Every project has its own style guide: a set of conventions about how to write code for that project. Some managers choose a basic coding rules, others prefer very advanced ones and for many projects no coding rules are specified, and each developer uses his style.
It is much easier to understand a large codebase when all the code in it is in a consistent style.
Many resources exist talking about the better coding rules to adopt, we can learn good coding rules from:
- Reading a book or a magazine
- Web sites
- From a colleague
- Doing a training
Another more interesting approach is to study a known and mature open source project to discover how their developers implements the code. In case of C language, a good candidate could be the Linux kernel.
For the beginner C developers or even the intermediate ones, the Linux kernel is maybe not easy to go inside, however the goal is not necessarily to contribute to its source code but to explore how it’s implemented .
Let’s take as example a function implementation from the Linux source code.
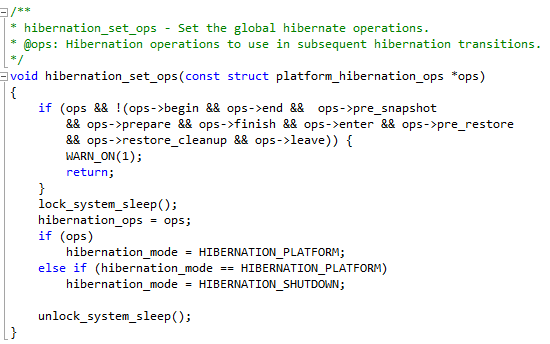
The code looks very clean, indeed the function:
- Has only few lines of code
- The signature is well defined
- It’s well commented
- It’s well indented
- The variable names are very clear
The same function could be implemented by another developer like this:

The coding style has a big impact on the source code readability, investing some hours to train developers, and periodically doing a code review is always good to make the code easy to maintain and evolve.
Let’s go inside the linux kernel source code using CppDepend and discover some basic coding rules adopted by their developers.
Modularity
Modularity is a software design technique that increases the extent to which software is composed from separate parts, you can manage and maintain modular code easily.
For procedural language like C where no logical artifacts like namespace, component or class exist, we can modularize by using directories and files.
Here are some possible scenarios:
- Put all the source files in one directory
- Isolate files related to a module or a sub module into a specific directory.
In case of the Linux kernel, directories and sub directories are used to modularize the kernel source code.
Encapsulation
Encapsulation is the hiding of functions and data which are internal to an implementation. In C, encapsulation is performed by using the key word static. These entities are called file-scope functions and variables.
Let’s search for all static functions by executing the following CQLinq query:
We can use the Metric view to have a good idea of how many functions are concerned. In the Metric View, the code base is represented through a Treemap. Treemapping is a method for displaying tree-structured data by using nested rectangles. The tree structure used in a CppDepend treemap is the usual code hierarchy:
- Projects contain directories
- Directories contain files
- Files contains structs, functions and variables
The treemap view provides a useful way to represent the result of a CQLinq request, so we can visually see the types concerned by the request.
As we can observe, many functions are declared as static.
Let’s search now for the static fields:
The same remark as functions, many variables are declared as static.
In the Linux kernel source code, the encapsulation is used whenever the functions and variables must be private to the file scope.
Use Structs to Store Your Data Model
In C programing, the functions use variables to achieve their treatments, these variables could be:
Static variablesGlobal variables- Local variables
- Variables from
structs
Each project has its data model which could be used by many source files, using global variables is a solution but not the good one, using structs to group data is more recommended.
Let’s search for global variables with a primitive type:
Only very few variables are concerned, and maybe we can group some of them into structs, like (elfcorehdr_addr and elfcorehdr_size) or (pm_freezing and pm_nosig_freezing).
Let Function be Short and Sweet
Here’s from the linux coding style web page, an advice about the length of functions:
Functions should be short and sweet, and do just one thing. They should
fit on one or two screenfuls of text (the ISO/ANSI screen size is 80x24,
as we all know), and do one thing and do that well.
The maximum length of a function is inversely proportional to the
complexity and indentation level of that function. So, if you have a
conceptually simple function that is just one long (but simple)
case-statement, where you have to do lots of small things for a lot of
different cases, it's OK to have a longer function.
Let’s search for functions where the number of lines of code is more than 30.
Only few methods have more than 30 lines of code.
Function Number of Parameters
Functions where NbParameters > 8 might be painful to call and might degrade performance. Another alternative is to provide a structure dedicated to handle arguments passing.
Only 2 methods have more than 8 parameters.
Number of Local Variables
Methods where NbVariables is higher than 8 are hard to understand and maintain. Methods where NbVariables is higher than 15 are extremely complex and should be split in smaller methods (except if they are automatically generated by a tool).
Only 5 functions have more than 15 local variables.
Avoid Defining Complex Functions
Many metrics exist to detect complex functions, NBLinesOfCode, number of parameters and number of local variables are the basic ones.
There are other interesting metrics to detect complex functions:
- Cyclomatic complexity is a popular procedural software metric equal to the number of decisions that can be taken in a procedure.
- Nesting Depth is a metric defined on methods that is relative to the maximum depth of the more nested scope in a method body.
- Max Nested loop equals the maximum level of loop nesting in a function.
The max value tolerated for these metrics depends more on the team choices, there’s no standard values.
Let’s search for functions candidate to be refactored:
Only very few functions could be considered as complex.
Naming Convention
There’s no standard for the naming convention, each project manager could choose what they think it’s better, however what’s very important is to respect the chosen convention to have an homogenous naming.
For example, in case of Linux, the structs must begin with a lower case, and we can check if it’s true for the whole kernel source code, let’s execute the following query:
Only 4 structs began with “_” instead of a lower case letter.
Indentation
The indentation is very useful to make the code easy to read, here’s from the linux coding style web page the motivations behind the indentation:
Rationale: The whole idea behind indentation is to clearly define where
a block of control starts and ends. Especially when you've been looking
at your screen for 20 straight hours, you'll find it a lot easier to see
how the indentation works if you have large indentations.
Now, some people will claim that having 8-character indentations makes
the code move too far to the right, and makes it hard to read on a
80-character terminal screen. The answer to that is that if you need
more than 3 levels of indentation, you're screwed anyway, and should fix
your program.
Conclusion
Exploring some known open source projects is always good to elevate your programming skills, no need to download and build the project, you can just discover the code from GitHub for example.

