Contents
- Introduction
- Background
- From sirop d'érable to probability distributions
- Okay, so where's the catch?
- The Statistics Workbench
- Back to the maple
- How it works?
- Using the code
- Instantiating a new probability distribution
- Estimating the distribution's parameters
- Generating new samples from a distribution
- Creating a new probability distribution
- Guessing a plausible distribution for the data
- More advanced examples
- Mixture distributions
- Gaussian mixture models
- Independent and joint distributions
- Non-parametric distributions
- Final notes
- Conclusion
- History
- References
Statistics is a topic that has always fascinated me. It might go unnoticed to some, but most of the modern and recent discoveries on artificial intelligence, machine learning, and even hot topics like "Data Mining", "Deep Learning" and "Business Intelligence" are often just plain applications of conventional statistics. Some applications are for sure thoughtful and elaborate - but most of them could indeed be regarded as simple applied mathematics involving a few statistical distributions in the process.
In this article, we will see how to use the statistics module of the Accord.NET Framework to create probability distributions, estimate those distributions from data and discover how to generate new data samples from existing distributions. In the end, we will see how all of those operations can be combined into a single application for teaching, visualizing, and working with those distributions.
One of the most important concepts in statistics is the concept of a probability distribution. Probability distributions allow us to cope with uncertainty regarding observations (measurements) we make in the real world. They can tell us how different values for a variable we are observing are spread – and having access to this information come in handy in several situations.
One reason for this is that its often easier to deal with probability distributions than with the observations themselves. For example, if we know with certainty (or just assume) that a variable is following a specific distribution that can be defined in terms of a mathematical formula, we become able to interchange the data we are analyzing by the formula itself. This means that, instead of having to load the data into memory and making computations on top of it, we can instead write the formula that describes the data on a paper and then obtain our answers through algebraic manipulation without ever having to perform number crunching operations.
Okey, so how do probability distributions allow us to cope with uncertainty? Well, to see that, let's look into an example.
Example:
Let's say we are the proud owners of a small, family-based maple syrup production factory. In our factory, there is one machine that is responsible for filling bottles with around 100ml of maple syrup each. However, we know that sometimes this machine puts slightly less or slightly more, depending on its mood during the day.

In the given example, the exact amount of maple syrup in each bottle is uncertain, in the sense that we can't determine exactly how much syrup the machine will put in each bottle. However, this doesn't forbid us from trying to model the behavior of the machine based on what we can observe about it.
As such, lets denote the amount of syrup that the machine might put in a bottle as X. Now, note that when we actually watch the machine working, X could be observed to be 95ml, 98ml, 100ml, or literally any other positive value in the real line. Each time we put the machine to work, the observed value of X would change. As such, this means that we cannot find a unique and well-determined value for this X (as it varies with each observation); but we can instead find the probability that an observation of this variable might be in a particular range.
Now, how do we express those different ranges and probabilities associated with X? Well, the first step is to understand what X is. This X is not an ordinary variable, but is instead a random variable. It is said to be random because it varies with each observation, but make no mistake: just because it is called random it doesn't mean that this variable doesn't follow certain rules. Actually, it's quite the inverse: this variable is random because it has an attached probability distribution – a mechanism that assigns different probabilities to the different ranges of values that this variable can assume.
In a very simplistic explanation, a probability distribution can be expressed in terms of a function that gives the probability (a value between 0 and 1) for a given range of the random variable X. This function is known as the probability distribution function. It can be used to answer questions such as:
- What's the probability of
X being between a and b? - What's the probability that P(a <
X ≤ b) ? [read as the probability that X would fall between a and b] - What's the probability that P(
X ≤ 100) ? [read as the probability that X is less than or equal to 100] - What's the value of p in P(
X > 100) = p ?
Or in more practical terms:
- What's the probability of the machine filling a bottle with a volume between 0ml and 100ml ?
- What's the probability of the machine filling a bottle with less than 100ml ?
Note: The most common form to express a distribution function is to write P(X ≤ x), meaning "The probability that an observation of X is less than or equal to x". However, it can be stated equally as P(X > x), indicating "The probability that an observation of X is greater than x" or, in the more general form P(a < X ≤ b), meaning "The probability that an observation of X is between a and b". When a or b is omitted, it means we should consider either the lower limit or the upper limit of the possible values for the variable.
Now, a probability distribution can be defined in several ways. The most common is to specify it either in terms of a distribution function (CDF) or in terms of a probability density function (PDF) that when integrated originates the distribution function. From those two formulas we can obtain several measures and secondary functions about a distribution. Those measures include the distribution's mean, median, mode, variance and range values. Other functions include the quantile function (inverse distribution), the complementary distribution function, the quantile density function and the hazard functions.
As such, we see that there are main properties and main functions that are common to all probability distributions. In this case, it might be interesting to try to model the concept of a probability distribution using a common concept to coders: a class interface.
Fig 1. Common interface for probability
distributions in the Accord.NET Framework
So now that we have a interface for probability distributions, how would individual distributions look like?
Here it all depends on which approach we are willing to take. There are two main approaches for dealing with statistics: the parametric approach and the non-parametric approach. In both approaches it is still possible to compute most of the same measures as specified before. However, the most popular approach might still be the parametric one (we will discover why soon).
In the parametric approach, we assume that the distribution function follows a particular mathematical formulation where there are some parameters missing. For example, lets consider the Normal distribution. The density function and the distribution function for the Normal distribution can be respectively expressed as
$f(x) = \frac{1}{\sqrt{2\pi}\sigma} e^{\frac{-(x-\mu)^2}{2\sigma^2}}$
$F(x) = \int_{-\infty}^x f(x) dx .$
Note that those functions actually take only a single argument (x), but have two other variables in their composition. Those are the mean (\(\mu\)) and the standard deviation (\(\sigma\)). Both are considered parameters of the distribution, and they must be specified before those formulas can be used. Now, the advantage is that both of them can be obtained very easily through some simple computations, with just one single pass over the data we might have. First we compute the mean of our values (\(\mu\)), and then we compute the standard deviation or values (\(\sigma\)). Than we substitue them in the formulas above.
As we can see, this simplicity is the biggest advantage of the parametric approach. There are only a few parameters to be estimated. And much more importantly,
their computation can be carried out by hand.
Now it is easy to underestimate the importance of this sentence. But remember that not so long ago, there was a time when computers were actually humans.
Nevertheless, by specifying different parametrizations and different formulas, we can create several standard probability distributions (or distribution families) that we can use to model our data. For example, the figure below shows some of those distributions and how they can be used under the same probability distribution interface.
Fig 2. Example on how distinct distributions fit together under the same interface.
The catch, my friend, is that if we choose the wrong distribution for our data, any further calculations or actions that we take based on this wrong distribution won't make any sense.
This is the biggest problem with parametric statistics. While the theoretical distributions have useful analytical properties, it doesn't mean that the data we are using will actually follow those properties. Thus we have to choose carefully which distribution should be assumed for our data, and we have to make sure the parameters we are estimating are indeed good estimates for the data we have.
So which are the distributions that we can choose from? How do we know how well they relate to the data we have?
Enter the Statistics Workbench. The Workbench is an application to discover, explore and learn about different statistical distributions. It can also be used to fit distributions to your data and suggest the most appropriate distributions you can use in your assumptions.
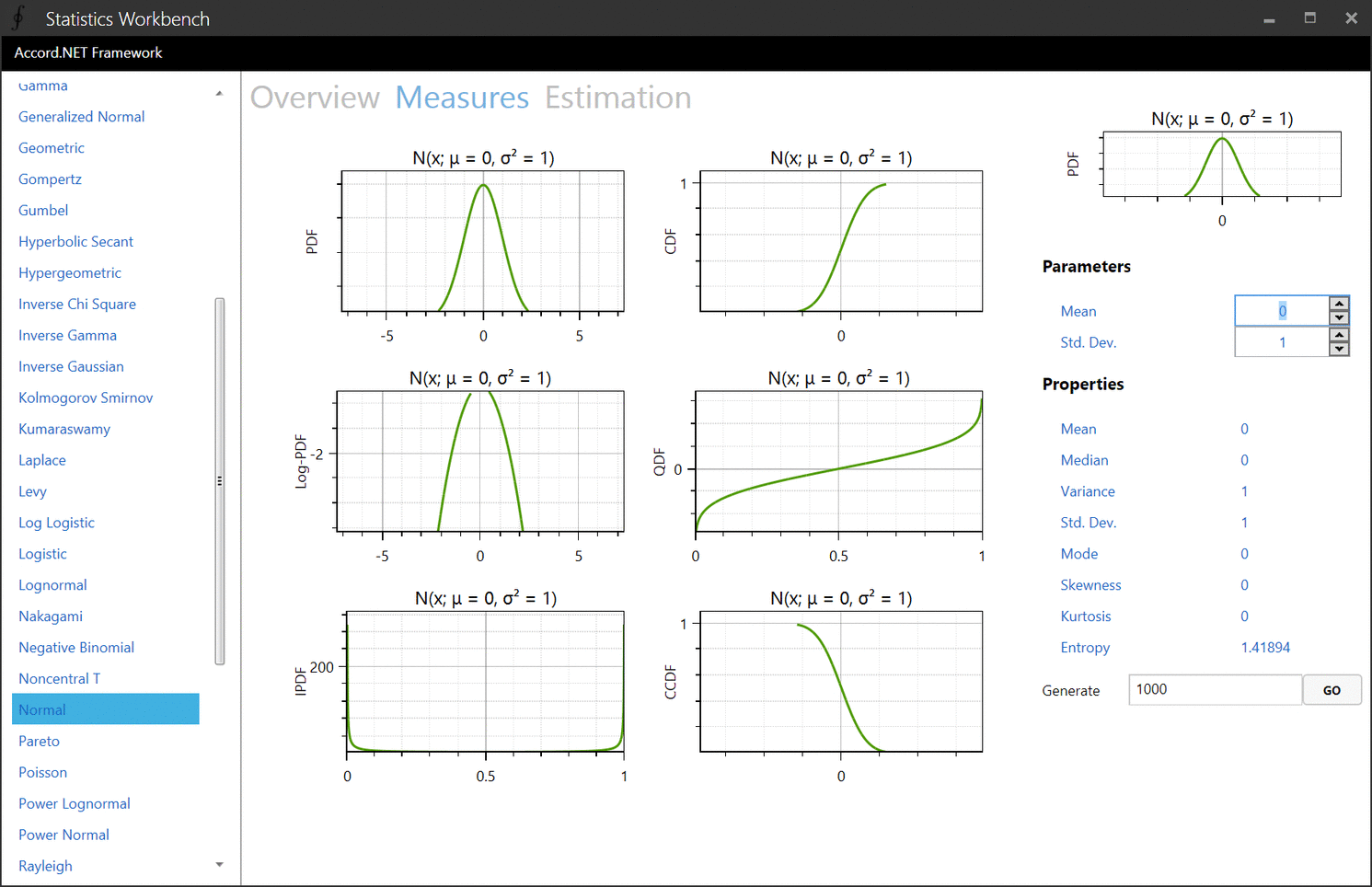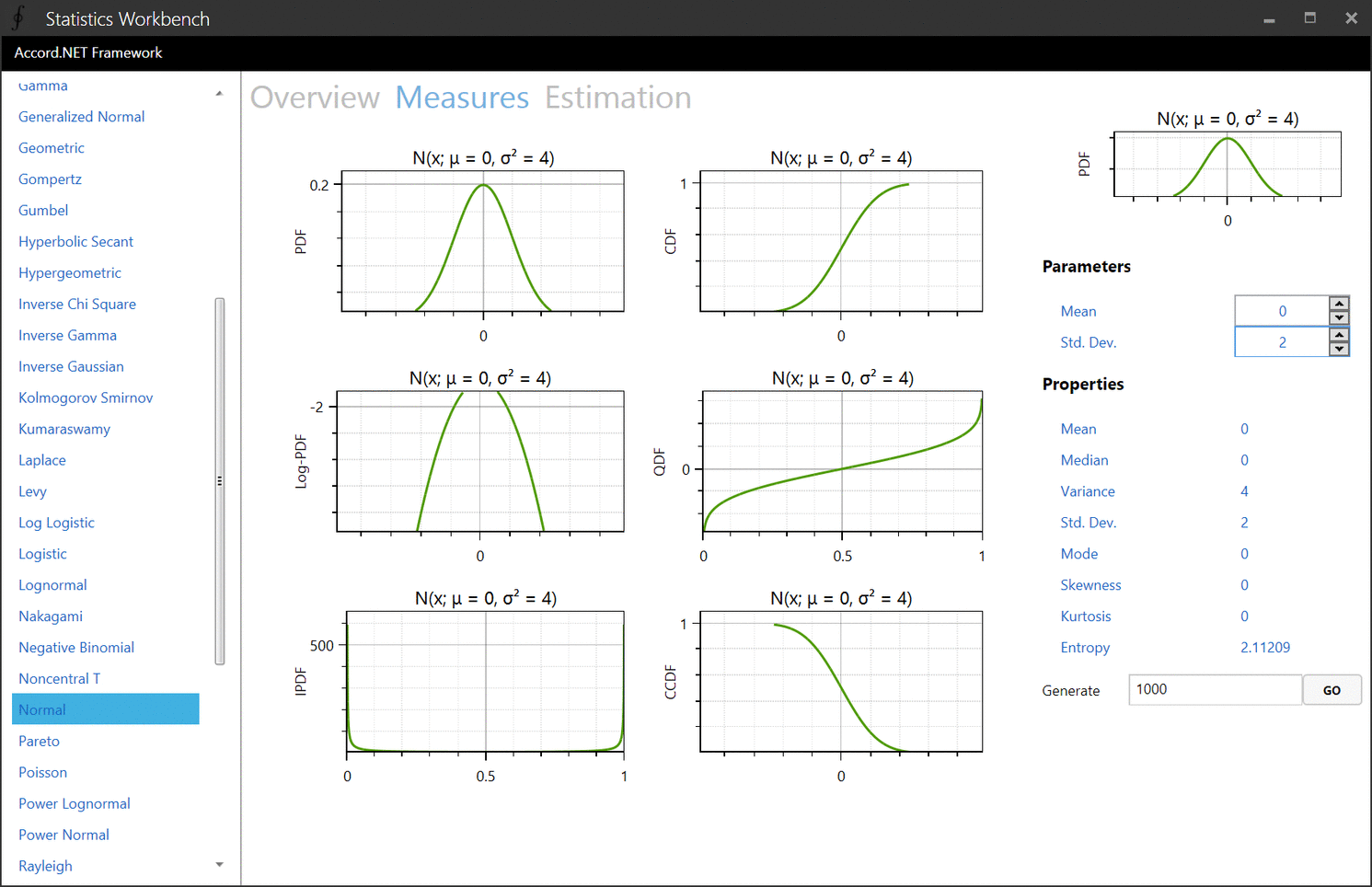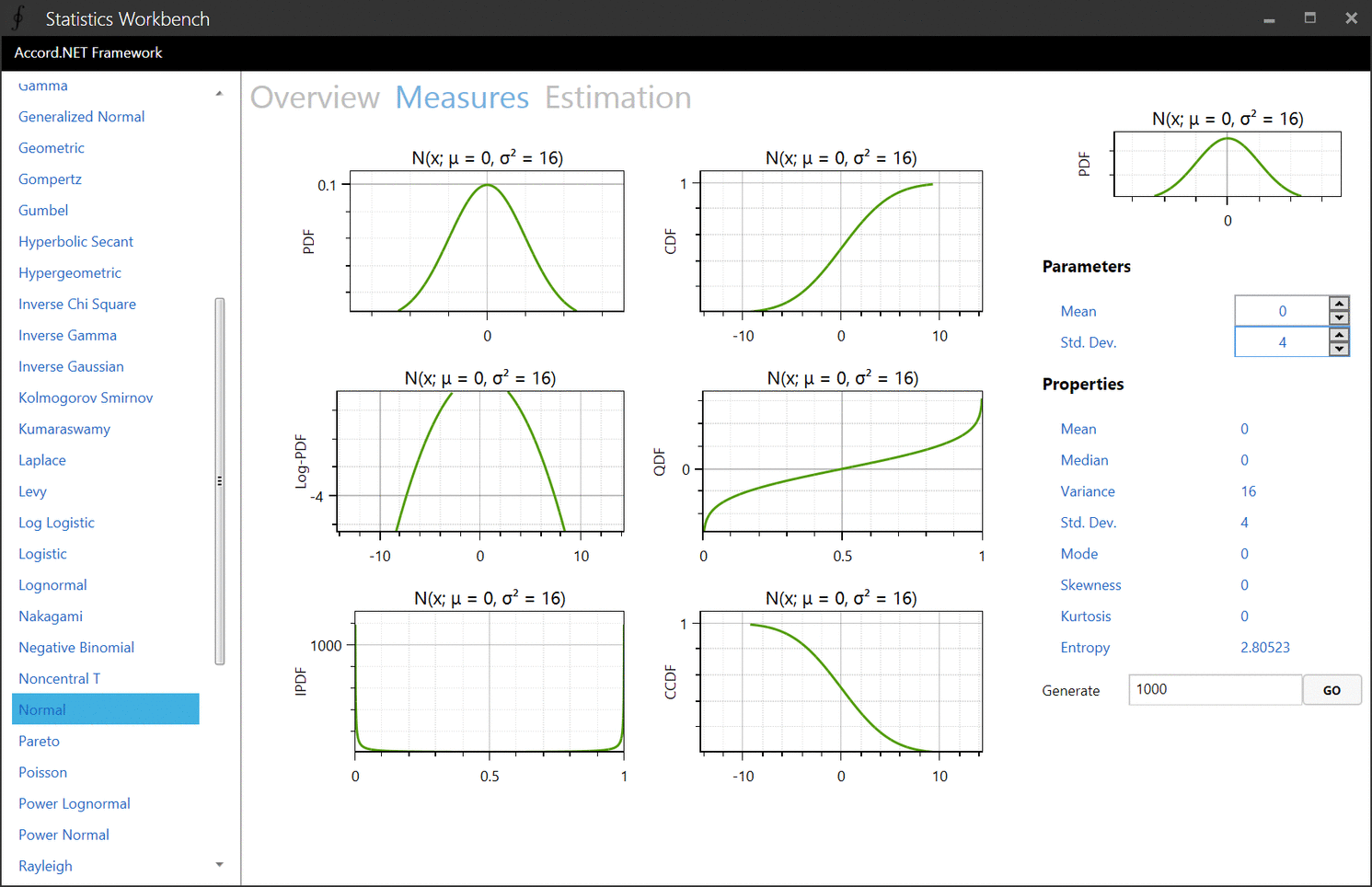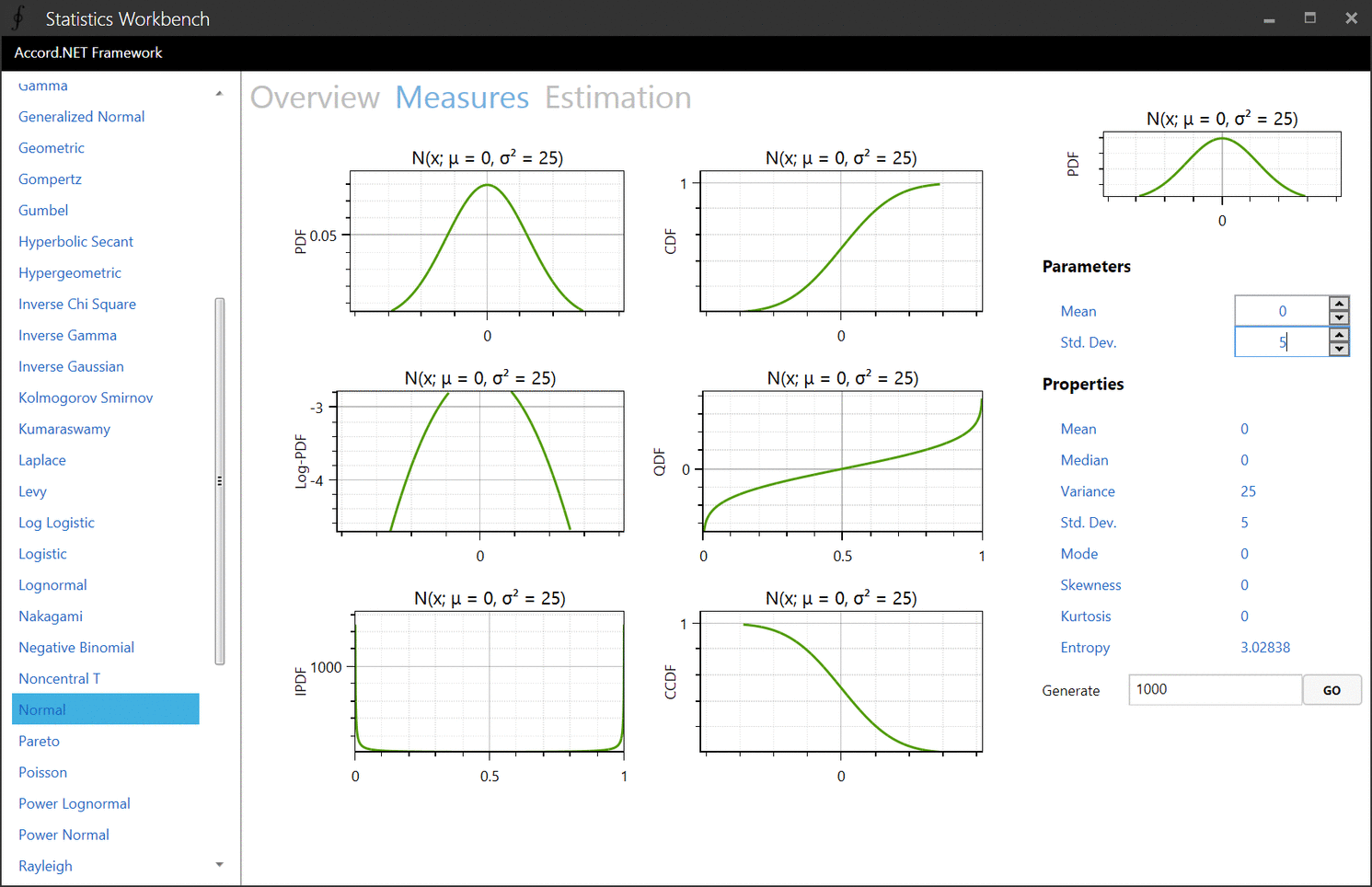
An overview of the Normal distribution in the Statistics Workbench.
The application is completely interactive. When browsing one particular distribution, you can change its parameters and see instantly how the distribution's prorperties and functions are impacted.
Now, one cool part is that the application is entirely based on reflection. The application inspects every probability distribution implemented in the Accord.NET Framework to populate its interface. It even queries documentation files to build the description pages you see above.
In order to demonstrate how useful the application can be, let's solve an example problem using the workbench. This example starts exactly the same as before, but comes with extra sweetness.
Example:
Let's say we are the proud owners of a small, family-based maple syrup production factory. In our factory, there is one machine that is responsible for filling bottles with around 100ml of maple syrup each. However, we know that sometimes this machine puts slightly less or slightly more, depending on its mood during the day.
Despite this old cranky machine, things have been doing very well lately. So well, that a supermarket chain became interested in reselling our maple goods in their shelves. However, in order to ensure quality and consumer satisfaction, the supermarket says that our products cannot contain less syrup than what's being advertised in the bottle. In order to obey current regulations, the number of bottles out of specification must be no more than 5% of the delivery.
In the given example, the exact amount of maple syrup in each bottle is uncertain, in the sense that we can't determine exactly how much syrup the machine will put in each bottle. However, we know that the machine is much more likely to produce some range of volumes than others, and we might use this fact to take an informed decision on what we should do to adjust the production accordingly.
So let's fire up the Workbench
Let's go to the Estimation tab
Now, let's observe what happens when we let our machine work. First, we configured the machine to pour 100ml per bottle. Then we took some measurement cups and we observed the machine run 100 times, registering at each time how much maple the machine actually poured in the cup. We sumarized all results in an Excel spreadsheet that is actually included together with the Workbench application. Click the "Open file" button on top of the Estimation tab, and you will be able to see it there:
Let's open it and click on the "Estimate" button up there:
As you can see, sometimes the machine produced less than 100ml, and sometimes produced more. The estimation analysis is also telling us that the Normal distribution is a good candidate in comparison to the other alternatives in the list at the center. However, it is not telling us it is a good assumption after all.
But in this case, we have another thing going for us. It turns out that the normal distribution is also known as the "normal distribution of errors." The point is that, everytime the machine pours liquid into the bottle, there are many possible sources of errors during the process. For instance, the injection nozzle might have clogged for a brief while, the thickness of the maple flutuated, the sensor that counts the time until the nozzle stops is not very precise, and so on.
Each step in this process may add a little error that accumulates and shows up as the final error we get at the end. The summation of all those factors is what makes the machine pour 95ml, 98ml, or 105ml instead of 100ml per bottle. Now, the nice thing is that when multiple sources of errors are added together, each of them with their own unknown distributions, the sum of those errors tends to be a normal distribution. To see this, consider watching the Quincux machine—also known as Galton's board—at work:
Okay, neat. So let's go with the Normal distribution then. From the estimated distribution, it seems that even if our machine is configured to pour 100ml, in average it poured 99.77ml (which is quite close) with a standard deviation of 2.32.
Good. But what exactly such standard deviation means in practical terms?
Let's switch to the Analysis tab to find out. In the analysis tab we can see how different volumes produced by our machine. It seems that most of the bottles end up having around 95ml to 105ml. So let's check what is the current probability that our machine may fill a bottle with less than 100ml:
According to the normal distribution, it seems that our machine might produce bottles that have less than 100ml more than 50% of the time, which is clearly not a good signal. Remember, we must produce less than 5% bottles with less than 100ml only. What can we do then? Well, let's check what are the worst 5% bottles we are doing producing right now by adjusting the distribution.
According to the distribution, 5% of the currently produced bottles are being filled with only 95.95ml. Now, let's repositionate our distribution so those worst 5% happen just before our 100ml target:
Great! So it turns out that if we set our machine to produce 104ml instead of 100ml, we will produce incorrect bottles only up to 5% of the time. This way we can respect the constraints required by the supermarket without wasting resources on other bottles.
Now that we have new parameters for our distribution, let's generate some new samples to see which kind of volumes we could expect after the machine is adjusted.
As it should be seen, the expected number of values below 100 in the generated list should be less than 5.
The cool part is that the application shown above is entirely based on reflection. The Statistics Workbench itself doesn't know anything special about each of the different distributions. Instead, it uses reflection to list and inspect every probability distribution implemented in the Accord.NET Framework to operate. Even the documentation pages shown in the application are actually extracted from the IntelliSense documentation that accompanies the framework.
The Accord.NET Framework is a .NET machine learning framework combined with audio and image processing libraries. It is completely written in C# and can be used in any .NET application, including WinForms, WPF, Windows Store and even Android and iOS (through Xamarin and Shim). It is a complete framework for building production-grade computer vision, computer audition, signal processing and statistics applications for both free and commercial use.
Since most research fields use statistics in one way or the other, the statistics module of the framework is one of the most developed to date. As of this writing, the framework offers 50 univariate continuous distributions, 9 univariate discrete distributions, 8 multivariate continuous and 3 multivariate discrete ones. The current list of distributions include:
The framework can also create full-fledged distribution implementations based only user-suplied lambda functions defining a CDF, a PDF, or both. The framework can automatically compute all necessary measures and functions from the given functions through numerical optimization, providing the mode, median, expected value, hazard functions, quantile functions and many others just from a single lambda function specified by the user. Example:
The framework also include hypothesis tests that you can use to test several hypothesis about your data, such as to what distribution it belongs, whether we should trust their estimated parameters or not, and much more. However, this might be content for another article.
Currently, the Workbench supports and displays only univariate distributions. However, as listed above, the framework provides much more than that. The distributions' namespaces are divided into Accord.Statistics.Distributions.Univariate and Accord.Statistics.Distributions.Multivariate. Univariate distributions implement the IUnivariateDistribution interface, while multivariate ones implement IMultivariateDistribution. Both of them derive from the most general IDistribution interface, that basically specifies only the CDF and PDF methods that all distributions must implement.
Fig 3. Interfaces for multivariate and univariate distributions in the Accord.NET Framework.
Now, each of those are further divided into either Continuous or Discrete implementations. For each of them, there is a base class that provides default methods for several functionalities associated with a probability distribution. For example, if we implement a new Continuous distribution and specify only its CDF and PDF functions, inheriting from UnivariateContinuousDistribution will provide us a default implementation for finding the distribution's Median and a default InverseDistributionFunction. We will then be able to use the Median and the ICDF in our new distribution without ever having to actually implement them.
Fig 4. Base classes for continuous and discrete univariate distributions. Note how only the Mean,
the Variance, the Support and the Distribution Function and Density/Mass Functions need to
be specified by base classes (they are in italic, meaning they are abstract methods). Specifying
those 5 items, every other item is immediatelly available, such as the quantile function,
the Median, and generation of new samples from the distribution.
Distributions whose parameters can be estimated from data implement the IFittableDistribution interface. This interface provides a generic Fit method whose argument types match the type of the observations expected by the distribution. For example, a NormalDistribution would expect its observations to be double numbers, and as such, implements IFittableDistribution<double>. In the same way, a discrete Poisson distribution expects its observations to be integers, and as such implements IFittableDistribution<int>.
Some distributions can also take special options on how their parameters should be estimated. In this case, the interface also allows for an extra parameter that specifies which options it supports. Options are defined in options objects, such as NormalOptions.
Fig5. The IFittableDistribution interface. This method can be called passing the
observations that the distribution should attempt to fit, the individual weights for
each observation and any special fitting options that should be used, if any.
The framework also has some special distributions that are actually meant to be combined with others. Examples are the Mixture<T> distribution, the MultivariateMixture<T>, the Independent and the Independent<T>. Those can be instantiated as Mixture<NormalDistribution>, Mixture<BernoulliDistribution>, MultivariateMixture<MultivariateNormalDistribution>, Independent<NormalDistribution>, and so on. Let's see a few examples on how the framework can be used below, and reserve those last ones as more advanced cases to the end.
Let's say that in our application we would need to create a Normal (Gaussian) distribution with a specific mean and standard deviation. In order to do that, let's first import the framework's namespaces into our source file:
using Accord.Statistics;
using Accord.Statistics.Distributions.Univariate;
After that, lets create a Normal distribution with μ= 4 and σ= 4.2
var normal = new NormalDistribution(mean: 4, stdDev: 4.2);
Now we can query any property of the distribution as we would like:
double mean = normal.Mean;
double median = normal.Median;
double mode = normal.Mode;
double stdDev = normal.StandardDeviation;
double var = normal.Variance;
And we can also query its associated functions:
double cdf = normal.DistributionFunction(x: 1.4);
double pdf = normal.ProbabilityDensityFunction(x: 1.4);
double lpdf = normal.LogProbabilityDensityFunction(x: 1.4);
double ccdf = normal.ComplementaryDistributionFunction(x: 1.4);
double icdf = normal.InverseDistributionFunction(p: cdf);
double hf = normal.HazardFunction(x: 1.4);
double chf = normal.CumulativeHazardFunction(x: 1.4);
string str = normal.ToString();
Note that those functions and measures are part of the general IDistribution interface. As such, no matter what distribution we create, the usage is always the same. For example, let's switch our Normal distribution for a discrete Poisson distribution instead:
PoissonDistribution poisson = new PoissonDistribution(0.7);
double mean = poisson.Mean;
double median = poisson.Median;
double mode = poisson.Mode;
double stdDev = poisson.StandardDeviation;
double var = poisson.Variance;
double cdf = poisson.DistributionFunction(k: 1);
double pdf = poisson.ProbabilityMassFunction(k: 1);
double lpdf = poisson.LogProbabilityMassFunction(k: 1);
double ccdf = poisson.ComplementaryDistributionFunction(k: 1);
int icdf = poisson.InverseDistributionFunction(p: cdf);
double hf = poisson.HazardFunction(x: 1);
double chf = poisson.CumulativeHazardFunction(x: 1);
string str = poisson.ToString();
We can also create a multidimensional distribution in the same way. In the next example, let's see how we can create a multidimensional Gaussian distribution and compute some of its measures:
var dist = new MultivariateNormalDistribution
(
mean: new double[] { 4, 2 },
covariance: new double[,]
{
{ 0.3, 0.1 },
{ 0.1, 0.7 }
}
);
double[] mean = dist.Mean;
double[] median = dist.Median;
double[] mode = dist.Mode;
double[,] cov = dist.Covariance;
double[] var = dist.Variance;
int dimensions = dist.Dimension;
double pdf1 = dist.ProbabilityDensityFunction(2, 5);
double pdf2 = dist.ProbabilityDensityFunction(4, 2);
double pdf3 = dist.ProbabilityDensityFunction(3, 7);
double lpdf = dist.LogProbabilityDensityFunction(3, 7);
double cdf = dist.DistributionFunction(3, 5);
double ccdf = dist.ComplementaryDistributionFunction(3, 5);
It might be the case that, instead of having specific values for the mean and standard deviation, we would like to estimate a Normal distribution directly from a set of values. For example, let's assume we have the following values:
double[] observations = { 0.10, 0.40, 2.00, 2.00 };
var normal = new NormalDistribution();
normal.Fit(observations);
string text = normal.ToString()
Now, let's suppose that some of our samples are actually more significant than others. Some of them have more weight. In this case, we can specify a real value associated with each of the observations giving how much weight each particular observation has in comparison to others. We can then pass both vectors, the observations and the weights, to the distribution fitting process as shown below.
double[] observations = { 0.10, 0.40, 2.00, 2.00 };
double[] weights = { 0.25, 0.25, 0.25, 0.25 };
var normal = new NormalDistribution();
normal.Fit(observations, weights);
string text = normal.ToString()
The following example shows how to fit one multidimensional Gaussian distribution to a set of observations. Unfortunately, those observations are linearly dependent and result in a non-positive definite covariance matrix. In order to circunvent this problem, we pass a fitting options object specifying that the estimation should be done in a robust manner:
double[][] observations =
{
new double[] { 1, 2 },
new double[] { 2, 4 },
new double[] { 3, 6 },
new double[] { 4, 8 }
};
var normal = new MultivariateNormalDistribution(2);
normal.Fit(observations, new NormalOptions()
{
Robust = true
});
It is possible to generate new samples from any univariate distribution in the framework. Some distributions have specialized sample generation methods that are faster than others, but all of them can be sampled, be through a specialized method or using the default Quantile Function method.
The following example shows how to generate 1000000 samples from a Normal distribution with mean 2 and standard deviation 5.
var normal = new NormalDistribution(2, 5);
double[] samples = normal.Generate(1000000);
var actual = NormalDistribution.Estimate(samples);
string result = actual.ToString("N2");
The following example shows how to generate 1000000 samples from a Binomial distribution with 4 trials and a probability of success of 0.2.
var binomial = new BinomialDistribution(4, 0.2);
double[] samples = target.Generate(1000000).ToDouble();
var actual = new BinomialDistribution(4);
actual.Fit(samples);
string result = actual.ToString("N2");
The following example shows how to generate 1000000 samples from a Multivariate Normal Distribution with mean vector [2, 6] and covariance matrix [2 1; 1 5].
double[] mu = { 2.0, 6.0 };
double[,] cov =
{
{ 2, 1 },
{ 1, 5 }
};
var normal = new MultivariateNormalDistribution(mu, cov);
double[][] samples = normal.Generate(1000000);
var actual = MultivariateNormalDistribution.Estimate(samples);
Creating a new probability distribution
In the Accord.NET Framework, there are two ways to create a new probability distribution: using lambda functions or using inheritance. While the later is the prefered way to create new distributions since it is much easier to share those distributions accross different classes and projects, using lambda functions might easier for writing quick-and-dirty code when we would like to test something as fast as possible.
Using lambda functions
To create a new distribution using a lambda function we can use the GeneralContinuousDistribution class. This class can create new distributions based on a lambda function defining the CDF, the PDF, or both functions or the desired distribution.
double mu = 5;
double sigma = 4.2;
Func<double, double> df = x =>
1.0 / (sigma * Math.Sqrt(2 * Math.PI)) * Math.Exp(-Math.Pow(x - mu, 2) / (2 * sigma * sigma));
var distribution = GeneralContinuousDistribution.FromDensityFunction(df);
double mean = distribution.Mean;
double median = distribution.Median;
double var = distribution.Variance;
double mode = distribution.Mode;
double cdf = distribution.DistributionFunction(x: 1.4);
double pdf = distribution.ProbabilityDensityFunction(x: 1.4);
double lpdf = distribution.LogProbabilityDensityFunction(x: 1.4);
double ccdf = distribution.ComplementaryDistributionFunction(x: 1.4);
double icdf = distribution.InverseDistributionFunction(p: cdf);
double hf = distribution.HazardFunction(x: 1.4);
double chf = distribution.CumulativeHazardFunction(x: 1.4);
Using inheritance
To create a new distribution using inheritance, first you need to know which kind of distribution you would like to create. You will need to create a new class and then choose one of the following classes to inheric from: UnivariateContinuousDistribution, UnivariateDiscreteDistribution, MultivariateContinuousDistribution or MultivariateDiscreteDistribution. Once you know what base class you have to choose, implement all virtual methods required by this class.
For example, let's suppose we would like to implement the Rademacher distribution, as given in Wikipedia.
namespace MyApplicationNamespace
{
class RademacherDistribution
{
}
}
From the Wikipedia description, it is written: "In probability theory and statistics, the Rademacher distribution (which is named after Hans Rademacher) is a discrete probability distribution where a random variate X has a 50% chance of being either +1 or -1.[1]"
Since this is a discrete probability distribution, now we know we would need to be inheriting from UnivariateDiscreteDistribution. So let's do it, right click the class name, and implement all of its virtual methods:
class RademacherDistribution : UnivariateDiscreteDistribution
{
public override double Mean
{
get { throw new NotImplementedException(); }
}
public override double Variance
{
get { throw new NotImplementedException(); }
}
public override double Entropy
{
get { throw new NotImplementedException(); }
}
public override AForge.IntRange Support
{
get { throw new NotImplementedException(); }
}
public override double DistributionFunction(int k)
{
throw new NotImplementedException();
}
public override double ProbabilityMassFunction(int k)
{
throw new NotImplementedException();
}
public override string ToString(string format, IFormatProvider formatProvider)
{
throw new NotImplementedException();
}
public override object Clone()
{
throw new NotImplementedException();
}
}
Now, all we have to do is to fill those missing fields:
class RademacherDistribution : UnivariateDiscreteDistribution
{
public override double Mean
{
get { return 0; }
}
public override double Variance
{
get { return 1; }
}
public override double Entropy
{
get { return System.Math.Log(2); }
}
public override AForge.IntRange Support
{
get { return new AForge.IntRange(-1, +1); }
}
public override double DistributionFunction(int k)
{
if (k < -1) return 0;
if (k >= 1) return 1;
return 0.5;
}
public override double ProbabilityMassFunction(int k)
{
if (k == -1) return 0.5;
if (k == +1) return 0.5;
return 0.0;
}
public override string ToString(string format, IFormatProvider formatProvider)
{
return "Rademacher(x)";
}
public override object Clone()
{
return new RademacherDistribution();
}
}
After the distribution has been created, we will be able to query it even for things we didn't implement, such as its Inverse Distribution Function, Hazard Function, and others:
var dist = new RademacherDistribution();
double median = dist.Median;
double mode = dist.Mode;
double lpdf = dist.LogProbabilityMassFunction(k: -1);
double ccdf = dist.ComplementaryDistributionFunction(k: 1);
int icdf1 = dist.InverseDistributionFunction(p: 0);
int icdf2 = dist.InverseDistributionFunction(p: 1);
double hf = dist.HazardFunction(x: 0);
double chf = dist.CumulativeHazardFunction(x: 0);
string str = dist.ToString();
Let's say you have a bunch of data, and you would like to discover which statistical distribution would be a good fit for it. The Accord.NET Framework allows you to rank statistical distributions according to they goodness-of-fit using, for example, Kolmogorov-Smirnov's suite of tests.
var poisson = new PoissonDistribution(lambda: 0.42);
double[] samples = poisson.Generate(1000000).ToDouble();
var analysis = new DistributionAnalysis(samples);
analysis.Compute();
var mostLikely = analysis.GoodnessOfFit[0];
var result = mostLikely.Distribution.ToString();
As you can see, the framework could correctly guess that the samples came from a Poisson distribution.
The following example shows how to create a mixture distribution of any number of component distributions.
Mixture<NormalDistribution> mix = new Mixture<NormalDistribution>(
new NormalDistribution(2, 1), new NormalDistribution(5, 1));
double mean = mix.Mean;
double median = mix.Median;
double var = mix.Variance;
double cdf = mix.DistributionFunction(x: 4.2);
double ccdf = mix.ComplementaryDistributionFunction(x: 4.2);
double pmf1 = mix.ProbabilityDensityFunction(x: 1.2);
double pmf2 = mix.ProbabilityDensityFunction(x: 2.3);
double pmf3 = mix.ProbabilityDensityFunction(x: 3.7);
double lpmf = mix.LogProbabilityDensityFunction(x: 4.2);
double icdf1 = mix.InverseDistributionFunction(p: 0.17);
double icdf2 = mix.InverseDistributionFunction(p: 0.46);
double icdf3 = mix.InverseDistributionFunction(p: 0.87);
double hf = mix.HazardFunction(x: 4.2);
double chf = mix.CumulativeHazardFunction(x: 4.2);
string str = mix.ToString(CultureInfo.InvariantCulture);
The next example shows how to estimate one mixture distribution directly from data.
var samples1 = new NormalDistribution(mean: -2, stdDev: 1).Generate(100000);
var samples2 = new NormalDistribution(mean: +4, stdDev: 1).Generate(100000);
var samples = samples1.Concatenate(samples2);
var mixture = new Mixture<NormalDistribution>(
new NormalDistribution(-1),
new NormalDistribution(+1));
mixture.Fit(samples);
var a = mixture.Components[0].ToString("N2");
var b = mixture.Components[1].ToString("N2");
The following example shows how to create multivariate Gaussian mixture models, and how to convert them to multivariate Normal mixtures.
double[][] samples =
{
new double[] { 0, 1 },
new double[] { 1, 2 },
new double[] { 1, 1 },
new double[] { 0, 7 },
new double[] { 1, 1 },
new double[] { 6, 2 },
new double[] { 6, 5 },
new double[] { 5, 1 },
new double[] { 7, 1 },
new double[] { 5, 1 }
};
var gmm = new GaussianMixtureModel(components: 2);
double error = gmm.Compute(samples);
int c0 = gmm.Gaussians.Nearest(samples[0]);
int c1 = gmm.Gaussians.Nearest(samples[1]);
int c7 = gmm.Gaussians.Nearest(samples[7]);
int c8 = gmm.Gaussians.Nearest(samples[8]);
MultivariateMixture<MultivariateNormalDistribution> mixture =
gmm.ToMixtureDistribution();
The following example shows how to create a multivariate distribution by assuming that each dimension of the data is governed by uncorrelated univariate distributions.
double[][] samples =
{
new double[] { 0, 1 },
new double[] { 1, 2 },
new double[] { 1, 1 },
new double[] { 0, 7 },
new double[] { 1, 1 },
new double[] { 6, 2 },
new double[] { 6, 5 },
new double[] { 5, 1 },
new double[] { 7, 1 },
new double[] { 5, 1 }
};
var independent = new Independent<NormalDistribution>(
new NormalDistribution(), new NormalDistribution());
independent.Fit(samples);
var a = independent.Components[0].ToString("N2");
var b = independent.Components[1].ToString("N2");
In the discrete case, this can be represented by a joint distribution.
The following example shows how to create a non-parametric distribution from the samples themselves, without assuming one particular form for the shape of the distribution. Those distributions include the Empirical Distribution, the Multivariate Empirical Distribution, and the Empirical Hazard Distribution.
double[] samples = { 5, 5, 1, 4, 1, 2, 2, 3, 3, 3, 4, 3, 3, 3, 4, 3, 2, 3 };
var distribution = new EmpiricalDistribution(samples);
double mean = distribution.Mean;
double median = distribution.Median;
double var = distribution.Variance;
double mode = distribution.Mode;
double chf = distribution.CumulativeHazardFunction(x: 4.2);
double cdf = distribution.DistributionFunction(x: 4.2);
double pdf = distribution.ProbabilityDensityFunction(x: 4.2);
double lpdf = distribution.LogProbabilityDensityFunction(x: 4.2);
double hf = distribution.HazardFunction(x: 4.2);
double ccdf = distribution.ComplementaryDistributionFunction(x: 4.2);
double icdf = distribution.InverseDistributionFunction(p: cdf);
double smoothing = distribution.Smoothing;
string str = distribution.ToString();
Or in the multivariate case, using kernels:
double[][] samples =
{
new double[] { 0, 1 },
new double[] { 1, 2 },
new double[] { 5, 1 },
new double[] { 7, 1 },
new double[] { 6, 1 },
new double[] { 5, 7 },
new double[] { 2, 1 },
};
IDensityKernel kernel = new EpanechnikovKernel(dimension: 2);
var dist = new MultivariateEmpiricalDistribution(kernel, samples);
double[] mean = dist.Mean;
double[] median = dist.Median;
double[] var = dist.Variance;
double[,] cov = dist.Covariance;
double pdf1 = dist.ProbabilityDensityFunction(new double[] { 2, 1 });
double pdf2 = dist.ProbabilityDensityFunction(new double[] { 4, 2 });
double pdf3 = dist.ProbabilityDensityFunction(new double[] { 5, 7 });
double lpdf = dist.LogProbabilityDensityFunction(new double[] { 5, 7 });
Before finishing this article, I wanted to give a bit more history about the Accord.NET Framework and explain where it originated from.
Since the early university years I have been working with statistics, one way or the other. In college, I started working with neural networks, and in the masters, with support vector machines, hidden Markov Models and hidden Conditional Random Fields. To work with those, I learned about data preprocessing, data transformation, projections, feature extraction, statistics, information theory, mathematics, image processing, mathematical optimization, machine learning and a few other fields.
From this experience, I was able to see how statistics played a crucial role in almost all of the fields I have passed through. Thus in order to exactly understand everything that I was working with, since the first days I started organizing my studies and the knowledge I was gathering in the most optimal way that I could found. Truth is, I have a terrible memory, and I knew that making notes, drawings, or having a shelf full of books would simply not work. I needed a way to store what I learned in a way that I could retrieve it fast. In a way that even details could be covered quickly and precisely, and in a place that the myself of the future would be able to find and research it wherever I would be.
And the most optimal way that I found to do that was to write any acquired knowledge in code. Over the years, this process created a software framework with online documentation including points to the literature I was reading at the time, and well-commented source code simple enough so I could refresh my memory in minutes. By leting it be open-source and available in a public repository, I could read it from anywhere. By sharing it under a permissive license I could have mistakes noticed and corrected in a minute. After a few years, the Accord.NET Framework was thus born.
If you are interested in building your own machine learning, statistics and image processing applications in .NET, take a few moments to see what the framework can already do for you. Installing the framework is very easy: from Visual Sudio, locate the framework NuGet packages and add them to your project. In the command window, type:
PM> Install-Package Accord.MachineLearning
and this is all that is needed to get the framework up and running for you.
In this article, we discussed about statistics and presented an application that can help students and users explore and understand how statistics can be applied to real world problems. We presented a WPF application that was created using the Accord.NET Framework that could teach, exemplify, instantiate and estimate several univariate statistical distributions.
Finally, we presented how all of those same functionalities could be achieved in code using the Statistics module of the Accord.NET Framework, giving several examples on this could be accomplished.
- May 16th, 2015: First version published.
- May 18th, 2015: Corrected a binary packaging problem.
- Christopher M. Bishop (2006), Pattern Recognition and Machine Learning (Information Science and Statistics). Springer-Verlag New York, Inc., Secaucus, NJ, USA.
- Taleb, Nassim Nicholas (2007), The Black Swan: The Impact of the Highly Improbable, Random House.
- Hastie, T.; Tibshirani, R. & Friedman, J. (2001), The Elements of Statistical Learning , Springer New York Inc. , New York, NY, USA.
- Hollander, M, & Wolfe, D (1999), Nonparametric Statistical Methods, 2nd Edition. Wiley.

