I frequently see posts in the MSDN forums requesting assistance in removing duplicate values from a source, other than SQL, to be entered into a SQL Server destination. There are several options to accomplish this, but this post is meant to address the easiest and most straight forward. I first want to completely outline the business need to provide the appropriate context.
- The source is NOT SQL SERVER.
- The requirement is that no duplicate values can be inserted into the SQL Server source.
As I already mentioned, there are numerous way to accomplish this task. The first method I often see referenced is to import the data first into a staging table/database and use a T-SQL method to remove duplicates, ROW_NUMBER(), DENSE_RANK(), etc. This is a completely viable and acceptable method, and coming from the SQL world, easy to support and manage. The only concern that I have with this is the use of an intermediary step, with its associated resources, when it is not really necessary. The quickest way to remove duplicates is to use a Sort transformation in the data flow and select the Remove rows with duplicate sort values.
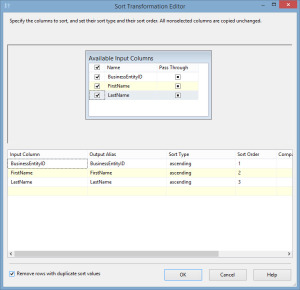
This is the easiest way to remove duplicates, but it comes at a cost. The Sort transformation is a fully blocking transformation, which means that it can only work with the full data set in memory. This seems pretty obvious since in order to sort the results, all the results must be present, but the larger the data set that you are working with, the more memory will be needed.
Another option is to use a Lookup transformation, which performs similar to a join in T-SQL. In the lookup transformation configuration, you can specify:
- Cache mode
- Full cache
- Partial cache
- No cache
- Connection
- Columns
So let’s consider a simplistic example to outline using a lookup to insert unique rows. Consider that you are importing 1,000 records from a flat file source into a SQL Server table. Each record contains an ID, first name, and last name and you must ensure that none of the records already exist in the table. To facilitate the example, I am going to use a data flow task to select 1,000 random records from the Adventureworks2012.Person.Person table and insert them into a delimited file.

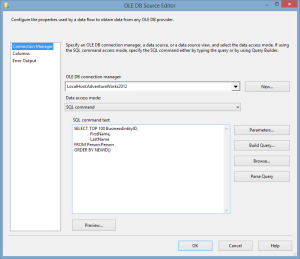
Within my package, I will use an execute SQL task to create a database called RandomDB and a table called People that will be used to import the flat file.
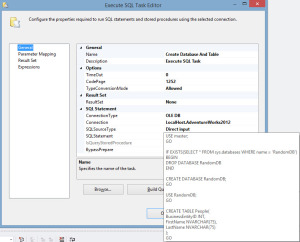
Next, in a data flow, I will populate 15,000 records from the Adventureworks2012.Person.Person table into the RandomDB.dbo.People table.
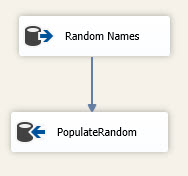
The ground work has been set and we can now dive into the example. We must import the records from the flat file that contains 1,000 records into the RandomDB.dbo.People table ensuring that we do not insert records into the table that already exist. If the source was SQL, this would be easy enough with an INSERT statement selecting only the records that did not already exist in the table, but since the source is a flat file, we are unable to do that. The first step is to create a data flow task that will use the flat file as the source.
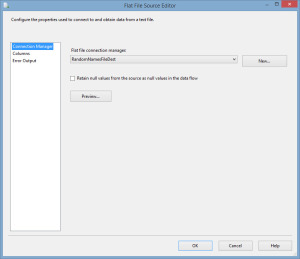
Now, we will use the lookup transformation with a connection to the RandomDB.dbo.People table and specify that the BusinessEntityID column in the people table is equal to the BusinessEntityID in the flat file.
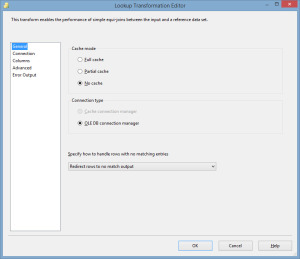
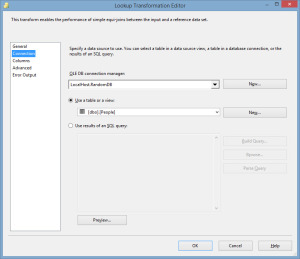
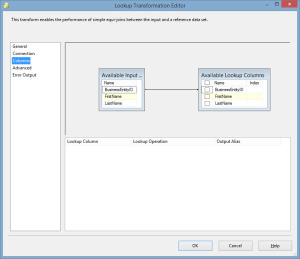
The lookup has now been configured to match the records from the table and flat file using the BusinessEntityID, the primary key in this case. You will also notice that the lookup supports matching multiple columns. So consider that the records coming in may only have the first and last name, but we still need to ensure that there are no duplicate records inserted into our table. We could configure the columns to match both first and last name. The lookup transformation has two outputs, Lookup No Match Output and Lookup Match Output. Since the entire premise of this exercise is to ensure that there are no duplicate records entered into the RandomDB.dbo.People table, the Lookup NoMatch Output will be mapped to our RandomDB.dbo.People destination and I will use a flat file destination for the matched records, this is for demonstration only as for a real production package, I would leave the Matched output unmapped.
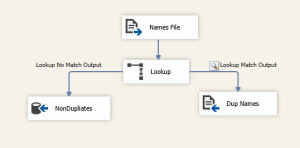
As you can see, the Lookup acts as an equi-join between the flat file source and the table that will receive the records. By using the unmatched output, you ensure that only records that do not exist in the destination are inserted while the duplicates are sent down a different path.
I created a sample package to demonstrate the usefulness of a lookup transformation and included all of the tasks necessary to run this package in a local environment and delete all associated sample files, databases, and tables in the package.
This sample package is available for download here.

