Introduction
Design a computer language ,a compiler and an interpreter around it, needless to say that we are scratching the surface (and I hope to scratch deep).
Background
You should have some knowledge of C/C++, a basic understanding of algorithms (esp. : Trees), x86 assembly (MASM) and Turing completeness (http://en.wikipedia.org/wiki/Turing_completeness).
We design the simplest of language which supports one type (to avoid type context sensitive grammar) and is better than a Turing tarpit (http://en.wikipedia.org/wiki/Turing_tarpit), its best you keep your language specification to context free to avoid resolving unnecessary ambiguity. e.g. :- C/C++ generates different assembly code for float and int type (hence code generation is sensitive to the type amongst other things). since this is my first article towards creating a computer language, lets keep it simple, also grammar checks for this language are missing and can easily be added once you understand the generation of the syntax tree related to expression handling.
This article also introduces to the reader a glimpse of commercial compiler implementation and language evaluation without the thrills of syntax/type checking.
Also this article does not expose you to optimizations (all commercial compilers spend a considerable compilation time towards this) and I do hope to add the following in our compiler (may be in my next article):
http://en.wikipedia.org/wiki/Dead_code_elimination
http://en.wikipedia.org/wiki/Register_allocation
Using the code
As with my previous articles, the code must be referred to at all times and debugged to get a better understanding of how it works.
The basis of Turing completeness are
- Writing/reading arbitrary values to/from arbitrary memory location e.g. : a=10, b=b*2+a,c=b+a.
- JUMPS , allow execution of jumps to perform looping and static flow control of program (static flow does not depend on runtime values of variables)
- #ifdef, #else , #endif. if(false) etc can perform static flow control in C.
- Flow control e.g. : if a isEqualTo 2 Then Goto End1, here flow is controlled at runtime, (depends on runtime value of variable(s)).
With flow control, we can create loops, function recursion (feel free to build them using your language).
No language is complete without an expression evaluator
We are supporting the following operators in precedence (), *,/,% (mod),+. We do not support '-' since we are going to replace all expressions of the type a-b to a-1*b and handle -1*b as an independent sub expression (you may handle it differently by placing the value of -b as a complement of b e.g. : -1 will be represented as 0xffffffff and then generate out put as a+b).
First we start by evaluating the bracket '('
we must perform a search for '(' by using if(strstr(str,"("))
if we find it, we call string EvaluateBrackets(const char *ex_str,bool bBuildCode=false)
We start by evaluating the innermost bracket by looking for the first closing bracket: ')', we then work our way backwards to the first opening bracket (found in back search which means the last opening bracket before we meet the first closing bracket), refer to code.
string EvaluateBrackets(const char *ex_str,bool bBuildCode=false)
{
string ret="";
stack<char,vector<char>> bracket_check;
for(UINT i=0;i<strlen(ex_str);++i)
{
bracket_check.push(ex_str[i]);
if(ex_str[i]==')')
{
int j=i;
string bracketed;
while(1)
{
bracketed+=bracket_check._Get_container()[j];
if(bracket_check._Get_container()[j]!='(')
{
bracket_check.pop();
--j;
}
else
{
reverse(bracketed.begin(),bracketed.end());
static UINT tempVarCnt=0;
char tempVar[STR_SIZE]={};
sprintf(tempVar,"__t%u",tempVarCnt);
ret=stringReplace(ex_str,bracketed.c_str(),tempVar);
++tempVarCnt;
variableList[tempVar]=expression(stringReplace(stringReplace(bracketed.c_str(),"(","").c_str(),")","").c_str(),tempVar,bBuildCode);
return ret;
}
}
}
}
return ret;
}
Notice that we replace the innermost bracket with a temporary variable for evaluating an expression, something that C/C++ and other compilers must do: please refer http://msdn.microsoft.com/en-us/library/a8kfxa78.aspx
Now comes the fun part, expression evaluation
This is best done building a tree and is simple (provided you know data structure:Tree)
struct Tree
{
Tree():r(0),l(0),m_expression(" "),m_data(" "){}
string m_expression;
string m_data;
Tree *l,*r;
void AddSubExpressions(string expression)
{
m_expression=expression;
bool bFound=false;
PairString pa;
if(Findoperator(expression,"+",pa))
{
this->m_data="+";
bFound=true;
}
else if(Findoperator(expression,"%",pa))
{
this->m_data="%";
bFound=true;
}
else if(Findoperator(expression,"/",pa))
{
this->m_data="/";
bFound=true;
}
else if(Findoperator(expression,"*",pa))
{
this->m_data="*";
bFound=true;
}
if(bFound)
{
this->l=new Tree;
this->r=new Tree;
this->l->AddSubExpressions(pa.first);
this->r->AddSubExpressions(pa.second);
}
}
}
for an expression a=10+3*5 the following tree is generated, you can provide more complicated expression to see the tree being generated, also traversal of this tree in the pre-order , in-order , post order will provide you with a prefix, infix and post fix expression.
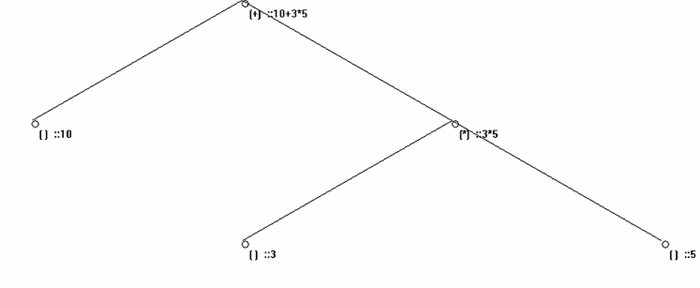
Lets compute this expression
For this we will call the function static int compute(Tree *tmp,bool &bFoundVariable)
a DFS traversal does the trick (http://en.wikipedia.org/wiki/Depth-first_search), using function recursion.
if(strstr(tmp->m_data.c_str(),"+")!=0)
{
return compute(tmp->l,bFoundVariable)+compute(tmp->r,bFoundVariable);
}
if(strstr(tmp->m_data.c_str(),"%")!=0)
{
return ((int)compute(tmp->l,bFoundVariable))%((int)compute(tmp->r,bFoundVariable));
}....
The instruction pointer :-
For Interpreter:
We will use the file pointer itself to point to the next line for execution, being an interpreter we will read and evaluate each line independently using only the variable / label table (with their values) generated while executing the previous lines (C/C++ also evaluates each sentence independently and uses the tables related to function and variables generated while evaluating the previous lines).
For Compiler:
Since we have to generate an executable, we do not have the source code on which we can run the file pointer as an instruction pointer, the executable must be sufficient to execute without the source file, here we will have to generate the complete code itself (we will generate x86 32-bit assembly code, to be consumed by MASM).
We need to evaluate all the variables as they appear in the source code, we do this by calling void BuildASMCode(Tree *tmp,string Temp) to generate x86 code.
Optimization used here:-
static int compute(Tree *tmp,bool &bFoundVariable) is used to find the value of the variable, inputs are the expression tree (we generated it earlier) and bFoundVariable, if bFoundVariable returns as false, the variable is optimized and code generated is as
int y=compute(...)
MOV EAX, y
MOV variable,EAX
e.g. : a=b+1 , a's value is dependent on b's and hence will not be optimized (bFoundVariable will return true) , but a=2+3 can be optimized to a=5 (bFoundVariable will return false hence the optimization)
When bFoundVariable returns true, we will traverse the expression and build assembly code to compute its value:
BuildASMCode(Tree tmp, string Variable variableName)
{
BuildASMCode(tmp->l,templ);
BuildASMCode(tmp->l,tempr);
MOV eax,templ
MOV ebx,tempr
if(tmp->m_data=="+")
{
ADD EAX,EBX
MOV variableName, EAX
}
}
We also have to define all the variables (including the temporary ones) in a data region of the ASM file
fprintf(m_fp,"\n.DATA\n");
for(map<string,int>::iterator it=variableList.begin();;++it)
{
if(it==variableList.end()) break;
fprintf(m_fp," %s DD 0 \n",it->first.c_str());
}
Now that we have looked at expression evaluation, lets look at flow control
Remember Turing completeness requires flow control : branching through which we can perform controlled looping
Many languages that choose performance over Turing completeness due to performance reason choose not to provide flow control, this makes sense due to the pipeline nature of high performance (simple) processors that don't need elaborate branch prediction and not decrease high performance through put due to branch miss, e.g. :- older shader languages (DX shader 1.0): http://amd-dev.wpengine.netdna-cdn.com/wordpress/media/2012/10/HLSLNotes.pdf
uncontrolled jump: GOTO, controlled flows are implemented the same way
For Interpreter:
We must generate the table for labels available , hence we must parse the entire source file once
while(!feof(fp))
{
fgets(Buffer,sizeof(Buffer),fp);
char *str=strstr(Buffer,"LABEL:");
if(str)
{
stringArray strArr=tokenizer(Buffer,":");
strArr[1].at(strArr[1].length()-1)=NULL;
::gotoLabelList[strArr[1]]=LineCnt;
}
LineCnt++;
}
The gotoLabelList will maintain the position of the line number where the Labels are found, when a GOTO statement is found , we will increment/decrement the file pointer to that line number in the source code.
int iCurrentLine=0;
#define JMP(j) {fclose(fp);\
fp=fopen("program.txt","r");\
\
iCurrentLine=j+1;\
\
for(int i=0;i<j+1;i++)\
fgets(Buffer,sizeof(Buffer),fp);\
}
for conditional jumps, we only allow jumps when our condition is matched.
For Compiler:
This is simple for a compiler since .asm files already have provisions for labels and jmp (with condition) instructions, we only have to write them to .asm file when encountered in the source code (while reading the source code line wise).
Function calling
For Interpreter:
We use the existing tables for labels, and implementation is similar to GOTO, but we must maintain the stack to keep our return address, funcRet.push_back(iCurrentLine), maintains the line number to which it must return when RETURN is encountered.
For Compiler:
This is simple (like the GOTO syntax discussed before) since .asm files already have provisions for labels and call/return instructions, x86 maintains the call stack.
Array support
I am currently not supporting arrays and their respective index based array access. We will look into it in another article.
Last bit
BREAK: this tells the interpreter /compiler that the end of program has been reached must exit execution
Output assembly
generated by the compiler can be assembled using MASM (32-bit ) , ships with VS2012, please refer to attached code for instructions related to MASM (ml.exe).
A Break point Int 3 is added forcing the executable to break into a debugger, this will allow you to see the output using the processes memory viewer (part of the debugger).
Points of Interest
I hope this article demystifies the defining of a programming language and construction of a compiler/interpreter. I do plan to write more articles on this subject and add more features to our language.

