quadrant start at (0,0) and cover a quarter of the plan. But here is different. You can see my “virtual” quadrant as the same except that they don’t start at origin (0,0), they start at, what I call, a "root point". Each root point is specific to each quadrant. They can be all the same but usually are 4 different points. Two opposite quadrants can overlap or there can be holes between quadrants. Quadrant frontiers are related to 4 points: rightmost, topmost, leftmost and rightmost. Those 4 values are extracted from a complete iteration over all points. That is the first pass. Each root is determined by its 2 related values, one in X and one in Y, from its 2 related point. The frontier of the quadrant is determined by X of its min or max Y coordinates and Y of its min/max X coordinates. For example, quadrant 1 (Q1) is determined by X of “top” and Y of “right” point. Those 2 coordinates define the quadrant root point. The quadrant root point is the one used to determine if a point is part of that quadrant or not. Example in the next section should help to understand the principle. There is a special case that could occur when trying to determine the appropriate quadrant, it is when more than 2 or more points has the same maximum coordinate in X or in Y), for example 2 or more “top”. See the example where it applies for Q1 and Q2. The 2 points kept are the 2 further ones from each other and closest to the side of each related quadrant. It should create a hole between the 2 quadrants where there can’t be any convex hull points there.
After each virtual quadrant is determined, I do another pass, the second and final one over each point, to try to insert each point in its appropriate quadrant at their appropriate place. Appropriate quadrant is easily determined by verifying against each quadrant root point. Then I use dichotomy to seek for the right place to insert the new candidate. The search is done comparing only the X coordinate, but I could have used the Y axis. To know if the new candidate should be inserted or not we have to compare 2 slopes:
- The slope of the candidate point to insert and its predecessor
- The slope of the candidate point predecessor and the candidate point successor.
The comparison of both slopes determine if the point should be inserted or not. The decision to include it or not depends on 2 things: 1- the comparison result (greater than or less than), 2- the quadrant itself.
To insert a point between 2, we only have to verify that its slope fits between the slopes of its 2 neighbors. The insertion of a new point could also invalidate 1 or more existing ones which we have to verify for each new point added. The verification of potential new invalid points should start from that newly inserted point and going up and down until we found a point that is still valid as part of the Convex Hull.
Finally, I combine every quadrant convex hull point vector into only one vector in order to form the complete convex hull result set.
Quadrant offer a great advantage. We could know in advance the slope orientation expected. Knowing that, we could easily and quickly: discard a candidate, change an existing one or add a new one. When points become very large, the quantity of points to discard become very important. Being able to discard them quickly help improve the efficiency. Because all points are organized by quadrant and sorted, we can verify and potentially reject quickly bad candidate at the same time we are doing the dichotomy search.
Example
The example is defined for those 12 points:
(1,2) (5,3) (3,6) (2,2) (3,4) (6,1) (1,7) (-3,5) (-5, -2) (-4,-3) (2, -6) (-1, 7), (0, 7)
Step 1 - First Pass
We iterate over every point and find 4 points: right, top, left and rightmost points. We determine quadrant by those points. You can see them on Diagram 3. Here we have a special case that should be considered, 3 points with same Y: (1,7), (0,7) and (-1,7). Those points have all same Y that also define the top. In that case we keep only further points. Here we keep (-1,7) and (1,7). (0,7) will not be used to define Quadrant limits.
Diagram 3: First pass result: Quadrant definition
Step 2 - Pass 2
Iterate over every point a second time and insert or discard point as a convex hull point. Here, on diagram 4, point “A” and point “B” has been found in step 1 as StartPoint and LastPoint of Quadrant1 respectively. We have already inserted point “C”. We want to add point “D”. The slope of CD (-3/2) is smaller than slope of BC (-1) => we should keep “D”. We insert “D” as a convex hull point. We now should iterate from “D” on each side of it to discard any invalidated point cause by the insertion of “D”. In our case, “C” stay because it is still part of the convex hull => slope of AC is smaller than the slope of "CD". If we would like to insert a new point (4,6), this insertion would have invalidated “C” and “D” and they would have been removed in order to stay convex.
Diagram 4: Second pass, insertion of point into appropriate quadrant
Next, there is the results of the completion of step 2. Diagram 5 shows the result of the second pass. We have 4 different vectors of points forming each quadrant portion of the full Convex Hull. They are shown as different colors.
Diagram 5: result of second pass: Find every point forming the convex hull by quadrant
Step 3 - Combination
Combine each quadrant results into one single result. The diagram 6 show the final result where each Quadrant results have been combined together. You can see that point (-1,7) and point (1,7) has been linked. Each point that is the same for each adjacent quadrant had been merged into only one point.
Diagram 6: Final result: combining quadrant results
Optimization
Pre-Allocate Memory
On start I calculated the number of points and allocates initial memory with this formula: square roots (point count). It’s only an estimation. In my test it was pretty close of the results count. But it is not necessarily fit every need. If this optimization does not meet your request, nothing prevents you to calculate the initial size of memory results or let it grow by itself as required. But keep in mind that when a list needs to grow its internal array, it has a cost. In my test case it was a pretty good estimate and I prefer that instead of either let the list grows itself or reserving the total number of points.
Discard Point Without Calculation
Due to quadrant usage, in most cases (when there are a lot of random points), I could discard a point without making any calculation only by comparing its Y coordinate with its predecessor or successor Y coordinate. This single quick test is due to the fact that we already used dichotomy on X and then we know that a new candidate should be located into its 2 ‘X’ coordinate neighbors. As shown in the next example, diagram 7, if “B” and “C” are already inserted as a convex hull point. Having “E” and “F” X coordinate between X coordinate of “B” and “C” would make “E” and “F” potential new candidate as neighbors of “B” and “C”. But we don’t need to verify the slope of those 2 points because both points have a Y coordinate less than Y coordinate of “C”. We can discard them immediately without having to calculate the slope.
Diagram 7: Quick discard
Special cases
There are some special cases that either need attention or at least verification to make sure proper results.
No Point in the Input Collection
When there is no point in the collection, we should do nothing and return an empty collection.
Only One Point
When there is only one point in the collection, we return a collection with that one point only. Although we ask to close the graph, we should return only that single point.
2 points
When there are 2 points in the collection, we return either a collection with 2 points or a collection with one point when the 2 points are the same. We also have to verify that closing graph will work as expected. We should also verify to have proper behavior when: 2 points are aligned with X axis or Y axis.
Any Points in Line
2 or more points as the same top, left, right or bottom
Overlapping quadrant
It could only occur on 2 opposite quadrants at the same time. This is a very special case that need attention. It would not (highly not probable) occurs when testing with high quantity of points randomly positioned in a circle. But it could occur in any case where points are positioned along a diagonal shape, or when points takes a triangle shape. On diagram 8, for example, point “A” is part of red quadrant (Q1) and also of the orange quadrant (Q3). That could be a problem if we only verify point to the first quadrant that it fits in. In this case, point “A” is part of Q1 but does not participate in Q1 convex values. It could only participate as a convex value for Q3. But if we have tested “A” against Q1 first and switch immediately on the next point for evaluation, then we would miss that point as a convex hull point. When there is overlapping quadrant, we should verify with its opposite quadrant to ensure to not lose any possible convex hull point.
Also, as a note, depending on the implementation, when points set are shaped like a triangle or a diagonal then the algorithm could lose performance. It will still be in O(n log h) but could take up close to twice as long in those worst cases here a single point would be validated against 2 different opposite quadrants.
Diagram 8: Overlapping quadrant
The code provided
The code provided give a good approximation of time taken to find the convex hull in few algorithms. Algorithms used for testing are Chan and "Liu and Chen". Be sure to be in “Release”, not in “Debug” to have proper performance comparison results. Comparisons are shown on the output window and saved in temp folder. There are few things you need to know and take into account when evaluating performance results:
- “Chan” and algorithms are done in “C” while all “Liu and Chen” implementation are done in “C#” (C sharp).
- “Chan” are in place algorithm while “Liu and Chen” create another set of points as results.
- Actual “Chan” implementation that I compiled was in 32 bits. Being in 32 bits, forces me to run a maximum set of around 4000000 points. Note that I can’t find the project used to create the DLL. I have source code but I'm not good enough in "C" the recompile it in 64 bits.
- Details of the code from Carleton University is included in zip file.
- I also included another small app to test in 64 bits only. It test each implementation of “Liu and Chen” Convex Hull with very large point set. It shows that it could become interesting to use every core for the first pass when the number of points is enormous. But in general I would not mind and use the forced 4 independent threads which give excellent performance.
- Performance comparison is done sequentially.
The almost same “Liu and Chen” algorithm could be used as 3 different configurations
- SingleThread: Only one thread for each 3 steps of the algorithm.
- 4 threads: 1 thread for the first step. 4 threads for the 2 step and one thread for the combination of each quadrant results.
- “All threads: Use every core to evaluate Quadrant limits (first step), then the same as “4 threads” for the second step and 1 thread for the combination of each quadrant results.
Abstract:
- Be careful: « Bad image format » Error could happen if you try to compile project “ConvexHullTest” in 64 bits. But “ConvexHullPerfTest
- Only” project is made to be compiled and run in 64 bits.
- The graphic control used is DynamicDataDisplay. It is free and nice but slow. Avoid using it with more than 10000 points.
- You could also call my algorithm with a Collection of Collection of Points which it was a requirement in our project. The interface uses IReadOnlyList which I think it is the most open interface that my algorithm required. An array or a "List" would work perfectly.
- Code is made to run in Framework 4.5 or higher. Note that “IReadOnlyList<T>” started in .Net 4.5.
Future – potential development
There are some tracks of potential development for the future… where fun begins.
Performance of the algorithm
That implementation left spaces for improvements in single thread in the algorithm itself. Like possibly exploiting the angle of the candidate to its quadrant root to improve performance of proper insertion point (~dichotomy search vs very close to exact insertion point). Could it be in O(n) or closer to it?
Performance of Multithreading
There are also a lot of multithreading performance possibilities. I should have made the second pass fully multithreaded but I was missing time. I thought that a master thread by quadrant with slaves that would extract only valid possible candidate would have been nice. The master would be the only one which would insert point in its quadrant. With a concurrent stack of only probable candidate between the master and their slaves. The master would clean the stack in priority and then do the same as its slaves. Having that would still continue the advantage of using the full potential of the first pass (determining left, top, right and bottom).
Also, adding a separation of points into buckets would have enabled every thread to be fully independent (except for the concurrent stack) and would maximize the time to fully use all threads. Buckets separation could also be done not equally, few big buckets for the beginning and many smaller one for the end. Another thing that could be done is to quickly verify that a quadrant has no point (if its 2 points forming its limit are the same) and them skip that quadrant completely.
3 or more Dimensions
It could also probably be implemented in 3 or more dimensions but the complexity could become potentially an issue. To remove that potential complexity we could separate exactly the particularities of each quadrant and then make only and only one generic implementation. But it could decrease performance due to calls required for each specific quadrant need, perhaps template could solve that problem?
Important Notes
2014-08-11
After trying to publish my article to an algorithm journal, I had to improve my test and make them in the same language and compiled both in "release", which was not the case. Initial tests were conducted with Chan algorithm code in "C" 32 bits -"Debug" against "Liu and Chen" in C# 64 bits - "Release". I took the time to recompile Chan implementation in "C" 64 bits - "Release". Following results invalidate every statistics show in the original article. Chan in "C" become twice as fast as my implementation in C# instead of the opposite. Both were compiled in 64 bits release.
I updated the graphics and also some parts of the text. It took me sometimes because I was trying to turn my code in C++ which is taking longer than I would have tough initially. I did not complete but I wanted to update the article to ensure to not leave wrong results floating around for too long.
Apologies: I'd like to apologize to everyone about inducing you in error. It is still possible that my algorithm is the fastest but it is not sure and I think it is probably not. If I have ever had enough time to finalize conversion in C++, I will let you know results.
2014-07-25
In 2014-07-25, 14h00, I just found an old article with main concepts of my algorithm, I mean of the algorithm I was presenting here.
The article is from Guang-Hui Liu and Chuan-bo Chen: A new algorithm for computing the convex hull of a planar point set. It was published at Springer in 2007.
Because it would have been unfair to catch credit for an algorithm I was not the first to create, I renamed the Convex Hull algorithm from "Ouellet" Convex Hull algorithm to "Liu and Chen" Convex Hull algorithm. But be sure, I entirely created myself. Everything you see here is from me... I was not the first.
You can see this article as an implementation of Liu and Chen Convex Hull algorithm.
References
- “Space-Efficient Planar Convex Hull Algorithms” from Hervé Brönnimann, John Iacono, Jyrki Katajainen, Pat Morin, Jason Morrison, Godfield Toussaint. This reference is from a pdf paper “insitu-tcs.pdf” which I can’t find any more on the web but I included in my download. The “C” code of Chan implementation also comes from that same place. The author of the code is Pat Morin from the Carleton University. I also included the source code for reference. Although that implementation has a bug, it really helped me a lot in order to find all of my bugs. I suspect it is only a question of “<” instead of “<=” of something similar.
- This is a link to an article that give good explanations of many popular algorithms to evaluate the Convex Hull in 2D: http://www.tcs.fudan.edu.cn/rudolf/Courses/Algorithms/Alg_cs_07w/Webprojects/Zhaobo_hull/ (2017-09-05, this link is obsolete, sorry)
Acknowledgment
- Thanks to Omar Saad, my project manager, for explaining to me what a convex Hull and having left me the time to write this article and code.
- Thanks to Paul Labbé, a co-worker, for showing me what the vector multiplication is.
- Thanks to Pat Morin for its free “C” code of Chan algorithm implementation.
- Thanks to Henri de Feraudy for reviewing my article and give me around a hundred syntax and grammar corrections to do in order to make it better (november 2017).
History
- Version 1.0 - Released 2014-05-20, Initial post
- Version 1.1 - Released 2014-05-21, fixed some minor bugs in code. Light modification in text.
- Version 1.2 - Released 2014-05-22, fixed some image and text according to colleague remarks.
- Version 1.3 - Released 2014-06-17, Code change: use of StopWatch instead of DateTime and added rectangle performance tests. Both suggestions from Qwertie - Thanks!
- Version 1.4 - Released 2014-07-24, Slight modification/improvement in text. Correction of Diagram 8: Overlapping quadrant.
- Version 1.5 - Released 2014-07-25, a very bad day... I realized that I was not first one to discover that algorithm. I modified my algorithm to not take credit for something I wasn't the first one to discover. The content and code are still valid but please read Errata at the beginning to find the first article published with this algorithm. I will also update Wikipedia because it wasn't there and that's why I wrote all of this.
- Version 1.6 - Released 2014-08-11, another bad day, just after 2014-07-25 I took some time to find/compile the Chan algorithm in C++ from Pat Morin in 64 bits release (it was in 32 bits debug). Results were just awesome. The algorithm was extremely fast, more than twice as fast than in debug. I updated the article accordingly and updated the comparison chart also. Actual results show a clear advantage on performance of Chan Algorithm. But there is something that left to be done to have proper comparison: to make my implementation in C++ instead of C#... I started, but I'm missing time.
- Version 1.7 - Released 2016-02-04, Smjert brings my attention on an error. Thanks a lot. Error is in Q4.
- Version 1.8 - Released 2016-02-13, corrected 2 small bugs in Q2 and Q3 when the new value to check for insertion has the same X value as one that is already present as a Hull values. Added some tests to ensure to detect those cases. I also added the Pat Morin implementation of Chan Hull in 64 bits Release (it was the 32 bits debug). A special thanks to Smjert: after he asked me the question, I realized that I did not pay enough attention to this case and made some checks to ensure proper behavior.
- Version 1.9 - Released 2016-02-17, the most major change is a new way to discard point. Instead of using slope, I use vector multiplication. I took the formula from Tryss in http://forums.futura-sciences.com/mathematiques-college-lycee/510583-point-dun-cote-de-lautre-dune.html. The idea is from a co-worker: Paul Labbé. Its idea brings better performance and more clarity to the code because I could transfer specific quadrant code to their base class. It uses 2 multiplications instead of a division but it is still faster. I added tests to prove that. It also uses a little less memory. I fixed few bugs that could happen in rare cases. I reworked everything. It is simpler and easier to follow. I added a lot more tests which make me think that I have no more errors. As a side note, I know I have to update all of my article with those related changes, I will do it soon after I will complete some other related works. I just want to share all of my works the sooner. I'm pretty confident this is the fastest algorithm to find a ConvexHull in 2D, ever :). Hope you will like it.
- Version 1.9.1 - Rearrange paragraphs in order to not start the article with 2 errata. I move them into "Important notes" section.
- Version 1.9.2 - Removed the hyperlink for "Futan University" because it is obsolete and I can't find an alternative. Sorry.
- Version 1.9.3 - Released 2017-10-13, Added a link to newer article about the same algorithm: Fast and improved 2D Convex Hull algorithm and its implementation in O(n log h)
- Version 1.9.4 - Released 2017-11-17, major corrections applied. Thanks a lot to Henri de Feraudy for thoroughly reviewing of my article. A perfect stranger who did it for free on its own time. You should see its Google+ website to see a portion of its knowledge. He brings me around a hundred syntax and grammar corrections.
- Version 1.9.5 - Released 2017-12-11, fixed a bug when the amount of point is 0 or 1 in the first quadrant. The bug was reported by "ephraim" on StackOverflow. Thanks a lot to him! Source and binaries are fixed. Note: The newer article is not impacted by this bug (it was already fixed).

