Download source code
→ You might want to have a look at Syntax analysis: an example after reading this.
Introduction
Lexical analyzer (or scanner) is a program to recognize tokens (also called symbols) from an input source file (or source code). Each token is a meaningful character string, such as a number, an operator, or an identifier.
This is the assignment: write a scanner following these lexical rules:
- Case insensitive
- All English letters (upper and lower), digits, and extra characters as seen below, plus whitespace
- Identifiers
- begin with a letter, and continue with any number of letters
- assume no identifier is longer than 8 characters
- Keywords (reserved), include: start finish then if repeat var int float do read print void return dummy program
- Relational operators, include: == < > =!= => =<
- Other operators, include: = : + - * / %
- Delimiters, include: . ( ) , { } ; [ ]
- Numbers:
- any sequence of decimal digits, no sign
- assume no number is longer than 8 digits
- Other assumption:
- No whitespace needed to separate tokens except when this changes the tokens (as x y vs xy)
- Comments start with // and end with new line
Display tokens found, each with 3 fields: token type, token instance, and line number.
Other requirement:
- Invocation of the program is:
scanner [filename]
where input source file is filename.lan (extension .lan is implicit).
Program will read the same data from keyboard via redirecting from a file if filename is not specified. For example, scanner < filename.lan - Perform necessary validations. For example, if found invalid symbols, show error message with line number, and then abort the program
Preparation
Plan
This is the Makefile that also shows the organization of the program files:
CC = gcc
PROG = scanner
$(PROG): driveScanner.o scanner.o
$(CC) -o $(PROG) driveScanner.o scanner.o
driveScanner.o : driveScanner.c token.h scanner.h
$(CC) -c driveScanner.c
scanner.o : scanner.c token.h scanner.h symdef.h
$(CC) -c scanner.c
.PHONY: clean
clean:
/usr/bin/rm -rf core $(PROG) *.o
token.h defines MAX (= 8, max length of each word string), LIMIT (= 200, max number of word strings in an input source file), and declares token types (show later).
Process command-line arguments and redirection
Start with main() from driveScanner.c:
int main(int argc, char *argv[]) {
FILE *filePtr;
switch (argc) {
case 1: filePtr = stdin;
break;
case 2: if ( (filePtr = fopen(strcat(argv[1], ".lan"), "r")) == NULL ) {
printf("Cannot open input file.\n");
exit(1);
}
break;
default:
printf("Syntax: scanner [file] (.lan is implicit)\n");
exit(0);
}
}
Next to check if input file is empty:
fseek(filePtr, 0, SEEK_END);
if (ftell(filePtr) == 0) {
printf("File is empty.\n");
exit(1);
} else {
rewind(filePtr);
}
Now check for invalid characters and max word length
char c;
int numLine = 1;
int charCount = 0;
char tempStr[MAX]; int i;
int isValid = 1; while ((c = fgetc(filePtr)) != EOF) {
if (c == '\n')
numLine++;
if (c == '/') {
if (fgetc(filePtr) == '/') {
while ((c = fgetc(filePtr)) != '\n') {}
numLine++;
}
}
if (isalnum(c)) {
tempStr[charCount] = c;
charCount++;
if (charCount > MAX) {
printf("Word '%s' on line number %d is too long. \n", tempStr, numLine);
exit(1);
}
} else if (isspace(c) || isExAcceptableChar(c)) {
charCount = 0;
} else {
printf("Invalid character '%c' at line %d. \n", c, numLine);
isValid = 0; }
}
if (isValid == 0) {
printf("Something wrong with the input file. \n");
exit(1);
}
rewind(filePtr);
At this time, the file is good. Now let scanner.c do the work:
TokenType tokenType = UNDEF;
while ((tokenType = getTokenType(filePtr)) != EOT) {}
fclose(filePtr);
return 0;
Let have a look at type declaration in token.h:
typedef enum {
IDENTIFIER,
KEYWORD,
NUMBER,
REL_OP, OP, DELIM,
UNDEF, EOT
} TokenType;
typedef struct {
TokenType tokenType;
char *instance;
int lineNum;
} Token;
Note that I have not yet utilized the TokeType enum and Token struct as intended. When working on this assignment, first I declared and intended to use Token struct as 'tripple' data type (TokenType enum, instance, and line number). But then these became not needed as showed below.
At this time, the rest of work is the scanner responsibility now. I created another header file, besides token.h, to support the scanner.c do the work.
symdef.h defines the following according to the assignment requirements, and other several local arrays to scanner to store tokens found:
char *keywords[] = {"start", "finish", "then", "if", "repeat", "var",
"int", "float", "do", "read", "print", "void", "return", "dummy", "program"};
char *relationalOperators[] = {"==", "<", ">", "=!=", "=>", "=<"};
char otherOperators[] = {':', '+', '-', '*', '/', '%'};
char delimiters[] = {'.', '(', ')', ',', '{', '}', ';', '[', ']'};
char words[LIMIT][MAX]; int wordi = 0, wordj = 0;
int wordLineNums[LIMIT];
char keys[LIMIT][MAX]; int keyi = 0;
int keyLineNums[LIMIT];
char idens[LIMIT][MAX]; int ideni = 0;
int idenLineNums[LIMIT];
char nums[LIMIT][MAX]; int numi = 0, numj = 0;
int numLineNums[LIMIT];
char delims[LIMIT]; int delimi = 0;
int delimLineNums[LIMIT];
char otherOps[LIMIT]; int otherOpi = 0;
int otherOpLineNums[LIMIT];
char relOps[LIMIT][MAX]; int relOpi = 0, relOpj = 0;
int relOpLineNums[LIMIT];
The scanner.c
Besides English letters, and digits, these are extra acceptable characters:
int isExAcceptableChar(char c) {
if (c == '.' || c == '(' || c == ')' || c == ',' || c =='{' || c == '}' ||
c == ';' || c == '[' || c == ']' ||
c == ':' || c == '+' || c == '-' || c == '*' || c == '/' || c == '%' ||
c == '=' || c == '<' || c == '>' || c == '!') {
return 1;
} else
return 0;
}
The key function of scanner.c is as follow:
TokenType getTokenType(FILE *filePtr) {
int lineNum = 1;
char ch;
while ((ch = fgetc(filePtr)) != EOF) {
if (ch == '\n') {
lineNum++;
}
if (ch == '/') {
if (fgetc(filePtr) == '/') {
while ((ch = fgetc(filePtr)) != '\n') {}
lineNum++;
} else
fseek(filePtr, -1, SEEK_CUR);
}
if (isalpha(ch)) {
words[wordi][wordj++] = ch;
while (isalpha(ch = fgetc(filePtr))) {
words[wordi][wordj++] = ch;
}
words[wordi][wordj] = '\0';
wordLineNums[wordi] = lineNum;
wordi++; wordj = 0;
fseek(filePtr, -1, SEEK_CUR);
}
else if (isdigit(ch)) {
nums[numi][numj++] = ch;
while (isdigit(ch = fgetc(filePtr))) {
nums[numi][numj++] = ch;
}
nums[numi][numj] = '\0';
numLineNums[numi] = lineNum;
numi++; numj = 0;
fseek(filePtr, -1, SEEK_CUR);
}
else if (ispunct(ch)) {
if (isDelimiter(ch)) {
delims[delimi] = ch;
delimLineNums[delimi] = lineNum;
delimi++;
}
else if (isOtherOperators(ch)) {
otherOps[otherOpi] = ch;
otherOpLineNums[otherOpi] = lineNum;
otherOpi++;
}
else if (isStartRelationalOperator(ch)) {
if (ch == '<' || ch == '>') {
relOps[relOpi][relOpj++] = ch;
relOps[relOpi][relOpj] = '\0';
relOpLineNums[relOpi] = lineNum;
relOpi++; relOpj = 0;
}
else if (ch == '=') {
if ((ch = fgetc(filePtr)) == '=' || ch == '>' || ch == '<') {
relOps[relOpi][relOpj++] = '=';
relOps[relOpi][relOpj++] = ch;
relOps[relOpi][relOpj] = '\0';
relOpLineNums[relOpi] = lineNum;
relOpi++; relOpj = 0;
} else if (ch == '!') {
if ((ch = fgetc(filePtr)) == '=') {
relOps[relOpi][relOpj++] = '=';
relOps[relOpi][relOpj++] = '!';
relOps[relOpi][relOpj++] = ch;
relOps[relOpi][relOpj] = '\0';
relOpLineNums[relOpi] = lineNum;
relOpi++; relOpj = 0;
} else {
fseek(filePtr, -1, SEEK_CUR);
}
} else {
fseek(filePtr, -1, SEEK_CUR);
}
}
}
}
}
splitWords();
printSummary();
return EOT; }
Note:
- The idea is to have 'one look ahead' to decide what next token is going to be.
- fseek(filePtr, -1, SEEK_CUR) is to go back one character when needed.
- 2D array words is to 'collect' keyword and identifiers token. Then split this 2D array (of characters, or 1D array of strings equivalently) to get keyword and identifier tokens arrays.
- Operators and numbers tokens are founded by going forward and backward 'one character at a time'.
- These are some checking functions helpful while going back and forth the input source file:
int isStartRelationalOperator(char c) {
int i;
int result = 0; if (c == '=' || c == '<' || c == '>') {
result = 1;
}
return result;
}
int isOtherOperators(char c) {
int i;
int result = 0; for (i = 0; i < 6; i++) {
if (otherOperators[i] == c)
result = 1;
}
return result;
}
int isDelimiter(char c) {
int i;
int result = 0; for (i = 0; i < 9; i++) {
if (delimiters[i] == c)
result = 1;
}
return result;
}
int isKeyword(char *str) {
int i;
int result = 0; for (i = 0; i < 15; i++) {
if (!strcasecmp(keywords[i], str))
result = 1;
}
return result;
}
Note: the number 6, 9, 15 (number of pre-specified other operators, delimiters, and keywords) were hard-coded which shouldn't be. They should be defined the way similiar to MAX or LIMIT in token.h instead.
Now look at the words array, and pick tokens for keywords and identifiers token arrays (keys array and idens array):
void splitWords() {
int i;
for (i = 0; i < wordi; i++) {
if (isKeyword(words[i])) {
strcpy(keys[keyi], words[i]);
keyLineNums[keyi] = wordLineNums[i];
keyi++;
} else {
strcpy(idens[ideni], words[i]);
idenLineNums[ideni] = wordLineNums[i];
ideni++;
}
}
}
Last step is to display these tokens arrays (nums, keys, idens, delims, relOps, and otherOps). I include the sample input source file (file.lan) as follow:
// first keywords separated by spaces then by delimiters then by operators
start finish then if repeat var int float do read print void return dummy program
start.finish(then)if,repeat{var}int;float[do]start==finish<then>if=!=repeat=>var<=int=float:do!read+print-void*return/dummy%program
// now some identifiers and numbers separated by operators or delimiters or WS
x.xyz abc123 abc 123 -123
</then>
This is my output:
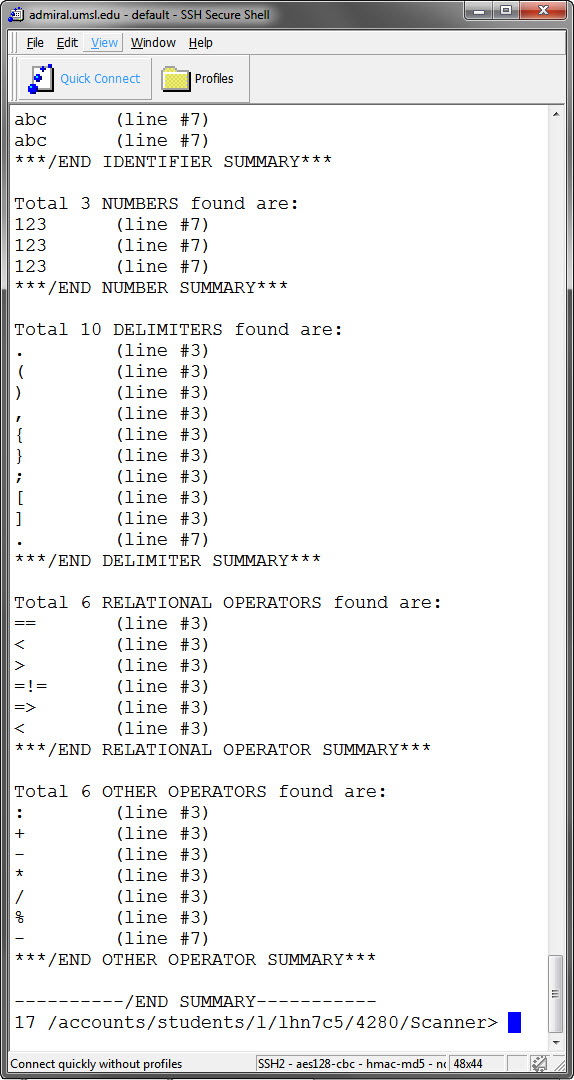
→ You might want to have a look at Syntax analysis: an example after reading this.

