Source code available at https://bitbucket.org/pamungkas5/bcbcurl/
Introduction
Curl is a great command line tool for data transfer with URL syntax. It support FTP, FTPS, Gopher, HTTP, HTTPS, IMAP, IMAPS, LDAP, LDAPS, POP3, and many more. It's library (LibCurl) is widely used in many project.
In this article I try to present my method of embedding LibCurl in a simple download manager application named BCBCurl.
Compiler used: Embarcadero C++ Builder XE3.
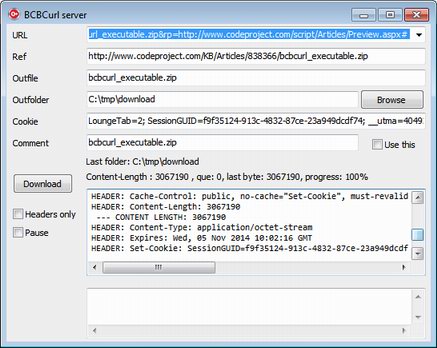
Background
Previously I use curl.exe command line tool and FreeDownloadManager for my downloading activity. Each with their own strength and weakness.
The main reason I develop this program is because I need a download manager with features presented in this table:
| Feature supported | curl | FDM | BCBCurl |
| Set URL from command line | YES | YES | YES |
| Set output file from command line | YES | NO | YES |
| Set referer from command line | YES | NO | YES |
| Set cookie from command line | YES | NO | YES |
| Auto resume broken download | NO | YES | YES
|
| Download queing | NO | YES | YES |
| Multi thread download | NO | YES | TODO |
| Socks protocol | YES | NO | TODO |
Using the code
The program has two thread, the main thread responsible for user interface and the worker thread for downloading. I use "easy" libcurl API for downloading. It's a blocking socket, so I separated it in a different thread. Messages from downloader thread passed to main thread using a FIFO list. LibCurl actually has nonblocking functions, but I haven't tried to use them though.
BCBCurl can run in two different modes, the first it can run as a server that do the actual downloading and stay active, second as a client that only receive task from command line and send them to the server's downloading queue then exit. Command sent from client to server via a shared memory. This option is usefull when you call BCBCurl from a script, and you have a choice between wait for the download to finish or simply put it in a que.
Here's the function that invokes LibCurl downloading mechanism:
(it's based on LibCurl download in memory sample code)
int do_curl(TThreadCurl *chunk, unsigned long range_from, unsigned long range_to, int headeronly) {
chunk->status = CURL_STARTED;
CURL *curl_handle;
CURLcode res;
curl_handle = curl_easy_init();
curl_easy_setopt(curl_handle, CURLOPT_URL, chunk->url.c_str());
if (chunk->referer != "") {
curl_easy_setopt(curl_handle, CURLOPT_REFERER, chunk->referer.c_str());
}
if (chunk->cookie != "") {
curl_easy_setopt(curl_handle, CURLOPT_COOKIE, chunk->cookie.c_str());
}
curl_easy_setopt(curl_handle, CURLOPT_LOW_SPEED_LIMIT, 1);
if (chunk->invalid) {
chunk->status = CURL_TERMINATED;
return 0;
}
int len;
char *unescaped = curl_easy_unescape(curl_handle, chunk->url.c_str(), chunk->url.Length(), &len);
chunk->unescaped = unescaped;
curl_free(unescaped);
curl_easy_setopt(curl_handle, CURLOPT_HEADERFUNCTION, header_callback);
curl_easy_setopt(curl_handle, CURLOPT_HEADERDATA, (void*) chunk);
curl_easy_setopt(curl_handle, CURLOPT_SSL_VERIFYPEER, 0L);
curl_easy_setopt(curl_handle, CURLOPT_SSL_VERIFYHOST, 0L);
curl_easy_setopt(curl_handle, CURLOPT_WRITEFUNCTION, WriteMemoryCallback);
curl_easy_setopt(curl_handle, CURLOPT_WRITEDATA, (void*) chunk);
if(headeronly > 0) {
curl_easy_setopt(curl_handle, CURLOPT_HEADER, 1);
curl_easy_setopt(curl_handle, CURLOPT_NOBODY, 1);
}
if ((range_from + range_to) > 0) {
AnsiString srange = AnsiString().sprintf("%ld-%ld", range_from, range_to);
msglist->Add("\r\n---\r\nDownload range: " + srange);
curl_easy_setopt(curl_handle, CURLOPT_RANGE, srange.c_str());
chunk->start_byte = range_from;
chunk->last_byte = range_from;
chunk->stop_byte = range_to;
chunk->size_downloaded = range_from;
}
else
if (chunk->stop_byte > chunk->last_byte) {
AnsiString autorange = AnsiString().sprintf("%ld-%ld", chunk->last_byte, chunk->stop_byte);
msglist->Add("Autorange: " + AnsiString(autorange));
curl_easy_setopt(curl_handle, CURLOPT_RANGE, autorange.c_str());
chunk->last_byte = chunk->last_byte;
chunk->stop_byte = chunk->stop_byte;
chunk->size_downloaded = chunk->last_byte;
}
else
if (chunk->stop_byte > 0 && chunk->last_byte > 0) {
msglist->Add("nothing to do");
chunk->status = CURL_TERMINATED;
return 0;
}
curl_easy_setopt(curl_handle, CURLOPT_USERAGENT, "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.8) Gecko/20050511 Firefox/1.0.4");
res = curl_easy_perform(curl_handle);
if(res != CURLE_OK) {
msglist->Add("Err: " + AnsiString(curl_easy_strerror(res)));
chunk->status = CURL_TERMINATED;
}
curl_easy_cleanup(curl_handle);
chunk->status = CURL_TERMINATED;
return res;
}
msglist is a TList object used as FIFO buffer to send message to the server.
chunk (TThreadCurl object) contains chunk of data downloaded from web server and some download parameters. The memory variable allocated dynamicaly according to Content Length header.
class TThreadCurl : public TThread
{
public:
char *memory;
size_t size_downloaded;
size_t size_memory;
unsigned long content_length;
unsigned long start_byte;
unsigned long stop_byte;
unsigned long last_byte;
int can_resume;
int invalid;
AnsiString url;
AnsiString unescaped;
AnsiString referer;
AnsiString cookie;
int status;
int http_code;
int download_step;
...
}
referer and cookie can be set from command line parameter if BCBCurl called from a browser. I use Flashgot addon to call BCBCurl from within Firefox.
Libcurl download process use two function:
1. header_callback() to process header from the web server.
2. WriteMemoryCallback() to capture downloaded content from webserver.
header_callback function:
This function will be called when LibCurl downloading header data from web server.
size_t header_callback(char *buffer, size_t size, size_t nmemb, void *userdata)
{
TPerlRegEx *pcre = new TPerlRegEx();
TThreadCurl *curl = (TThreadCurl *)userdata;
pcre->RegEx = "(ACCEPT-RANGE)";
pcre->Options = TPerlRegExOptions() << preCaseLess;
pcre->Subject = AnsiString(buffer);
if (pcre->Match()) {
msglist->Add(buffer);
curl->can_resume = 1;
}
pcre->RegEx = "HTTP\\/.*\\s*(\\d\\d\\d)";
pcre->Options = TPerlRegExOptions() << preCaseLess;
pcre->Subject = AnsiString(buffer);
if (pcre->Match()) {
curl->http_code = StrToInt(pcre->Groups[1]);
if (curl->http_code > 206) {
curl->invalid = 1;
}
}
pcre->RegEx = "Content-Disposition:";
pcre->Options = TPerlRegExOptions() << preCaseLess;
pcre->Subject = AnsiString(buffer);
if (pcre->Match()) {
pcre->RegEx = "Content-Disposition:.*filename=[\"\'](.*)[\"\']";
pcre->Options = TPerlRegExOptions() << preCaseLess;
pcre->Subject = AnsiString(buffer);
if (pcre->Match()) {
curl->header_filename = pcre->Groups[1];
} else {
pcre->RegEx = "Content-Disposition:.*filename=\\s*([^\\s]+)[\\s$]";
pcre->Options = TPerlRegExOptions() << preCaseLess;
pcre->Subject = AnsiString(buffer);
if (pcre->Match()) {
curl->header_filename = pcre->Groups[1];
}
}
}
pcre->RegEx = "CONTENT-LENGTH\\s*:\\s*(\\d+)";
pcre->Options = TPerlRegExOptions() << preCaseLess;
pcre->Subject = AnsiString(buffer);
if (pcre->Match()) {
msglist->Add(" --- CONTENT LENGTH: " + pcre->Groups[1]);
unsigned long ctlen = StrToInt(pcre->Groups[1]);
if (ctlen > curl->content_length) {
curl->content_length = ctlen;
}
size_t total_chunk_size = curl->content_length + 1;
curl->memory = (char *) realloc(curl->memory, total_chunk_size);
curl->size_memory = total_chunk_size;
curl->stop_byte = curl->content_length;
if(curl->memory == NULL) {
msglist->Add("not enough memory (realloc returned NULL)\n");
return 0;
}
}
size_t realsize = size * nmemb;
return realsize;
}
I need to parse header data from web server to get Content-Length, (optionaly) file name, HTTP response code, and to check wether the server support resume downloading. Notice how I use perl Regular Expression to parse header data. I know I can parse text using other method, but once being a perl programmer I just can't live without regex :) .
WriteMemoryCallback function :
This function will be called when LibCurl downloading actual data from web server. It's mainly capturing data from function parameter and store them in memory on the right position.
size_t WriteMemoryCallback(void *contents, size_t size, size_t nmemb, void *userp)
{
size_t realsize = size * nmemb;
TThreadCurl *curl = (TThreadCurl *)userp;
curl->status = CURL_RECEIVING;
size_t total_chunk_size = curl->size_downloaded + realsize + 1;
if (curl->size_memory < total_chunk_size) {
curl->memory = (char *) realloc(curl->memory, total_chunk_size);
curl->size_memory = total_chunk_size;
}
if(curl->memory == NULL) {
msglist->Add("not enough memory (realloc returned NULL)\n");
return 0;
}
unsigned long offset = curl->size_downloaded > 0 ? curl->size_downloaded : 0;
memcpy(&(curl->memory[offset]), contents, realsize);
curl->last_byte = curl->last_byte + realsize;
curl->size_downloaded += realsize;
Application->ProcessMessages();
return realsize;
}
Command line parameter
List of command line parameter processed by BCBCurl:
- -o [explicit output file name]
- -f [suggested filename]
- -d [output folder]
- -k [cookie]
- -r [referer]
- -m [comment]
- -c (no value, set if want to run BCBCurl as client only)
Browser integration
To integrate BCBCurl with browser i use FlashGot addon with following parameter:
-c [URL] [-r REFERER] [-k COOKIE] [-m COMMENT] [-f FNAME]

Points of Interest
Things I learn by making this program are:
- How to use LibCurl in desktop application.
- How to parse command line parameter.
- How to use RegExp in C++ application.
- How to pass data via shared memory.
- How to call BCBCurl from browser.
I realize I haven't explain them completely to make this article short, but I will gladly explain if anyone asking.
BCBCurl executable is included in this article. As for source code you can get it from https://bitbucket.org/pamungkas5/bcbcurl/

