Introduction
I am currently writing a guide of Best C# Practices to be used at work and, after writing the points I consider to be the most important, I decided to ask for help to see if there were important points that I could be forgetting. One of my colleagues handed me the book Clean Code - A Handbook of Agile Software Craftsmanship.
I heard about that book many times but I never read it before. So, I did take a look at it. There are many points that I agree with, some that I disagree (yet I consider more a question of opinion), but one item really got my attention because I completely disagree - When talking about Objects and Data Structures, there's this conclusion:
"Procedural code makes it hard to add new data structures because all the functions must change. OO code makes it hard to add new functions because all the classes must change."
And that entire idea is presented in a way that makes data structures tied to procedural code and OO (Object Oriented) code incapable of dealing with data structures, being forced to use "full objects" all the time. Well, this article is about using Data Structures with Object Oriented Programming and making it possible to add new data structures without having to change all functions and to add new functions without having to change all data structures.
The (Bad) Examples
The examples in the book are more or less like the ones that follow. It is important to note that I am writing this from what I remember and I am using C# instead of Java, so it is natural that it looks different, yet I keep the idea of what "procedural" and "object oriented" mean:
Procedural
public class Square
{
public double Left { get; set; }
public double Top { get; set; }
public double Side { get; set; }
}
public class Rectangle
{
public double Left { get; set; }
public double Top { get; set; }
public double Width { get; set; }
public double Height { get; set; }
}
public class Circle
{
public double CenterX { get; set; }
public double CenterY { get; set; }
public double Radius { get; set; }
}
public static class Geometry
{
public static double GetArea(object shape)
{
if (shape is Rectangle)
{
Rectangle rectangle = (Rectangle)shape;
return rectangle.Width * rectangle.Height;
}
if (shape is Square)
{
Square square = (Square)shape;
return square.Side * square.Side;
}
if (shape is Circle)
{
Circle circle = (Circle)shape;
return Math.PI * circle.Radius * circle.Radius;
}
throw new ArgumentException("Unknown shape type.", "shape");
}
}
Object Oriented
public interface IShape
{
double Area { get; }
}
public class Square:
IShape
{
public double Left { get; set; }
public double Top { get; set; }
public double Side { get; set; }
public double Area
{
get
{
return Side * Side;
}
}
}
public class Rectangle:
IShape
{
public double Left { get; set; }
public double Top { get; set; }
public double Width { get; set; }
public double Height { get; set; }
public double Area
{
get
{
return Width * Height;
}
}
}
public class Circle:
IShape
{
public double CenterX { get; set; }
public double CenterY { get; set; }
public double Radius { get; set; }
public double Area
{
get
{
return Math.PI * Radius * Radius;
}
}
}
What these blocks of code try to show is that in the "procedural" version, the shapes don't need to implement any interface and don't have any methods, so we can create as many functions as needed in separate classes without ever touching the existing three shapes. Unfortunately, if we add a new shape, we will need to change all the existing functions.
The "object oriented" version works in an opposite manner, forcing all shapes to change if new methods or properties are added to the IShape while allowing new shapes to be added without having to change any existing code.
The Shared Problem - Violation of the Open/Closed Principle
Imagine that we have created two DLLs. One is made in the procedural manner and one is made in the (bad) object oriented manner. Our purpose is to create an application that uses one of the libraries and adds the following traits (in the application, without changing the library code):
- A
Draw() method (or function, if you prefer) capable of drawing the existing shapes - A
Triangle shape (we must not forget that it should be drawn too)
Which one of the libraries allows you to do this without breaking the existing classes/functions?
And the answer is: None. This is a violation of the Open/Closed Principle, which states that software entities should be open for extension but closed for modification.
If we use the procedural library, we will not be able to add a Triangle class and use the Geometry.GetArea() "function". If we use the object oriented library, we will not be able to add a Draw() method to the IShape, as to do that, we should change the library itself.
So, is it possible to write a library that allows new shapes and "functions" to be added by the applications without breaking the already existing shapes and functions present in the library (and so, respect the Open/Closed Principle)?
The answer: Well, I will present it near the end of this article. Now I will continue with "fake solutions".
Work-arounds and Pseudo-solutions
I can say that there are many "pseudo-solutions". For example, we can take the object oriented library, add the Triangle shape and then create a procedural Draw() function in another class. We will end-up with something that works but that's not beautiful, as the Area will be part of the shape while the Draw will exist elsewhere. Then, if we want to add even more shapes, we will need to remember that some methods are part of the shape and that some methods are "elsewhere".
We could also take the procedural library, add the new shape and then create an AppGeometry class with a Draw() method that supports all the shapes plus a GetArea() method supporting the Triangle and redirecting to the Geometry.GetArea() for the other shapes. This solution will work great if all the calls to the GetArea() come from the application, but it will fail with the Triangle if there are other methods in the library that already depend on the Geometry.GetArea().
But let's take the problem one step further. What will happen if our purpose was to have a library of base shapes and functions, then another library with complex shapes and more functions and we still wanted to allow applications to add their own shapes and functions? Note that the solution over the object oriented library used a procedural Draw() while the procedural library already has restrictions.
Expandable Procedural Code
We can solve the procedural code by making it expandable. Yet, remember that this is not the final solution, as my purpose is to present an object oriented one.
Imagine that in the procedural library, the code of the Geometry class was like the following instead of the previously presented one:
public static class Geometry
{
public static double GetArea(object shape)
{
if (shape is Rectangle)
{
Rectangle rectangle = (Rectangle)shape;
return rectangle.Width * rectangle.Height;
}
if (shape is Square)
{
Square square = (Square)shape;
return square.Side * square.Side;
}
if (shape is Circle)
{
Circle circle = (Circle)shape;
return Math.PI * circle.Radius * circle.Radius;
}
var gettingArea = GettingArea;
if (gettingArea != null)
{
foreach(Func<object, double> func in gettingArea.GetInvocationList())
{
double possibleResult = func(shape);
if (possibleResult >= 0)
return possibleResult;
}
}
throw new ArgumentException("Unknown shape type.", "shape");
}
public static event Func<object, double> GettingArea;
}
Having the library written like this, we would be able to add new shapes in our application and still call the Geometry.GetArea() method for the new shapes. We will not need to call a different method and so, any calls made in the library itself (or in another library) to the Geometry.GetArea() would be able to support the new shape. It would be enough to register new handlers in the event GettingArea event.
The problem with this approach is the "bad pattern" it may cause if we have many, many different shapes. If we add one handler per shape, it will become slow for those shapes found "in the end" of the calls. Using a single delegate with tests per type will be a little faster, but will still share the problem and, even if it is possible to make a clever algorithm in the handler, that clever algorithm is what we should have to start with... so, let's go to the solution.
Data Structures + Functions as "Container of Delegates"
Now let's break the concept that data structures are procedural and that object oriented requires "functions" to be part of the object. We can use data structures and "attach" functions to them. See the following code:
public static class ShapeAreaGetter
{
private static readonly ConcurrentDictionary<Type, Func<object, double>> _dictionary =
new ConcurrentDictionary<Type, Func<object, double>>();
public static void Register<T>(Func<T, double> func)
{
if (func == null)
throw new ArgumentNullException("func");
if (!_dictionary.TryAdd(typeof(T), (shape) => func((T)shape)))
throw new InvalidOperationException(
"An area getter function was already registered for the given data-type.");
}
public static double GetArea(object shape)
{
if (shape == null)
throw new ArgumentNullException("shape");
Type type = shape.GetType();
Func<object, double> func;
_dictionary.TryGetValue(type, out func);
if (func == null)
throw new InvalidOperationException(
"There's no area getter registered for the given shape's type.");
return func(shape);
}
}
With this solution, we can add as many shapes as we want and we will be able to get the area of those shapes as long as we register the "AreaGetters". This can be done in any application without having to change the code of the ShapeAreaGetter class. I am not calling it Geometry on purpose as we can add many "Geometry" functions in their own classes, so it is better to use more specific names. We can also add any function, even not related to geometry, like Draw(), by using a code very similar to this one. That is, we may have a "pattern" to add functions. The code for the Draw() could look like this:
public static class ShapeDrawer
{
private static readonly ConcurrentDictionary<Type, Action<object, DrawingContext>> _dictionary =
new ConcurrentDictionary<Type, Action<object, DrawingContext>>();
public static void Register<T>(Action<T, DrawingContext> action)
{
if (action == null)
throw new ArgumentNullException("action");
if (!_dictionary.TryAdd(typeof(T), (shape, drawingContext) => action((T)shape, drawingContext)))
throw new InvalidOperationException(
"A drawer action was already registered for the given data-type.");
}
public static void Draw(object shape, DrawingContext drawingContext)
{
if (shape == null)
throw new ArgumentNullException("shape");
if (drawingContext == null)
throw new ArgumentNullException("drawingContext");
Type type = shape.GetType();
Action<object, DrawingContext> action;
_dictionary.TryGetValue(type, out action);
if (action == null)
throw new InvalidOperationException(
"There's no shape drawer registered for the given shape's type.");
action(shape, drawingContext);
}
}
It is important to note that these classes may live or may not live in the library, yet it would be possible to expand them at run-time by the application that uses them. So, to keep the idea that the Draw method exists only in the application while the GetArea is part of the library, consider that only the AreaGetter class is part of the library. We surely need to have the basic shapes in the library, which are exactly the same as the ones used in the procedural example, and we need to register the area getters for them during initialization, but that's all.
Problems in the New Solution?
The new solution is fully functional. It will work pretty fast even if we add incredibles amounts of shapes as the ConcurrentDictionary insertion and lookup is O(1) (constant time) in most situations. The shapes and the functions can be added without problems, independently if we can't change the library anymore, as the solution is expandable at run-time. Yet, there are some things that aren't perfect yet:
- We can't do
shape.Draw() or shape.GetArea(). We need to do ShapeAreaGetter.GetArea(shape) or ShapeDrawer.Draw(shape). - There's nothing telling us what are the "available functions" for a shape and there's nothing forbidding us to give random objects (like a
string or an int) to the ShapeAreaGetter.GetArea() method. - Adding a new function is a relatively long pattern, requiring a new class every time;
- We still need to write delegates for all the shape/functions combinations or we will have run-time exceptions.
- Finally, when should we register the default functions that come with the library?
The first two problems may be solved by using an IShape interface and extension methods. Such interface doesn't need to have any methods but the Draw(), GetArea() or any other extension method can be created for that type instead of using object. It is actually possible to add extension methods to the object class, but I don't think it is a good idea to be so generic, as such methods will then appear for absolutely anything.
The third item is almost impossible to solve. We may create a helper class with most of the logic, but it will become a helper class full of generic arguments and in the end, we will still need a pattern to use this class, creating new classes and doing redirections. Yet, we must remember that dependency properties with value coercions have a big pattern too, yet people get used to it.
The fourth item is a problem in any solution. If all the functions are going to be supported by all the shapes, then we need to implement them all anyway. At least this solution allows new functions and shapes to be added in the final application without requiring the libraries to be modifed.
The last problem is actually a problem in C#. C# doesn't allow us to create module initialization functions, which will be the ideal place to register the default functions for the shapes provided in the library. This is a C# limitation, as the .NET itself allows this and none of the work-arounds are really clean. Or we create "initialization methods" that must be invoked before using the library, or we register the actions for the default shapes in static constructors presents either in the shapes or in the "function classes" (the ShapeAreaGetter and ShapeDrawer) (or we can even put an extra logic in them to find for "default implementations" in specific namespaces or the like).
The Sample
new Circle { CenterX = 20, CenterY = 20, Radius=9 },
new Square { Left = 200, Top = 10, Side=50 },
new Rectangle { Left = 200, Top = 200, Width=35, Height=77 },
new Triangle { X1=100, Y1=100, X2=120, Y2=157, X3=10, Y3=150 },
new TextInfo { FontName="Arial", FontSize=14, Left=120, Top=100, Text="Hello world!" }
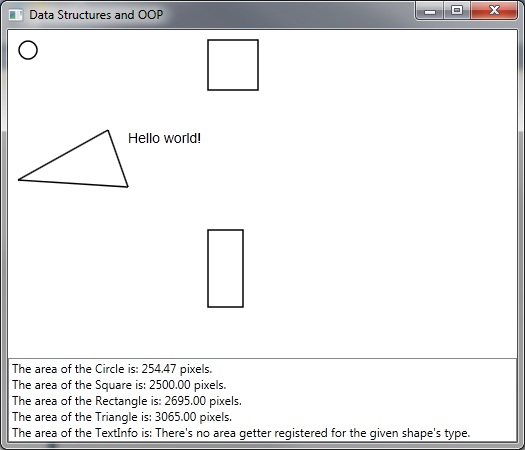
I made the sample application to show that the basic code exists in a library, it is extended by another library and further extended by the application and the calls to the first library are still capable of dealing with the objects created in the second library and the application.
I used a solution with extension methods + the IShape interface, so it is possible to see all the "functions" as if they were instance methods. Each Drawer and AreaGetter is in a separate class, but actually it is possible to put many in the same class. When initializing the libraries, all those methods are registered using reflection. This is good because new AreaGetters and Drawers may be added without having to touch the code that registers them.
I didn't implement an AreaGetter for the TextInfo (which presents the "Hello world!") to show that it is still possible to compile the application when not all methods are implemented, so you can really implement things independently (the shape, the area getter and the drawer).
The application display the shapes and has a list that presents their areas. It is not animated or anything like that, simply because this is not the purpose of the application.
When Should We Use This Pattern?
In my opinion, in any code that we are writing and thinking about using a switch. Yet, as happens with many patterns related to maintainability, we may not need to use it in the final application, as extensions to the application usually require the application to change anyway, and it is probably too much to find all the switches in existing applications to replace them by the presented pattern.
So, in new code, it is good to get used to this pattern. In old code, if we are already facing maintainability problems, we should try to use the pattern. If we are not facing problems, we should let the switches there and focus on more important problems first.

