Introduction
This is the second article of a 3-part series about an open-source project that I have been developed recently called Semantika. If you haven't read the first article, please jump to the link below and return back here again after you have finished reading.
Part 1 - Introduction to Semantika DRM
In this article, I am going to introduce the concept of relational-to-domain mapping modelling used by Semantika and its language features. The language syntax will be in Termal/XML format. Note that an equivalent R2RML document is possible to produce from Termal document, and vice-versa.
Background
I assume my readers have some background in Java programming, relational database and XML. Knowledge in semantic web technology such as OWL, RDF and SPARQL will be beneficial but not primarily necessary.
The Basic Concept
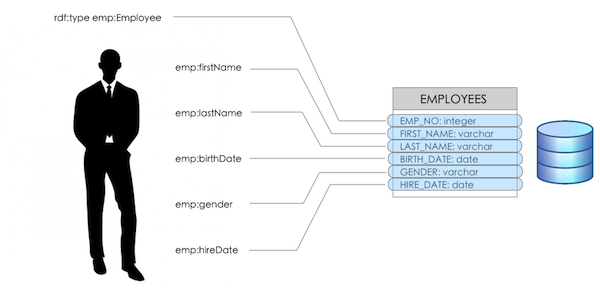
The notion of domain-to-relational mapping can be loosely understood as a formal specification that defines the relationship between domain vocabulary and data schema in database. It is used to map data in database to instances of classes and properties in the ontology. Conceptually speaking, mapping model carries a formula that—when it is applied—can produce object instances for each row in the source table or SQL view.
To illustrate, suppose I have data employee in the following table.
| EMP_NO | BIRTH_DATE | FIRST_NAME | LAST_NAME | GENDER | HIRE_DATE |
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 |
| 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 |
Using the mapping model depicted above, the model is able to produce equivalent object instances depicted as follows:

In Semantika, each mapping statement is called mapping axiom. These axioms will help to answer the user query by transforming each query part into a native SQL query string. The query execution then goes to the underlying database engine and returns the result.
Language Features
Semantika uses XML document for reading mapping statements. The document definition is straightforward and easy to edit manually. If you are familiar with R2RML specification then this section is just a simple walkthrough. But if you're not, this is just another presentation about a document configuration.
Below is an example of a mapping document in Termal/XML format. The green bullet points are the sections that will have a further comment.
1. Prefix
Prefix is used to simplify writing the long names in a short format. Usually a prefix's namespace uses URI string in order to guarantee its unique form. For example, instead of writing a long resource name such as:
http://obidea.com/ex/ontology/work#Employee
http://obidea.com/ex/ontology/work#lastName
You can simplfy the writing to be emp:Employee and emp:lastName as long as you have specified the emp prefix has a URI namespace refer to http://obidea.com/ex/ontology/work# in the document.
Notice that the example above uses an empty prefix. This is a special notion to define a default prefix. This means if the resource name has no prefix assigned, it is assumed to use the default prefix.
2. URI Template
The URI template is a global definition to build an object identifier and highly reusable. It consists of a name and a template string. The template string has a special syntax for column referencing by enclosing an integer number in curly braces ("{" and "}"). Any mapping can use a particular URI template using a template call.
The following example defines a URI template named "Employee" and a template string with two column reference. A template call was made by subject-map that uses DEPT_NO and EMP_NO columns as the identifier component.
<uri-template tml:name="Employee"
tml:value="http://obidea.com/ex/ontology/work?department={1}&employee={2}>
<mapping>
...
<subject-map rr:template="Employee(DEPT_NO,EMP_NO)"/>
</mapping>
You should notice that the approach is similar to a function call in programming paradigm where the the function name is associated to the template name and the arguments are the column references.
3. TriplesMap (Example 1)
Before we go into detail at each example case, let me briefly introduce you to several important elements inside TriplesMap.
A. Logical Table
The content of logical-table element represents the data rows that are going to be mapped to object instances. There are two ways specifying the logical table:
- Use
rr:tableName property to specify the SQL table used for the mapping. The value must be a valid schema-qualified name that points to an existing table or view in the input database. - Write a SQL query to select a specific region of data used for the mapping. The query string must be a valid SELECT query in SQL language that can be executed over the input database.
B. Subject Map
What the subject-map essentially does is assigning an object identifier for each row in the logical table. The map may have a class IRI (i.e., represented by rr:class property) to declare explicitly the object type.
C. Predicate Object Map
The predicate-object-map is used to map class attribute or relation to a specific column in the logical table. Please note that attribute and relation are two different concepts, i.e., an attribute is associated to a typed value and a relation is associated to an object reference, denoted by an object identifier.
Returning to the example case, the first map shows you a simple mapping model for capturing the employee's profile.
<mapping>
<logical-table rr:tableName="EMPLOYEES"/> (1)
<subject-map rr:class="Employee" rr:template="Employee(EMP_NO)"/> (2)
<predicate-object-map rr:predicate="firstName" rr:column="FIRST_NAME"/> (3)
<predicate-object-map rr:predicate="lastName" rr:column="LAST_NAME"/> (4)
<predicate-object-map rr:predicate="hireDate" rr:column="HIRE_DATE"/> (5)
</mapping>
Line (1) specifies EMPLOYEES table is used for the mapping data source.
Line (2) indicates Employee(EMP_NO) is used to identify rows in table EMPLOYEES and all the produced instances belong to a class Employee.
Line (3), (4), (5) specify several attribute mappings for class Employee.
4. TriplesMap (Example 2)
The second map shows you an example of relation mapping.
<mapping>
<logical-table rr:tableName="DEPT_EMP"/> (1)
<subject-map rr:template="Employee(EMP_NO)"/> (2)
<predicate-object-map rr:predicate="worksIn" rr:template="Department(DEPT_NO)"/> (3)
</mapping>
Line (1) specifies DEPT_EMP table is used for the mapping data source.
Line (2) indicates Employee(EMP_NO) is used to identify rows in table DEPT_EMP. However the produced instances will not have a type.
Line (3) specifies a worksIn relation between an object identified by Employee(EMP_NO) and another object identified by Department(DEPT_NO).
5. TriplesMap (Example 3)
The third map shows you an example of using SQL query as logical table.
<mapping>
<logical-table> (1)
<![CDATA[ (2)
select EMP_NO (3)
from TITLES (4)
where TITLE = 'Staff']]> (5)
</logical-table> (6)
<subject-map rr:class="Staff" rr:template="Employee(EMP_NO)"/> (7)
</mapping>
Line (1)-(6) specifies a SQL query used for the mapping data source. The query returns all employees that has job title 'Staff'.
Line (7) indicates Employee(EMP_NO) is used to identify the rows returned by the SQL query and all the produced instances belong to a class Staff.
Conclusion
I hope I have delivered this article in a plain way that all my readers can easily understand the basic usage of mapping modelling. Depending on your domain complexity and data schema size, developing a mapping model can be a challenging task but rewarding at the end. Moreover, the shape of the mapping model can affect the query performance. (Perhaps I will cover some tips and tricks in another article).
So to conclude this article:
- Tailoring a mapping model requires a good understanding in both domain area and database.
- Think mapping model as a company artifact. It is a knowledge asset that specifies the link between your business domain and the data.
- Passing the mapping model means you are 80% learning Semantika.
Please visit http://obidea.com/semantika to download the API. I am looking forward for your questions, feedback or comment regarding the mapping model. You can reach me on my email address josef [dot] hardi [at] gmail [dot] com or participate in our user community.
History
24-06-2014:

