Background
This article is based on Chapter 5 of my book, Writing High-Performance .NET Code.
This article references some tools to help measure and diagnose performance issues, specifically PerfView, MeasureIt, and ILSpy (or an IL reflection tool of your choice). For a good introduction to using these tools, please see here [PDF].
Introduction
This article covers general coding and type design principles. .NET contains features for many scenarios and while many of them are at worst performance-neutral, some are decidedly harmful to good performance. Others are neither good nor bad, just different, and you must decide what the right approach in a given situation is.
If I were to summarize a single principle that will show up throughout this article, it is:
In-depth performance optimization will often defy code abstractions.
This means that when trying to achieve extremely good performance, you will need to understand and possibly rely on the implementation details at all layers. Many of those are described in this article.
Class vs. Struct
Instances of a class are always allocated on the heap and accessed via a pointer dereference. Passing them around is cheap because it is just a copy of the pointer (4 or 8 bytes). However, an object also has some fixed overhead: 8 bytes for 32-bit processes and 16 bytes for 64-bit processes. This overhead includes the pointer to the method table and a sync block field. If you made an object with no fields and looked at it in the debugger, you would notice that its size is actually 12 bytes, not 8. For 64-bit processes, the object would be 24 bytes. This is because the minimum size is based on alignment. Thankfully, this "extra" 4 bytes of space will be used by a field.
A struct has no overhead at all and its memory usage is a sum of the size of all its fields. If a struct is declared as a local variable in a method, then the struct is allocated on the stack. If the struct is declared as part of a class, then the struct’s memory will be part of that class’s memory layout (and thus exist on the heap). When you pass a struct to a method, it is copied byte for byte. Because it is not on the heap, allocating a struct will never cause a garbage collection.
There is thus a tradeoff here. You can find various pieces of advice about the maximum recommended size of a struct, but I would not get caught up on the exact number. In most cases, you will want to keep struct sizes very small, especially if they are passed around, but you can also pass structs by reference so the size may not be an important issue to you. The only way to know for sure whether it benefits you is to consider your usage pattern and do your own profiling.
There is a huge difference in efficiency in some cases. While the overhead of an object might not seem like very much, consider an array of objects and compare it to an array of structs. Assume the data structure contains 16 bytes of data, the array length is 1,000,000, and this is a 32-bit system.
For an array of objects, the total space usage is:
12 bytes array overhead +
(4 byte pointer size × 1,000,000) +
((8 bytes overhead + 16 bytes data) × 1,000,000)
= 28 MB
For an array of structs, the results are dramatically different:
12 bytes array overhead +
(16 bytes data × 1,000,000)
= 16 MB
With a 64-bit process, the object array takes over 40 MB while the struct array still requires only 16 MB.
As you can see, in an array of structs, the same size of data takes less amount of memory. With the overhead of objects, you are also inviting a higher rate of garbage collections just from the added memory pressure.
Aside from space, there is also the matter of CPU efficiency. CPUs have multiple levels of caches. Those closest to the processor are very small, but extremely fast and optimized for sequential access.
An array of structs has many sequential values in memory. Accessing an item in the struct array is very simple. Once the correct entry is found, the right value is there already. This can mean a huge difference in access times when iterating over a large array. If the value is already in the CPU’s cache, it can be accessed an order of magnitude faster than if it were in RAM.
To access an item in the object array requires an access into the array’s memory, then a dereference of that pointer to the item elsewhere in the heap. Iterating over object arrays dereferences an extra pointer, jumps around in the heap, and evicts the CPU’s cache more often, potentially squandering more useful data.
This lack of overhead for both CPU and memory is a prime reason to favor structs in many circumstances—it can buy you significant performance gains when used intelligently because of the improved memory locality.
Because structs are always copied by value, you can create some interesting situations for yourself if you are not careful. For example, see this buggy code which will not compile:
struct Point
{
public int x;
public int y;
}
public static void Main()
{
List<Point> points = new List<Point>();
points.Add(new Point() { x = 1, y = 2 });
points[0].x = 3;
}
The problem is the last line, which attempts to modify the existing Point in the list. This is not possible because calling points[0] returns a copy of the original value, which is not stored anywhere permanent. The correct way to modify the Point is:
Point p = points[0];
p.x = 3;
points[0] = p;
However, it may be wise to adopt an even more stringent policy: make your structs immutable. Once created, they can never change value. This removes the above situation from even being a possibility and generally simplifies struct usage.
I mentioned earlier that structs should be kept small to avoid spending significant time copying them, but there are occasional uses for large structs. Consider an object that tracks a lot of details of some commercial process, such as a lot of time stamps.
class Order
{
public DateTime ReceivedTime {get;set;}
public DateTime AcknowledgeTime {get;set;}
public DateTime ProcessBeginTime {get;set;}
public DateTime WarehouseReceiveTime {get;set;}
public DateTime WarehouseRunnerReceiveTime {get;set;}
public DateTime WarehouseRunnerCompletionTime {get;set;}
public DateTime PackingBeginTime {get;set;}
public DateTime PackingEndTime {get;set;}
public DateTime LabelPrintTime {get;set;}
public DateTime CarrierNotifyTime {get;set;}
public DateTime ProcessEndTime {get;set;}
public DateTime EmailSentToCustomerTime {get;set;}
public DateTime CarrerPickupTime {get;set;}
}
To simplify your code, it would be nice to segregate all of those times into their own sub-structure, still accessible via the Order class via some code like this:
Order order = new Order();
Order.Times.ReceivedTime = DateTime.UtcNow;
You could put all of them into their own class.
class OrderTimes
{
public DateTime ReceivedTime {get;set;}
public DateTime AcknowledgeTime {get;set;}
public DateTime ProcessBeginTime {get;set;}
public DateTime WarehouseReceiveTime {get;set;}
public DateTime WarehouseRunnerReceiveTime {get;set;}
public DateTime WarehouseRunnerCompletionTime {get;set;}
public DateTime PackingBeginTime {get;set;}
public DateTime PackingEndTime {get;set;}
public DateTime LabelPrintTime {get;set;}
public DateTime CarrierNotifyTime {get;set;}
public DateTime ProcessEndTime {get;set;}
public DateTime EmailSentToCustomerTime {get;set;}
public DateTime CarrerPickupTime {get;set;}
}
class Order
{
public OrderTimes Times;
}
However, this does introduce an additional 12 or 24-bytes of overhead for every Order object. If you need to pass the OrderTimes object as a whole to various methods, maybe this makes sense, but why not just pass the reference to the entire Order object itself? If you have thousands of Order objects being processed simultaneously, this can cause more garbage collections to be induced. It is also an extra memory dereference.
Instead, change OrderTimes to be a struct. Accessing the individual properties of the OrderTimes struct via a property on Order (e.g., order.Times.ReceivedTime) will not result in a copy of the struct (.NET optimizes that reasonable scenario). This way, the OrderTimes struct becomes essentially part of the memory layout for the Order class almost exactly like it was with no substructure and you get to have better-looking code as well.
This technique does violate the principle of immutable structs, but the trick here is to treat the fields of the OrderTimes struct just as if they were fields on the Order object. You do not need to pass around the OrderTimes struct as an entity in and of itself—it is just an organization mechanism.
Override Equals and GetHashCode for Structs
An extremely important part of using structs is overriding the Equals and GetHashCode methods. If you don’t, you will get the default versions, which are not at all good for performance. To get an idea of how bad it is, use an IL viewer and look at the code for the ValueType.Equals method. It involves reflection over all the fields in the struct. There is, however, an optimization for blittable types. A blittable type is one that has the same in-memory representation in managed and unmanaged code. They are limited to the primitive numeric types (such as Int32, UInt64, for example, but not Decimal, which is not a primitive) and IntPtr/UIntPtr. If a struct is comprised of all blittable types, then the Equals implementation can do the equivalent of byte-for-byte memory compare across the whole struct. Just avoid this uncertainty and implement your own Equals method.
If you just override Equals(object other), then you are still going to have worse performance than necessary, because that method involves casting and boxing on value types. Instead, implement Equals(T other), where T is the type of your struct. This is what the IEquatable<T> interface is for, and all structs should implement it. During compilation, the compiler will prefer the more strongly typed version whenever possible. The following code snippet shows you an example.
struct Vector : IEquatable<Vector>
{
public int X { get; set; }
public int Y { get; set; }
public int Z { get; set; }
public int Magnitude { get; set; }
public override bool Equals(object obj)
{
if (obj == null)
{
return false;
}
if (obj.GetType() != this.GetType())
{
return false;
}
return this.Equals((Vector)obj);
}
public bool Equals(Vector other)
{
return this.X == other.X
&& this.Y == other.Y
&& this.Z == other.Z
&& this.Magnitude == other.Magnitude;
}
public override int GetHashCode()
{
return X ^ Y ^ Z ^ Magnitude;
}
}
If a type implements IEquatable<T> .NET’s generic collections will detect its presence and use it to perform more efficient searches and sorts.
You may also want to implement the == and != operators on your value types and have them call the existing Equals(T) method.
Even if you never compare structs or put them in collections, I still encourage you to implement these methods. You will not always know how they will be used in the future and the price of the methods is only a few minutes of your time and a few bytes of IL that will never even get JITted.
It is not as important to override Equals and GetHashCode on classes because by default they only calculate equality based on their object reference. As long as that is a reasonable assumption for your objects, you can leave them as the default implementation.
Virtual Methods and Sealed Classes
Do not mark methods virtual by default, “just in case.” However, if virtual methods are necessary for a coherent design in your program, you probably should not go too far out of your way to remove them.
Making methods virtual prevents certain optimizations by the JIT compiler, notably the ability to inline them. Methods can only be inlined if the compiler knows 100% which method is going to be called. Marking a method as virtual removes this certainty, though there are other factors that are perhaps more likely to invalidate this optimization.
Closely related to virtual methods is the notion of sealing a class, like this:
public sealed class MyClass {}
A class marked as sealed is declaring that no other classes can derive from it. In theory, the JIT could use this information to inline more aggressively, but it does not do so currently. Regardless, you should mark classes as sealed by default and not make methods virtual unless they need to be. This way, your code will be able to take advantage of any current as well as theoretical future improvements in the JIT compiler.
If you are writing a class library that is meant to be used in a wide variety of situations, especially outside of our organization, you need to be more careful. In that case, having virtual APIs may be more important than raw performance to ensure your library is sufficiently reusable and customizable. But for code that you change often and is used only internally, go the route of better performance.
Interface Dispatch
The first time you call a method through an interface, .NET has to figure out which type and method to make the call on. It will first make a call to a stub that finds the right method to call for the appropriate object implementing that interface. Once this happens a few times, the CLR will recognize that the same concrete type is always being called and this indirect call via the stub is reduced to a stub of just a handful of assembly instructions that makes a direct call to the correct method. This group of instructions is called a monomorphic stub because it knows how to call a method for a single type. This is ideal for situations where a call site always calls interface methods on the same type every time.
The monomorphic stub can also detect when it is wrong. If, at some point the call site uses an object of a different type, then eventually the CLR will replace the stub with another monomorphic stub for the new type.
If the situation is even more complex with multiple types and less predictability (for example, you have an array of an interface type, but there are multiple concrete types in that array) then the stub will be changed to a polymorphic stub that uses a hash table to pick which method to call. The table lookup is fast, but not as fast as the monomorphic stub. Also, this hash table is severely bounded in size and if you have too many types, you might fall back to the generic type lookup code from the beginning. This can be very expensive.
If this becomes a concern for you, you have a couple of options:
- Avoid calling these objects through the common interface
- Pick your common base interface and replace it with an
abstract base class instead
This type of problem is not common, but it can hit you if you have a huge type hierarchy, all implementing a common interface, and you call methods through that root interface. You would notice this as high CPU usage at the call site for these methods that cannot be explained by the work the methods are doing.
Story During the design of a large system, we knew we were going to have potentially thousands of types that would likely all descend from a common type. We knew there would be a couple of places where we would need to access them from the base type. Because we had someone on the team who understood the issues around interface dispatch with this magnitude of problem size, we chose to use an abstract base class rather than a root interface instead.
To learn more about interface dispatch, see Vance Morrison’s blog entry on the subject at.
Avoid Boxing
Boxing is the process of wrapping a value type such as a primitive or struct inside an object that lives on the heap so that it can be passed to methods that require object references. Unboxing is getting the original value back out again.
Boxing costs CPU time for object allocation, copying, and casting, but, more seriously, it results in more pressure on the GC heap. If you are careless about boxing, it can lead to a significant number of allocations, all of which the GC will have to handle.
Obvious boxing happens whenever you do things like the following:
int x = 32;
object o = x;
The IL looks like this:
IL_0001: ldc.i4.s 32
IL_0003: stloc.0
IL_0004: ldloc.0
IL_0005: box [mscorlib]System.Int32
IL_000a: stloc.1
This means that it is relatively easy to find most sources of boxing in your code—just use ILDASM to convert all of your IL to text and do a search.
A very common of way of having accidental boxing is using APIs that take object or object[] as a parameter, the most obvious of which is String.Format or the old style collections which only store object references and should be avoided completely for this and other reasons.
Boxing can also occur when assigning a struct to an interface, for example:
interface INameable
{
string Name { get; set; }
}
struct Foo : INameable
{
public string Name { get; set; }
}
void TestBoxing()
{
Foo foo = new Foo() { Name = "Bar" };
INameable nameable = foo;
...
}
If you test this out for yourself, be aware that if you do not actually use the boxed variable, then the compiler will optimize out the boxing instruction because it is never actually touched. As soon as you call a method or otherwise use the value, then the boxing instruction will be present.
Another thing to be aware of when boxing occurs is the result of the following code:
int val = 13;
object boxedVal = val;
val = 14;
What is the value of boxedVal after this?
Boxing copies the value and there is no longer any relationship between the two values. In this example, val changes value to 14, but boxedVal maintains its original value of 13.
You can sometimes catch boxing happening in a CPU profile, but many boxing calls are inlined so this is not a reliable method of finding it. What will show up in a CPU profile of excessive boxing is heavy memory allocation through new.
If you do have a lot of boxing of structs and find that you cannot get rid of it, you should probably just convert the struct to a class, which may end up being cheaper overall.
Finally, note that passing a value type by reference is not boxing. Examine the IL and you will see that no boxing occurs. The address of the value type is sent to the method.
for vs. foreach
Use the MeasureIt program described in the Background section to see for yourself the difference in iterating collections using for loops or foreach. Using standard for loops is significantly faster in all the cases. However, if you do your own simple test, you might notice equivalent performance depending on the scenario. In many cases, .NET will actually convert simple foreach statements into standard for loops.
Take a look at the ForEachVsFor sample project, which has this code:
int[] arr = new int[100];
for (int i = 0; i < arr.Length; i++)
{
arr[i] = i;
}
int sum = 0;
foreach (int val in arr)
{
sum += val;
}
sum = 0;
IEnumerable<int> arrEnum = arr;
foreach (int val in arrEnum)
{
sum += val;
}
Once you build this, then decompile it using an IL reflection tool. You will see that the first foreach is actually compiled as a for loop. The IL looks like this:
IL_0024: ldloc.s CS$6$0000
IL_0026: ldloc.s CS$7$0001
IL_0028: ldelem.i4
IL_0029: stloc.3
IL_002a: ldloc.2
IL_002b: ldloc.3
IL_002c: add
IL_002d: stloc.2
IL_002e: ldloc.s CS$7$0001
IL_0030: ldc.i4.1
IL_0031: add
IL_0032: stloc.s CS$7$0001
IL_0034: ldloc.s CS$7$0001
IL_0036: ldloc.s CS$6$0000
IL_0038: ldlen
IL_0039: conv.i4
IL_003a: blt.s IL_0024
There are a lot of stores, loads, adds, and a branch—it is all quite simple. However, once we cast the array to an IEnumerable<int> and do the same thing, it gets a lot more expensive:
IL_0043: callvirt instance class [mscorlib]System.Collections.Generic.IEnumerator`1<!0> class [mscorlib]System.Collections.Generic.IEnumerable`1<int32>::GetEnumerator()
IL_0048: stloc.s CS$5$0002
.try
{
IL_004a: br.s IL_005a
IL_004c: ldloc.s CS$5$0002
IL_004e: callvirt instance !0 class [mscorlib]System.Collections.Generic.IEnumerator`1<int32>::get_Current()
IL_0053: stloc.s val
IL_0055: ldloc.2
IL_0056: ldloc.s val
IL_0058: add
IL_0059: stloc.2
IL_005a: ldloc.s CS$5$0002
IL_005c: callvirt instance bool [mscorlib]System.Collections.IEnumerator::MoveNext()
IL_0061: brtrue.s IL_004c
IL_0063: leave.s IL_0071
}
finally
{
IL_0065: ldloc.s CS$5$0002
IL_0067: brfalse.s IL_0070
IL_0069: ldloc.s CS$5$0002
IL_006b: callvirt instance void [mscorlib]System.IDisposable::Dispose()
IL_0070: endfinally
}
We have 4 virtual method calls, a try-finally, and, not shown here, a memory allocation for the local enumerator variable which tracks the enumeration state. That is much more expensive than the simple for loop. It uses more CPU and more memory!
Remember, the underlying data structure is still an array—a for loop is possible—but we are obfuscating that by casting to an IEnumerable. The important lesson here is the one that was mentioned at the top of the article: In-depth performance optimization will often defy code abstractions. foreach is an abstraction of a loop, and IEnumerable is an abstraction of a collection. Combined, they dictate behavior that defies the simple optimizations of a for loop over an array.
Casting
In general, you should avoid casting wherever possible. Casting often indicates poor class design, but there are times when it is required. It is relatively common to need to convert between unsigned and signed integers between various third-party APIs, for example. Casting objects should be much rarer.
Casting objects is never free, but the costs differ dramatically depending on the relationship of the objects. Casting an object to its parent is relatively cheap. Casting a parent object to the correct child is significantly more expensive, and the costs increase with a larger hierarchy. Casting to an interface is more expensive than casting to a concrete type.
What you absolutely must avoid is an invalid cast. This will cause an InvalidCastException exception to be thrown, which will dwarf the cost of the actual cast by many orders of magnitude.
See the CastingPerf sample project in the accompanying source code which benchmarks a number of different types of casts. It produces this output on my computer in one test run:
JIT (ignore): 1.00x
No cast: 1.00x
Up cast (1 gen): 1.00x
Up cast (2 gens): 1.00x
Up cast (3 gens): 1.00x
Down cast (1 gen): 1.25x
Down cast (2 gens): 1.37x
Down cast (3 gens): 1.37x
Interface: 2.73x
Invalid Cast: 14934.51x
as (success): 1.01x
as (failure): 2.60x
is (success): 2.00x
is (failure): 1.98x
The ‘is’ operator is a cast that tests the result and returns a Boolean value. The ‘as’ operator is similar to a standard cast, but returns null if the cast fails. From the results above, you can see this is much faster than throwing an exception.
Never have this pattern, which performs two casts:
if (a is Foo)
{
Foo f = (Foo)a;
}
Instead, use ‘as’ to cast and cache the result, then test the return value:
Foo f = a as Foo;
if (f != null)
{
...
}
If you have to test against multiple types, then put the most common type first.
Note: One annoying cast that I see regularly is when using MemoryStream.Length, which is a long. Most APIs that use it are using the reference to the underlying buffer (retrieved from the MemoryStream.GetBuffer method), an offset, and a length, which is often an int, thus making a downcast from long necessary. Casts like these can be common and unavoidable.
P/Invoke
P/Invoke is used to make calls from managed code into native methods. It involves some fixed overhead plus the cost of marshalling the arguments. Marshalling is the process of converting types from one format to another.
You can see a simple benchmark of P/Invoke cost vs. a normal managed function call cost with the MeasureIt program mentioned at the top of the article. On my computer, a P/Invoke call takes about 6-10 times the amount of time it takes to call an empty static method. You do not want to call a P/Invoked method in a tight loop if you have a managed equivalent, and you definitely want to avoid making multiple transitions between native and managed code. However, a single P/Invoke calls is not so expensive as to prohibit it in all cases.
There are a few ways to minimize the cost of making P/Invoke calls:
- First, avoid having a “chatty” interface. Make a single call that can work on a lot of data, where the time spent processing the data is significantly more than the fixed overhead of the P/Invoke call.
- Use blittable types as much as possible. Recall from the discussion about
structs that blittable types are those that have the same binary value in managed and native code, mostly numeric and pointer types. These are the most efficient arguments to pass because the marshalling process is basically a memory copy. - Avoid calling ANSI versions of Windows APIs. For example, the
CreateProcess function is actually a macro that resolves to one of two real functions, CreateProcessA for ANSI strings, and CreateProcessW for Unicode strings. Which version you get is determined by the compilation settings for the native code. You want to ensure that you are always calling the Unicode versions of APIs because all .NET strings are already Unicode, and having a mismatch here will cause an expensive, possibly lossy, conversion to occur. - Don’t pin unnecessarily. Primitives are never pinned anyway and the marshalling layer will automatically pin strings and arrays of primitives. If you do need to pin something else, keep the object pinned for as short a duration as possible to. With pinning, you will have to balance this need for a short duration with the first recommendation of avoiding chatty interfaces. In all cases, you want the native code to return as fast as possible.
- If you need to transfer a large amount of data to native code, consider pinning the buffer and having the native code operate on it directly. It does pin the buffer in memory, but if the function is fast enough this may be more efficient than a large copy operation. If you can ensure that the buffer is in gen 2 or the large object heap, then pinning is much less of an issues because the GC is unlikely to need to move the object anyway.
Finally, you can reduce some of the cost of P/Invoke by disabling some security checks on the P/Invoke method declarations.
[DllImport("kernel32.dll", SetLastError=true)]
[System.Security.SuppressUnmanagedCodeSecurity]
static extern bool GetThreadTimes(IntPtr hThread, out long lpCreationTime, out long lpExitTime, out long lpKernelTime, out long lpUserTime);
This attribute declares that the method can run with full trust. This will cause you to receive some Code Analysis (FxCop) warnings because it is disabling a large part of .NET’s security model. However, if your application runs only trusted code, you sanitize the inputs, and you prevent public APIs from calling the P/Invoke methods, then it can gain you some performance, as demonstrated in this MeasureIt output:
| Name | Mean |
| PInvoke: 10 FullTrustCall() (10 call average) [count=1000 scale=10.0] | 6.945 |
| PInvoke: PartialTrustCall() (10 call average) [count=1000 scale=10.0] | 17.778 |
The method running with full trust can execute about 2.5 times faster.
Delegates
There are two costs associated with use of delegates: construction and invocation. Invocation, thankfully, is comparable to a normal method call in nearly all circumstances, but delegates are objects and constructing them can be quite expensive. You want to pay this cost only once and cache the result. Consider the following code:
private delegate int MathOp(int x, int y);
private static int Add(int x, int y) { return x + y; }
private static int DoOperation(MathOp op, int x, int y) { return op(x, y); }
Which of the following loops is faster?
Option 1
for (int i = 0; i < 10; i++)
{
DoOperation(Add, 1, 2);
}
Option 2
MathOp op = Add;
for (int i = 0; i < 10; i++)
{
DoOperation(op, 1, 2);
}
It looks like Option 2 is only aliasing the Add function with a local delegate variable, but this actually involves a memory allocation! It becomes clear if you look at the IL for the respective loops:
Option 1
IL_0004: ldnull
IL_0005: ldftn int32 DelegateConstruction.Program::Add(int32, int32)
IL_000b: newobj instance void DelegateConstruction.Program/MathOp::.ctor(object, native int)
IL_0010: ldc.i4.1
IL_0011: ldc.i4.2
IL_0012: call int32 DelegateConstruction.Program::DoOperation(class DelegateConstruction.Program/MathOp, int32, int32)
...
While Option 2 has the same memory allocation, but it is outside of the loop:
L_0025: ldnull
IL_0026: ldftn int32 DelegateConstruction.Program::Add(int32, int32)
IL_002c: newobj instance void DelegateConstruction.Program/MathOp::.ctor(object, native int)
...
IL_0036: ldloc.1
IL_0037: ldc.i4.1
IL_0038: ldc.i4.2
IL_0039: call int32 DelegateConstruction.Program::DoOperation(class DelegateConstruction.Program/MathOp, int32, int32)
...
These examples can be found in the DelegateConstruction sample project.
Exceptions
In .NET, putting a try block around code is cheap, but exceptions are very expensive to throw. This is largely because of the rich state that .NET exceptions contain. Exceptions must be reserved for truly exceptional situations, when raw performance ceases to be important.
To see the devastating effects on performance that throwing exceptions can have, see the ExceptionCost sample project. Its output should be similar to the following:
Empty Method: 1x
Exception (depth = 1): 8525.1x
Exception (depth = 2): 8889.1x
Exception (depth = 3): 8953.2x
Exception (depth = 4): 9261.9x
Exception (depth = 5): 11025.2x
Exception (depth = 6): 12732.8x
Exception (depth = 7): 10853.4x
Exception (depth = 8): 10337.8x
Exception (depth = 9): 11216.2x
Exception (depth = 10): 10983.8x
Exception (catchlist, depth = 1): 9021.9x
Exception (catchlist, depth = 2): 9475.9x
Exception (catchlist, depth = 3): 9406.7x
Exception (catchlist, depth = 4): 9680.5x
Exception (catchlist, depth = 5): 9884.9x
Exception (catchlist, depth = 6): 10114.6x
Exception (catchlist, depth = 7): 10530.2x
Exception (catchlist, depth = 8): 10557.0x
Exception (catchlist, depth = 9): 11444.0x
Exception (catchlist, depth = 10): 11256.9x
This demonstrates three simple facts:
- A method that throws an exception is thousands of time slower than a simple empty method.
- The deeper the stack for the thrown exception, the slower it gets (though it is already so slow, it doesn’t matter).
- Having multiple
catch statements has a slight but significant effect as the right one needs to be found.
On the flip side, while catching exceptions may be cheap, accessing the StackTrace property on an Exception object can be very expensive as it reconstructs the stack from pointers and translates it into readable text. In a high-performance application, you may want to make logging of these stack traces optional through configuration and use it only when needed.
To reiterate: exceptions should be truly exceptional. Using them as a matter of course can destroy your performance.
Dynamic
It should probably go without saying, but to make it explicit: any code using the dynamic keyword, or the Dynamic Language Runtime (DLR) is not going to be highly optimized. Performance tuning is often about stripping away abstractions, but using the DLR is adding one huge abstraction layer. It has its place, certainly, but a fast system is not one of them.
When you use dynamic, what looks like straightforward code is anything but. Take a simple, admittedly contrived example:
static void Main(string[] args)
{
int a = 13;
int b = 14;
int c = a + b;
Console.WriteLine(c);
}
The IL for this is equally straightforward:
.method private hidebysig static
void Main (
string[] args
) cil managed
{
.maxstack 2
.entrypoint
.locals init (
[0] int32 a,
[1] int32 b,
[2] int32 c
)
IL_0000: ldc.i4.s 13
IL_0002: stloc.0
IL_0003: ldc.i4.s 14
IL_0005: stloc.1
IL_0006: ldloc.0
IL_0007: ldloc.1
IL_0008: add
IL_0009: stloc.2
IL_000a: ldloc.2
IL_000b: call void [mscorlib]System.Console::WriteLine(int32)
IL_0010: ret
}
Now let’s just make those ints dynamic:
static void Main(string[] args)
{
dynamic a = 13;
dynamic b = 14;
dynamic c = a + b;
Console.WriteLine(c);
}
For the sake of space, I am actually going to not show the IL here, but this is what it looks like when you convert it back to C#:
private static void Main(string[] args)
{
object a = 13;
object b = 14;
if (Program.<Main>o__SiteContainer0.<>p__Site1 == null)
{
Program.<Main>o__SiteContainer0.<>p__Site1 =
CallSite<Func<CallSite, object, object, object>>.
Create(Binder.BinaryOperation(CSharpBinderFlags.None,
ExpressionType.Add,
typeof(Program),
new CSharpArgumentInfo[]
{
CSharpArgumentInfo.Create(CSharpArgumentInfoFlags.None, null),
CSharpArgumentInfo.Create(CSharpArgumentInfoFlags.None, null)
}));
}
object c = Program.<Main>o__SiteContainer0.
<>p__Site1.Target(Program.<Main>o__SiteContainer0.<>p__Site1, a, b);
if (Program.<Main>o__SiteContainer0.<>p__Site2 == null)
{
Program.<Main>o__SiteContainer0.<>p__Site2 =
CallSite<Action<CallSite, Type, object>>.
Create(Binder.InvokeMember(CSharpBinderFlags.ResultDiscarded,
"WriteLine",
null,
typeof(Program),
new CSharpArgumentInfo[]
{
CSharpArgumentInfo.Create(
CSharpArgumentInfoFlags.UseCompileTimeType |
CSharpArgumentInfoFlags.IsStaticType,
null),
CSharpArgumentInfo.Create(CSharpArgumentInfoFlags.None, null)
}));
}
Program.<Main>o__SiteContainer0.<>p__Site2.Target(
Program.<Main>o__SiteContainer0.<>p__Site2, typeof(Console), c);
}
Even the call to WriteLine isn’t straightforward. From simple, straightforward code, it has gone to a mishmash of memory allocations, delegates, dynamic method invocation, and these objects called CallSites.
The JITting statistics are predictable:
| Version | JIT Time | IL Size | Native Size |
| int | 0.5ms | 17 bytes | 25 bytes |
| dynamic | 10.9ms | 209 bytes | 389 bytes |
I do not mean to dump too much on the DLR. It is a perfectly fine framework for rapid development and scripting. It opens up great possibilities for interfacing between dynamic languages and .NET. If you are interested in what it offers, read a good overview here.
Code Generation
If you find yourself doing anything with dynamically loaded types (e.g., an extension or plugin model), then you need to carefully measure your performance when interacting with those types. Ideally, you can interact with those types via a common interface and avoid most of the issues with dynamically loaded code. If that approach is not possible, use this section to get around the performance problems of invoking dynamically loaded code.
The .NET Framework supports dynamic type allocation with the Activator.CreateInstance method, and dynamic method invocation with MethodInfo.Invoke. Here is an example using these methods:
Assembly assembly = Assembly.Load("Extension.dll");
Type type = assembly.GetType("DynamicLoadExtension.Extension");
object instance = Activator.CreateInstance(type);
MethodInfo methodInfo = type.GetMethod("DoWork");
bool result = (bool)methodInfo.Invoke(instance, new object[]
{ argument });
If you do this only occasionally, then it is not a big deal, but if you need to allocate a lot of dynamically loaded objects or invoke many dynamic function calls, these functions could become a severe bottleneck. Not only does Activator.CreateInstance use significant CPU, but it can cause unnecessary allocations, which put extra pressure on the garbage collector. There is also potential boxing that will occur if you use value types in either the function’s parameters or return value (as the example above does).
If possible, try to hide these invocations behind an interface known both to the extension and the execution program. If that does not work, code generation may be an appropriate option.
Thankfully, generating code to accomplish the same thing is quite easy. To figure out what code to generate, use a template as an example to generate the IL for you to mimic. For an example, see the DynamicLoadExtension and DynamicLoadExecutor sample projects. DynamicLoadExecutor loads the extension dynamically and then executes the DoWork method. The DynamicLoadExecutor project ensures that DynamicLoadExtension.dll is in the right place with a post-build step and a solution build dependency configuration rather than project-level dependencies to ensure that code is indeed dynamically loaded and executed.
Let’s start with creating a new extension object. To create a template, first understand what you need to accomplish. You need a method with no parameters that returns an instance of the type we need. Your program will not know about the Extension type, so it will just return it as an object. That method looks like this:
object CreateNewExtensionTemplate()
{
return new DynamicLoadExtension.Extension();
}
Take a peek at the IL and it will look like this:
IL_0000: newobj instance void [DynamicLoadExtension]DynamicLoadExtension.Extension::.ctor()
IL_0005: ret
Armed with that knowledge, you can create a System.Reflection.Emit.DynamicMethod, programmatically add some IL instructions to it, and assign it to a delegate which you can then reuse to generate new Extension objects at will.
private static T GenerateNewObjDelegate<T>(Type type) where T:class
{
var dynamicMethod = new DynamicMethod("Ctor_" + type.FullName, type, Type.EmptyTypes, true);
var ilGenerator = dynamicMethod.GetILGenerator();
var ctorInfo = type.GetConstructor(Type.EmptyTypes);
if (ctorInfo != null)
{
ilGenerator.Emit(OpCodes.Newobj, ctorInfo);
ilGenerator.Emit(OpCodes.Ret);
object del = dynamicMethod.CreateDelegate(typeof(T));
return (T)del;
}
return null;
}
You will notice that the emitted IL corresponds exactly to our template method.
To use this, you need to load the extension assembly, retrieve the appropriate type, and pass it the generator function.
Type type = assembly.GetType("DynamicLoadExtension.Extension");
Func<object> creationDel = GenerateNewObjDelegate<Func<object>>(type);
object extensionObj = creationDel();
Once the delegate is constructed, you can cache it for reuse (perhaps keyed by the Type object, or whatever scheme is appropriate for your application).
You can use the exact same trick to generate the call to the DoWork method. It is only a little more complicated due to a cast and the method arguments. IL is a stack-based language so arguments to functions must be pushed on to the stack in the correct order before a function call. The first argument for an instance method call must be the method’s hidden this parameter that the object is operating on. Note that just because IL uses a stack exclusively, it does not have anything to do with how the JIT compiler will transform these function calls to assembly code, which often uses processor registers to hold function arguments.
As with object creation, first create a template method to use as a basis for the IL. Since we will have to call this method with just an object parameter (that is all we will have in our program), the function parameters specify the extension as just an object. This means we will have to cast it to the right type before calling DoWork. In the template, we have hard-coded type information, but in the generator we can get the type information programmatically.
static bool CallMethodTemplate(object extensionObj, string argument)
{
var extension = (DynamicLoadExtension.Extension)extensionObj;
return extension.DoWork(argument);
}
The resulting IL for this template looks like:
.locals init (
[0] class [DynamicLoadExtension]DynamicLoadExtension.Extension extension
)
IL_0000: ldarg.0
IL_0001: castclass [DynamicLoadExtension]DynamicLoadExtension.Extension
IL_0006: stloc.0
IL_0007: ldloc.0
IL_0008: ldarg.1
IL_0009: callvirt instance bool [DynamicLoadExtension]DynamicLoadExtension.Extension::DoWork(string)
IL_000e: ret
Notice there is a local variable declared. This holds the result of the cast. We will see later that it can be optimized away. This IL leads to a straightforward translation into a DynamicMethod:
private static T GenerateMethodCallDelegate<T>(
MethodInfo methodInfo,
Type extensionType,
Type returnType,
Type[] parameterTypes) where T : class
{
var dynamicMethod = new DynamicMethod("Invoke_" + methodInfo.Name, returnType, parameterTypes, true);
var ilGenerator = dynamicMethod.GetILGenerator();
ilGenerator.DeclareLocal(extensionType);
ilGenerator.Emit(OpCodes.Ldarg_0);
ilGenerator.Emit(OpCodes.Castclass, extensionType);
ilGenerator.Emit(OpCodes.Stloc_0);
ilGenerator.Emit(OpCodes.Ldloc_0);
ilGenerator.Emit(OpCodes.Ldarg_1);
ilGenerator.EmitCall(OpCodes.Callvirt, methodInfo, null);
ilGenerator.Emit(OpCodes.Ret);
object del = dynamicMethod.CreateDelegate(typeof(T));
return (T)del;
}
To generate the dynamic method, we need the MethodInfo, looked up from the extension’s Type object. We also need the Type of the return object and the Types of all the parameters to the method, including the implicit this parameter (which is the same as extensionType).
This method works perfectly, but look closely at what it is doing and recall the stack-based nature of IL instructions. Here’s how this method works:
- Declare local variable
- Push
arg0 (the this pointer) onto the stack (LdArg_0) - Cast
arg0 to the right type and push result onto the stack - Pop the top of the stack and store it in the local variable (
Stloc_0) - Push the local variable onto the stack (
Ldloc_0) - Push
arg1 (the string argument) onto the stack - Call the
DoWork method (Callvirt) - Return
There is some glaring redundancy in there, specifically with the local variable. We have the casted object on the stack, we pop it off then push it right back on. We could optimize this IL by just removing everything having to do with the local variable. It is possible that the JIT compiler would optimize this away for us anyway, but doing the optimization does not hurt, and could help if we have hundreds or thousands dynamic methods, all of which will need to be JITted.
The other optimization is to recognize that the Callvirt opcode can be changed to a simpler Call opcode because we know there is no virtual method here. Now our IL looks like this:
var ilGenerator = dynamicMethod.GetILGenerator();
ilGenerator.Emit(OpCodes.Ldarg_0);
ilGenerator.Emit(OpCodes.Castclass, extensionType);
ilGenerator.Emit(OpCodes.Ldarg_1);
ilGenerator.EmitCall(OpCodes.Call, methodInfo, null);
ilGenerator.Emit(OpCodes.Ret);
To use our delegate, we just need to call it like this:
Func<object, string, bool> doWorkDel =
GenerateMethodCallDelegate<Func<object, string, bool>>(methodInfo, type, typeof(bool), new Type[] { typeof(object), typeof(string) });
bool result = doWorkDel(extension, argument);
So how is performance with our generated code? Here is one test run:
==CREATE INSTANCE==
Direct ctor: 1.0x
Activator.CreateInstance: 14.6x
Codegen: 3.0x
==METHOD INVOKE==
Direct method: 1.0x
MethodInfo.Invoke: 17.5x
Codegen: 1.3x
Using direct method calls as a baseline, you can see that the reflection methods are much worse. Our generated code does not quite bring it back, but it is close. These numbers are for a function call that does not actually do anything, so they represent pure overhead of the function call, which is not a very realistic situation. If I add some minimal work (string parsing and a square root calculation), the numbers change a little:
==CREATE INSTANCE==
Direct ctor: 1.0x
Activator.CreateInstance: 9.3x
Codegen: 2.0x
==METHOD INVOKE==
Direct method: 1.0x
MethodInfo.Invoke: 3.0x
Codegen: 1.0x
In the end, this demonstrates that if you rely on Activator.CreateInstance or MethodInfo.Invoke, you can significantly benefit from some code generation.
Story I have worked on one project where these techniques reduced the CPU overhead of invoking dynamically loaded code from over 10% to something more like 0.1%. You can use code generation for other things as well. If your application does a lot of string interpretation or has a state machine of any kind, this is a good candidate for code generation. .NET itself does this with regular expressions and XML serialization.
Preprocessing
If data needs to be transformed before it is useful during runtime, make sure that as much of that transformation happens beforehand, even in an offline process if possible.
In other words, if something can be preprocessed, then it must be preprocessed. It can take some creativity and out-of-the-box thinking to figure out what processing can be moved offline, but the effort is often worth it. From a performance perspective, it is a form of 100% optimization by removing the code completely.
Measurement
Each of the topics in this article requires a different approach to performance, using tools like PerfView or other profilers, as mentioned in the beginning of this article. CPU profiles will reveal expensive Equals methods, poor loop iteration, bad interop marshalling performance, and other inefficient areas.
Memory traces will show you boxing as object allocations and a general .NET event trace will show you where exceptions are being thrown, even if they are being caught and handled.
ETW Events
ExceptionThrown—An exception has been thrown. It does not matter if this exception is handled or not. Fields include:
- Exception Type - Type of the exception
- Exception Message - Message property from the exception object
EIPCodeThrow - Instruction pointer of throw siteExceptionHR - HRESULT of exception- ExceptionFlags
- 0x01 - Has inner exception
- 0x02 – Is nested exception
- 0x04 – Is rethrown exception
- 0x08 – Is a corrupted state exception
- 0x10 – Is a CLS compliant exception
See here for more information.
Finding Boxing Instructions
There is a specific IL instruction called box, which makes it fairly easy to discover in your code base. To find it in a single method or class, just use one of the many IL decompilers available (my tool of choice is ILSpy) and select the IL view.
If you want to detect boxing in an entire assembly, it is easier to use ILDASM with its flexible command-line options. ILDASM.exe ships with the Windows SDK. On my computer, it is located in C:\Program Files (x86)\Microsoft SDKs\Windows\v8.0A\bin\NETFX 4.0 Tools\. You can get the Windows SDK from here.
ildasm.exe /out=output.txt Boxing.exe
Take a look at the Boxing sample project, which demonstrates a few different ways boxing can occur. If you run ILDASM on Boxing.exe, you should see output similar to the following:
.method private hidebysig static void Main(string[] args) cil managed
{
.entrypoint
.maxstack 3
.locals init ([0] int32 val,
[1] object boxedVal,
[2] valuetype Boxing.Program/Foo foo,
[3] class Boxing.Program/INameable nameable,
[4] int32 result,
[5] valuetype Boxing.Program/Foo '<>g__initLocal0')
IL_0000: ldc.i4.s 13
IL_0002: stloc.0
IL_0003: ldloc.0
IL_0004: box [mscorlib]System.Int32
IL_0009: stloc.1
IL_000a: ldc.i4.s 14
IL_000c: stloc.0
IL_000d: ldstr "val: {0}, boxedVal:{1}"
IL_0012: ldloc.0
IL_0013: box [mscorlib]System.Int32
IL_0018: ldloc.1
IL_0019: call string [mscorlib]System.String::Format(string,
object,
object)
IL_001e: pop
IL_001f: ldstr "Number of processes on machine: {0}"
IL_0024: call class [System]System.Diagnostics.Process[] [System]System.Diagnostics.Process::GetProcesses()
IL_0029: ldlen
IL_002a: conv.i4
IL_002b: box [mscorlib]System.Int32
IL_0030: call string [mscorlib]System.String::Format(string,
object)
IL_0035: pop
IL_0036: ldloca.s '<>g__initLocal0'
IL_0038: initobj Boxing.Program/Foo
IL_003e: ldloca.s '<>g__initLocal0'
IL_0040: ldstr "Bar"
IL_0045: call instance void Boxing.Program/Foo::set_Name(string)
IL_004a: ldloc.s '<>g__initLocal0'
IL_004c: stloc.2
IL_004d: ldloc.2
IL_004e: box Boxing.Program/Foo
IL_0053: stloc.3
IL_0054: ldloc.3
IL_0055: call void Boxing.Program::UseItem(class Boxing.Program/INameable)
IL_005a: ldloca.s result
IL_005c: call void Boxing.Program::GetIntByRef(int32&)
IL_0061: ret
}
You can also discover boxing indirectly via PerfView. With a CPU trace, you can find excessive calling of the JIT_new function.
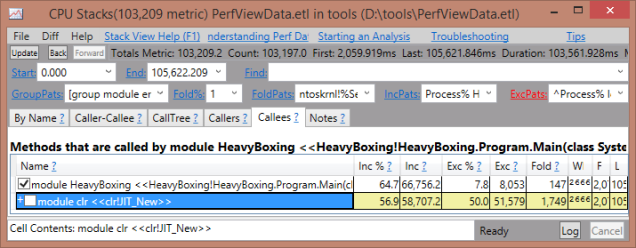
Figure 1. Boxing will show up in a CPU trace under the JIT_New method, which is the standard memory allocation method.
It is a little more obvious if you look at a memory allocation trace because you know that value types and primitives should not require a memory allocation at all:

Figure 2. You can see in this trace that the Int32 is being allocated via new, which should not feel right.
Discovering First-Chance Exceptions
PerfView can easily show you which exceptions are being thrown, regardless of whether they are caught or not.
- In
PerfView, collect .NET events. The default settings are ok, but CPU is not necessary, so uncheck it if you need to profile for more than a few minutes. - When collection is complete, double-click on the “Exception Stacks” node.
- Select the desired process from the list.
- The Name view will show a list of the top exceptions. The
CallTree view will show the stack for the currently selected exception.
Figure 3. PerfView makes finding where exceptions are coming from trivially easy.
Summary
Remember that in-depth performance optimizations will defy code abstractions. You need to understand how your code will be translated to IL, assembly code, and hardware operations. Take time to understand each of these layers.
Use a struct instead of a class when the data is relatively small, you want minimal overhead, or you are going to use them in arrays and want optimal memory locality. Consider making structs immutable and always implement Equals, GetHashCode, and IEquatable<T> on them. Avoid boxing of value types and primitives by guarding against assignment to object references.
Keep iteration fast by not casting collections to IEnumerable. Avoid casting in general, whenever possible, especially instances that could result in an InvalidCastException.
Minimize the number of P/Invoke calls by sending as much data per call as possible. Keep memory pinned as briefly as possible.
If you need to make heavy use of Activator.CreateInstance or MethodInfo.Invoke, consider code generation instead.
For more information about .NET performance, please check out the full book, Writing High-Performance .NET Code.
History
- 29 August 2014 - Clarified object overhead vs. minimum object size and updated calculations.

