Introduction
This is the third article of a 3-part series about an open-source project that I have been developed recently called Semantika. If you haven't read the first or the second article, please jump to the links below and return back here again after you have finished reading.
Part 1 - Introduction to Semantika DRM
Part 2 - Relational to Domain Mapping Modelling
In this final article, I am going to show you how to use the platform by creating a simple query answering application. The application that we are going to make is a console application. It uses text terminal to write/read the input/output. This will be a tutorial in Java programming.
The application has been tested and successfully run in OSX 10.8 and Java 7 SDK.
Background
I assume my readers already have some background in Java programming, relational database and XML. Prior knowledge in semantic web technology such as OWL, RDF and SPARQL will be beneficial.
A Hello World Tutorial
In this section, I am going to guide you step-by-step creating the application. You can find the application source code in this article's page. However, I recommend you to follow each step and do the instruction by yourself. It is a brief tutorial so it won't take much of your time.
Prerequisite
You will need to download Semantika distribution package (the latest version is 1.6 at the time this article is written). You can download it from its website at http://obidea.com/semantika by clicking the big green button.
Or, using wget in the command-line:
wget https://github.com/obidea/semantika-api/releases/download/v1.6/semantika-dist-1.6.zip
Unzip the package and we will locate the directory path as SEMANTIKA_HOME variable.
Running Database
The first component we need to have is a running database. For this purpose, I have prepared a dummy database that you can download here.
Or, using wget again:
wget https://github.com/obidea/semantika-api/releases/download/v1.1/h2-semantika_24-02-2014.zip
Inside the zip file is a stand-alone H2 database. It contains data about employees stored in 6 tables. The data schema is depicted as follows:
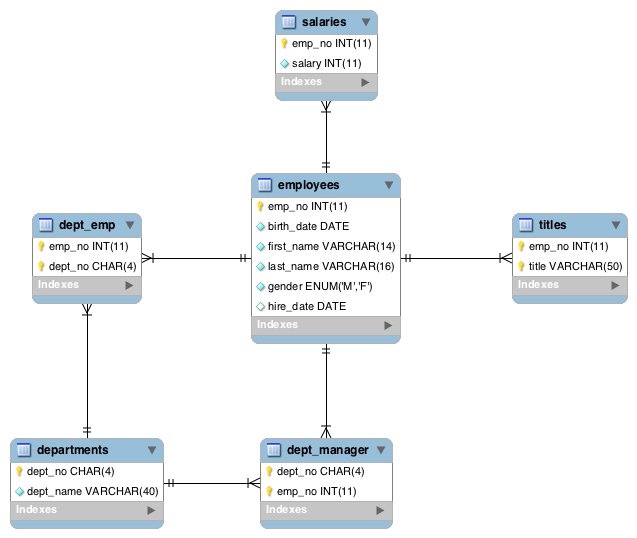
To run the database, double-click the file h2.sh (in Unix) or h2.bat (in Windows).
Or, using command-line:
./h2.sh
It will immediately open H2 Web Console in your default browser.
Important Note: Semantika runs over JDBC platform for data connection. It needs a JDBC driver associated to the underlying database. You can locate the driver inside the H2 folder named h2-1.3.168.jar and copy-paste (not cut-paste) the file to SEMANTIKA_HOME/jdbc folder.
Model Resources
For the model resources, we are going to use both the ontology and the mapping model.
I made myself the ontology to describe people working in a company. It is a simple modelling where I use labels that are usually appeared in a job hierarchy and some typical relations between employees, departments and managers. The overview of the ontology model is depicted as follows:

Download both the ontology and the mapping model from here and here.
Or, using wget:
wget https://raw.githubusercontent.com/obidea/semantika-api/master/model/empdb.owl
wget https://raw.githubusercontent.com/obidea/semantika-api/master/model/empdb.mod.xml
Put both files in SEMANTIKA_HOME/model directory. You might notice there are several files already inside the folder. They are just some templates for starter, you may either ignore or delete them.
Client Java Code
Now we are ready to do some coding. We are going to make a console application that accepts input query interactively from users and displays the result.
Here is the complete source code:
import java.io.*;
import com.obidea.semantika.app.Environment;
import com.obidea.semantika.app.ApplicationFactory;
import com.obidea.semantika.app.ApplicationManager;
import com.obidea.semantika.queryanswer.IQueryEngine;
import com.obidea.semantika.queryanswer.result.IQueryResult;
public class EmployeeApp
{
private static IQueryEngine mQueryEngine;
public static void main(String[] args) throws Exception
{
initialize();
start();
try {
String queryString = readUserInput();
executeQuery(queryString);
}
finally {
stop();
}
}
private static void initialize() throws Exception
{
ApplicationManager appManager = new ApplicationFactory()
.setName("empdb-app")
.addProperty(Environment.CONNECTION_URL, "jdbc:h2:tcp://localhost/empdb")
.addProperty(Environment.CONNECTION_DRIVER, "org.h2.Driver")
.addProperty(Environment.CONNECTION_USERNAME, "sa")
.addProperty(Environment.CONNECTION_PASSWORD, "")
.setOntologySource("model/empdb.owl")
.addMappingSource("model/empdb.mod.xml")
.createApplicationManager();
mQueryEngine = appManager.createQueryEngine();
}
private static void start() throws Exception
{
mQueryEngine.start();
}
private static void stop() throws Exception
{
mQueryEngine.stop();
}
private static void executeQuery(String queryString) throws Exception
{
IQueryResult result = mQueryEngine.evaluate(queryString);
printResult(result);
}
private static String readUserInput() throws Exception
{
System.out.println();
System.out.println("Please type your query (use a period '.' sign to finish typing):");
StringBuilder userQuery = new StringBuilder();
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
while (true) {
String str = br.readLine();
if (str.equals(".")) {
break;
}
userQuery.append(str).append("\n");
}
return userQuery.toString().trim();
}
private static void printResult(IQueryResult result)
{
int counter = 0;
while (result.next()) {
counter++;
System.out.println(result.getValueList().toString());
}
System.out.println(counter + " row(s) returned");
}
}
There are several things to highlight regarding the API usage. As you can see from the main method, there are some steps that make the application runs:
initialize(): The opening lines in this method defines how to create an ApplicationManager using some configuration parameters. These parameters store the database connection strings and the resources location in the local file. When they are valid, you can obtain the QueryEngine instance to serve the query requests.
start() and stop(): These two methods control the database resource. This separation allows developers to freely place the connection setup in the application code. It is recommended, however, to always stop the engine everytime you open one to avoid memory leaking.
executeQuery(): This method will do the query execution and return a QueryResult object. The API provides several methods for accessing the result for post-processing and data manipulation.
Copy-and-paste the source code above and create a new file in SEMANTIKA_HOME/EmployeeApp.java. In the next section, we are going to compile the code and run some sample queries.
Executing Queries
First we need to compile the source code. In your SEMANTIKA_HOME, type:
javac -cp .:jdbc/*:lib/*:semantika-core-1.6.jar EmployeeApp.java
If you are in Windows, replace the colon ':' with semi-colon ';' in -cp option.
To run the application:
java -cp .:jdbc/*:lib/*:semantika-core-1.6.jar EmployeeApp
This will throw you some logging messages similar to the following snapshot where it then halts and waits for an input SPARQL query.
2014-06-25 14:05:56,644 INFO [application] Initializing ApplicationManager.
2014-06-25 14:05:56,955 INFO [application] Loading [DATABASE] object...
2014-06-25 14:05:56,969 WARN [connection] An empty password is being used.
2014-06-25 14:05:57,178 INFO [application] Loading [ONTOLOGY] object...
2014-06-25 14:05:57,470 INFO [application] Loading [MAPPING SET] object...
2014-06-25 14:05:57,980 INFO [application] Creating knowledge base...
2014-06-25 14:05:57,981 INFO [application] Optimizing knowledge base...
Please type your query (use a period '.' sign to finish typing):
SPARQL Query
Explaining the whole features of SPARQL can fit into a book. In this subsection, I will give you a brief introduction instead about the concept and its syntax to give you the idea.
SPARQL (read: sparkle) is a query language for RDF database and it works by pattern matching. What does it mean? First you need to know what is RDF data. Conceptually, an RDF data is a graph data, written in a 3-component string: subject-predicate-object. Some examples:
- <http://example.org/Subject> <http://example.org/Predicate> <http://example.org/Object>
- <http://obidea.com/ex/ontology/empdb#10001> <http://obidea.com/ex/ontology/empdb#lastName> "Facello"
- emp:10001 rdf:type emp:Employee
SPARQL is a query language to retrieve this kind of data. The syntax follows the same triple pattern, for example:
SELECT ?employee ?lname
WHERE {
?employee <http://obidea.com/ex/ontology/empdb#lastName> ?lname .
}
If we apply this query to the data example above, the results will be <http://obidea.com/ex/ontology/empdb#10001> and "Facello". As you are aware now, the results were determined by matching the triple pattern from the query to the patterns in the dataset.
Practical notes about SPARQL syntax: writing shortcuts to avoid repetition!
-
Using a semi-colon to denote the subsequent triples use the same subject. These two lines of triples below are equivalent.
?x :firstName ?fname; :lastName ?lname .
?x :firstName ?fname . ?x :lastName ?lname .
-
Use a comma to denote the subsequent triples use the same predicate. These two lines of triples below are equivalent.
?x :memberOf :dept1, :dept2 .
?x :memberOf :dept1 . ?x :memberOf :dept2 .
The full specification about SPARQL can be found at http://www.w3.org/TR/sparql11-query/. You will find that this query language has similar SQL features, e.g., DISTINCT, FILTER, UNION, ORDER BY, OFFSET, LIMIT, functions, etc.
Quick Examples
In this subsection, I will present you several SPARQL examples that you can copy-paste and try to execute using the application.
Query 1: Show all employees full name
PREFIX : <http://obidea.com/ex/ontology/empdb#>
SELECT ?fname ?lname
WHERE
{ ?x :firstName ?fname;
:lastName ?lname .
}
(expected output: 50,000 records)
Query 2: Show all the engineers
PREFIX : <http://obidea.com/ex/ontology/empdb#>
SELECT ?fname ?lname
WHERE
{ ?x a :Engineer;
:firstName ?fname;
:lastName ?lname .
}
(expected output: 5,185 records)
Query 3: Show the Human Resources manager
PREFIX : <http://obidea.com/ex/ontology/empdb#>
SELECT ?fname ?lname
WHERE
{ ?manager :leads ?department;
:firstName ?fname;
:lastName ?lname .
?department :deptName "Human Resources" .
}
(expected output: 1 record [=Xiong Peron])
Query 4: Show all employees that were hired later than January 1, 1995 and already have salary more than 50K
PREFIX : <http://obidea.com/ex/ontology/empdb#>
SELECT ?fname ?lname ?hiredate ?salary
WHERE
{ ?x :firstName ?fname;
:lastName ?lname;
:hireDate ?hiredate;
:salaryAmount ?salary .
FILTER ( ?hiredate > '1995-01-01' && ?salary > 50000 )
}
(expected output: 3,367 records)
Query 5: Show all sales employees that have salary more than their boss
PREFIX : <http://obidea.com/ex/ontology/empdb#>
SELECT ?fname ?lname
WHERE
{ ?boss :leads ?dept;
:salaryAmount ?bossSalary .
?emp :memberOf ?dept;
:firstName ?fname;
:lastName ?lname;
:salaryAmount ?empSalary .
?dept :deptName "Sales" .
FILTER ( ?empSalary > ?bossSalary && ?emp != ?boss )
}
(expected output: 362 records)
Sample Execution
Don't forget the period at the ending line!
$ java -cp .:jdbc/*:lib/*:semantika-core-1.6.jar EmployeeApp
2014-06-25 14:05:56,644 INFO [application] Initializing ApplicationManager.
2014-06-25 14:05:56,955 INFO [application] Loading [DATABASE] object...
2014-06-25 14:05:56,969 WARN [connection] An empty password is being used.
2014-06-25 14:05:57,178 INFO [application] Loading [ONTOLOGY] object...
2014-06-25 14:05:57,470 INFO [application] Loading [MAPPING SET] object...
2014-06-25 14:05:57,980 INFO [application] Creating knowledge base...
2014-06-25 14:05:57,981 INFO [application] Optimizing knowledge base...
Please type your query (use a period '.' sign to finish typing):
PREFIX : <http://obidea.com/ex/ontology/empdb#>
SELECT ?fname ?lname
WHERE
{ ?x :firstName ?fname;
:lastName ?lname .
}
.
[fname=Georgi; lname=Facello]
[fname=Bezalel; lname=Simmel]
[fname=Parto; lname=Bamford]
[fname=Chirstian; lname=Koblick]
[fname=Kyoichi; lname=Maliniak]
[fname=Anneke; lname=Preusig]
[fname=Tzvetan; lname=Zielinski]
.
.
.
[fname=Hein; lname=Zizka]
[fname=Siddarth; lname=Krogh]
[fname=Jaana; lname=Bolotov]
[fname=Ottavia; lname=Keirsey]
[fname=Piyush; lname=Spataro]
[fname=Heekeun; lname=Emmart]
50000 row(s) returned
Final Conclusion
In this final article, I would like to express my motivation behind the development of Semantika, following Simon Sinek's Golden Circle Why-How-What:
WHY: I want to challenge the issue in relational database technology that seems inadequate to answer the current trend in data management.
HOW: By applying the concept of open-world database that gives relational technology a new look. This concept and the new look are the face of the presently semantic web technology.
WHAT: It happens to be I developed Semantika in the effort to achieve such goal. The solution is less invasive and has a promising expectation. Do you want to try it?
I hope this last article can convice you to start looking at Semantika and using it. There are still plenty of topics to tell about this platform. The untold features. The benchmark. The future plan. So perhaps I will write more stories in the future.
Epilog
At its current version 1.6 Semantika is still at its early stage. There are still many things need to be implemented and the algorithm needs more optimization work. So yeah, there are still plenty of room for improvement. Although I have to say the product itself is still missing real use cases.
In my Trello account, I have a long list of new and exciting features but sometimes I have the difficulty to decide which one should go first. Furthermore, I am not sure if the features are that exciting because I haven't listened to your voices. I hope by writing these articles I have done something useful and friendly: waving and getting your attentions.
For those who are interested to the idea and would like to contribute, please visit our GitHub repository at https://github.com/obidea/semantika-core. The source code is there and you are free to download, study and modify it.
For developers and end-users, you can get the binary code and start using it at http://obidea.com/semantika.
History
25-06-2014:
26-06-2014:
- Add the missing download link to the sample app source code
- Display the results in Sample Execution section

