A french version of this article is available on my blog.
Introduction
If programming is a complex activity when working alone, the difficulty is greatly amplified when the program requires to work with others, because this latter case usually requires an architecture divided into restricted area to allow good separation of concepts.
Although this type of architecture is often implemented, the interdependence between modules is the weak point which forces developers to flout all good practices of separations to achieve their goal.
In this article, I will discuss an advanced solution of "Data Transformation" to ensure that your modular architecture remains as respectful as possible of the SOLID principles.
Background
The separation of a software in several layers or modules is something very common in the developing world.
This practice, which intended to facilitate maintainability, scalability, and testability of code has some pitfalls. The most classic ocurence is to create interdependence when it's necessary to manipulate objects on the border of the modules.
This problem is even worse because most frameworks, tools and examples push developers to fall into these architectural traps that seem almost inevitable for beginners!
This article will deal with a special architecture in which data transformation will play an important role. This mechanism will allow a perfect separation between your modules while enabling effective communication.
The drift of an architecture
To present you the most frequently encountered problems, I will take the classic case of a business application with a 3-layers architecture:
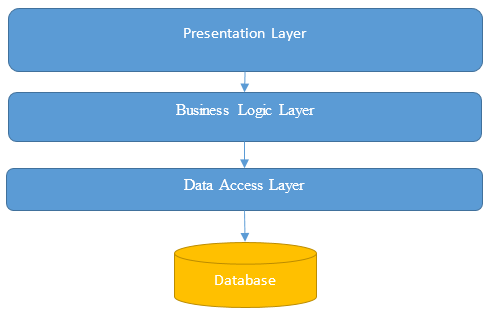
The presentation layer contains code related to the views, the business layer contains the code regarding the business logic (validation rules, entities, workflow, ...) and the data access layer contains the code that interacts with a database.
All this seems to provide a good separation in theory, but how does it happen most of the time?
Generally in an application with this type of architecture, those who work on the DAL have the responsibility to provide and save business objects in the database. It is therefore necessary for them to reference the BLL to manipulate them at ease.
Then, DAL developers quickly realize that their lives will be greatly facilitated if they use a framework to interact with their database. Most modern frameworks (such as Entity Framework) allow to handle autogenerated entities from the data schema. It seems better for developers to use these entities as business objects.
Especially when:
- The framework has an automatic changes detection system based on class instances.
- The framework allows to work with POCO objects supposed to give the possibility to make classes without data schema constraints.
The choice is very quickly took: the BLL will possess the entities generated by the framework to manipulate the database.
Now to the "Presentation" layer.
Those in charge of developing this part must allow users to manipulate business objects (customers, invoices, documents, dashboards, workflow states, ...), sometimes with very complex graphical components (pivot grids, schedules, advanced lists, indicators, etc.)
Fortunately for them, there are many components of this type on the market, and most of them allow you to link directly to a database.
For this, the presentation layer needs to know the object types it will have to handle. It is therefore necessary to reference the BLL in the presentation layer.
But, setting up a GUI is not limited to draw or arrange some graphical components. It's also necessary to do some code to manipulate objects and make them presentable. The design patterns to address this issue (MVC, MVP, MVVM ...) seem to need access to objects in the BLL. So it is very common to find some GUI code that manipulates these entities.
We now move from a theoretically perfectly separated system to something like this:

The technical choices of communication between our modules have led our system to become something highly inter-dependent.
If we look at the project from a tree's perspective, everything seems well separated with directories where code is logically stored. Nevertheless, a dependency graph will show that DLLs are all interdependent and referencing each other.
If someone has the misfortune of wanting to review the architecture, he will very quickly be opposed to the fact that it's impossible to redesign code due to technical entanglement, and for good reason: the instances of business entities are directly used by the data access framework, and are handled by the graphics components! This practice seems even more legitimate when many code samples available on MSDN or other sites highlight these techniques for more simplicity. The problem resides in the fact that beginners take it as face value, and are not always aware of the adverse consequences that it brings, such as non-testability and tight coupling that strongly inhibit scalability of the software and promotes bugs by side effects.
Let us return to the fundamental
The separation of a software into units called "layers" or "modules" comes from the need to isolate the different responsibility areas of our system to serve several purposes:
- To work on a domain without major impact on other areas.
- To have ability to substitute the implementation of a domain with another implementation.
- To test each area independently, according to its technical features.
An architecture in vertical layers is therefore not very suitable.
To serve these objectives, it's necessary to replace the vertical layers architecture with something more logical.
Let's start by making a small Venn diagram to get an overview of our need:
We clearly see that the business domain is the central element of our system. If we think about it, it can be the only scope that we would need if our programs were self-sufficient.
Unfortunately, business softwares should present data to users, save data in databases, interact with external devices or systems, etc. All of this can transform your software into a real monster that can quickly enslave their developers if they are not well controlled.
But beware, all of these areas should not be considered as the business domain. These are only components offering inputs and outputs.
This distinction is very important because the areas overlapping usually lead developers to make "fixture code" that can quickly make strongly coupled modules.
The solution I propose therefore is to make an onion architecture with some specificities.
Explanation
This architecture consists of three main concepts:
- The business part (blue) which is the center of the architecture. Physically, it is a project (DLL) that has all the APIs for manipulating pure business logic. It will contain classes like "Invoice", "Customer", "Subscription" and factories to obtain purely business entities.
- The contract part (yellow) is an area in which there is NO CODE. Physically, these are projects in which there are only interfaces and exception classes. We will see later that these interfaces have to be written in a particular way to be in line with our principle of total independence.
- The peripheral part (green) has implementations of contracts (in yellow). Each device is a specific project and must implement all contracts concerned. The developer of the project will also be in charge of setting up the test environment that will validate the correct implementation of the code.
Although the subject is very interesting, I will not dwell on this architecture and how to implement it, because I'm going to assume that you already know all the good practices to implement a SOLID system.
Instead, I will focus on one point that may seem surprising: how are we going to move from one area to another knowing that our modules do not know each other and only have contracts (intefaces) in common?
If we take for example the interconnection between the Business domain and the SQL Server domain, both are referenced by only one project: the "Data Access Contract". They therefore do not know each other.
This means that the business part will have a "Person" class that will strongly look like another "Person" class located in the SQL part.
But what is the interest of all this? How will we be able to manipulate objects from one world to the other? Isn't it redundant? I'll try to answer these questions ...
What is the interest of all this?
This system that may seem very cumbersome at first, brings a lot of advantages:
- Share the work: a developer can work on the purely business part while another is working on a device without any interference or possible side effects. Several teams can then work vertically on the same topic but at different levels.
- Safe behavior change: You must migrate your DBMS to NoSQL? Your webservice must switch to LDAP? A future update will involve review of calls to a device? Your GUI must return to Winform? No problem! Thanks to the non-existent coupling between your areas, changing the implementation of a device project will have no impact on your business part (or on other devices besides). You can keep the focus on the re-implementation of the target area without worrying about the possible side effects.
- Multiple implementations: Your software should work on many types of databases? Or switch between Oracle, SQL Server and a local Excel file? Or even handling multiple GUI depending on it running on a desktop or a mobile device? Contracts will allow you to play with several implementations through dependency injection.
- Research and bug fixes: Unhandled exceptions and bugs are quickly identified and corrected because each area of responsibility has its own arsenal of specific tests.
How will we be able to manipulate objects from one world to the other?
To answer this question, I will first explain the basic principle:
When a programmer wants to make a real separation between two areas, he has no other choice than creating specific entities for each one.
If these two areas must handle common entities, good practice consists on having a contract that defines the properties of these entities:
With this contract, we are able to ensure that when the two areas speak about a Person, they both agree on the fact that it is an entity with a name and a birthday. All other properties are only information specific to their internal logic and not of any concern to other areas.
But how do we apply the behavior of PersonA when DomainA gets an instance of PersonB? It is quite simple: just make a copy of PersonB in a new instance of PersonA. This action to copy an object to another different type to benefit from his behavior is called "transformation". This is precisely the topic of this article!
Isn't it redundant?
From your very first program, everyone keeps reminding you that you always need to refactor your code. This is also the D principle of the STUPID acronym, namely Duplication. So, is creating several classes to represent the same entity a form of code duplication?
A novice programmer would be strongly tempted to create a specific project in which all entities are stored, then he would ensure that each module can access to this project.
Not only this reasoning is a bad idea, but it is also a violation of several SOLID principles.
Code duplication occurs when you call different instructions to apply the same behavior. This forces programmers to modify each set of instructions when it's necessary to make a change to a desired behavior. It's clear that this bad practice must absolutely be banished from your projects.
But what about our case? Do you think that an entity "Person" of your business logic has the same behavior than an entity "Person" in your data access layer? Surely not!
A "Person" in the business area has some properties like his age when enrolling to the service, properly formatted phone number or a list of products that may be of interest, and a "Person" in the data access layer will have a foreign key, a unique identifier, etc.
We are therefore not in the presence of duplicate code because we must deal with different behaviors. It makes perfect sense for a SOLID architecture that each behavior is separated into different classes.
Choosing the type of contract
Now that everyone understands what motivates this article, let's tackle the heart of the subject. Our goal is to make copies of object that have different structures.
To see which members are to be copied, it's necessary to have a description of the common properties of each object. This description, that can be in many forms, is called a contract.
Those of you who have experience in WCF have probably already heard of this concept because this technology offers DataContracts APIs for serialization mechanisms.
If you are interested in these mechanisms, you've probably looked for more optimized ways to carry out this task, and you have heard of other serialization systems using contracts such as protobuff.
There are also plenty of ways to make a copy of equivalent fields with reflection.
Couldn't one of these methods fulfill our need?
As a software architect, your role is to ensure that your program is easy to understand, usable and modifiable by all the developers who will be working on your project. It's therefore very important to enforce the use of simple methods requiring minimal training, and leave little room for implementation error.
However, what is proposed by the aforementioned tools?
The WCF DataContracts work with attributes. Making a contract using this method consists in tagging each property for the serialization needs. An architecture based on this principle will force developers to maintain a current documentation, or to create a specific tool for designing contracts. In both cases, the heaviness of this technique is subject to omission and does not benefit from the compiler to detect any errors.
Protobuff offers several techniques. One of them also uses attributes. We will not adopt this approach for the reasons mentioned above.
One other is to create a description file that will generate specific code with a third-party tool.
A new developer arriving on your project must be trained to use this tool, its syntax, etc. Any code redesign requires recompilation by the third party tool which generates more extra work. And of course, this technique does not benefit from the detection of errors at compile time.
As for the methods of generic copies using reflection, I think it's not even worth talking about, because as you will understand, they do not require contracts as they are based on matching names and types of properties to do their work. Imagine the possible side effects when someone will rename properties or review a class hierarchy in a code redesign ...
So what do we have left?
We have the interfaces, providing several advantages:
- They are native to the language. Understandable by all without additional training.
- They can be used by code manipulation tools (like ReSharper), which will allow you to generate implementations, doing massive renaming, code navigation, etc.
- They generate compiler errors, leaving little doubt to programmers about how to implement them.
- They respect the principles of OOP
As a software architect, this is obviously the best choice to create contracts that meet our prerequisites.
How to structure the interfaces ?
If you do some internet search, you will notice that using interfaces to help you copy objects is something very uncommon. But why? Is it not a simple and natural way to create a structure description?
Unfortunately, it is much more complicated than it seems, and I'll try to explain the reasons.
When I use an interface to describe a structure to make a copy, all goes well as long as I only work with basic types (string, int, datetime, ...)
The problems begin to appear when our structure should contain other complex types.
In this case, a lazy implementation consists on placing a new member directly in our first interface, to be of the type of the aggregated interface.
Example:
public interface IPerson
{
string FirstName { get; set; }
string LastName { get; set; }
IAddress Address{ get; set;}
}
public interface IAddress
{
string Street { get; set; }
string City { get; set; }
string Country { get; set; }
}
Here, our IPerson contract must contain an address. So we create an IAddress contract that we add as a member of IPerson.
This makes perfect sense for any good C# programmer.
Let's move to a first implementation of these contracts in a domain A:
public class PersonA : IPerson
{
public string FirstName { get; set; }
public string LastName { get; set; }
public DateTime BirthDay { get; set; }
public IAddress Address { get; set; }
}
public class AddressA : IAddress
{
public string Street { get; set; }
public string City { get; set; }
public string Country { get; set; }
}
We can see in the implementation of PersonA that we have an IAddress type member. It would be better for this member to be directly an AddressA class for easier manipulation.
Unfortunately, this is not possible because an interface implementation must have the exact declared types.
Of course, many tricks exist such as declaring a member named Address of type AddressA and implementing it as explicit to be able to manipulate this member.
public class PersonA : IPerson
{
public AddressA Address = new AddressA();
public string FirstName { get; set; }
public string LastName { get; set; }
public DateTime BirthDay { get; set; }
IAddress IPerson.Address
{
get { return Address; }
set {
if( !(value is AddressA) )
throw new Exception("Cannot assign the property because is does not have the matching type AddressA");
Address = (AddressA)value;
}
}
}
However, this technique poses several problems. Not only does it require to type several lines of defensive programming codes, but it creates duplicate properties and it creates a mechanism that will eventually be heavy for the copy.
Another issue of the same type also occurs when our contract musts contain collections of objects.
As our contracts should not possess strongly typed member (because we must remain independent of all adjacent layers), the solution that comes to mind is to use IEnumerable to represent our collections.
public interface IPerson
{
string FirstName { get; set; }
string LastName { get; set; }
DateTime BirthDay { get; set; }
IEnumerable<IAddress> Address { get; set; }
}
But, like aggregations, this technique brings a lot of significant problems. Not only does it require to do some remapping in internal properties, but we cannot synchronize our collections because we have declared them as"read-only" in the contract.
Then, what is the best way?
The right method is to use generic types with check constraints in your interfaces.
public interface IPerson<TAddress> where TAddress : IAddress
{
string FirstName { get; set; }
string LastName { get; set; }
DateTime BirthDay { get; set; }
TAddress Address { get; set; }
}
So, when you move to the implementation, you will only have to declare the type of the generic and voila!
public class PersonA : IPerson<AddressA>
{
public string FirstName { get; set; }
public string LastName { get; set; }
public DateTime BirthDay { get; set; }
public AddressA Address { get; set; }
}
Regarding the collections, we will apply the same technique except that the check constraints should be on the type ICollection
Here is an example with a "Person" class that musts contain multiple phone numbers:
public interface IPhone
{
string Number { get; set; }
string Type { get; set; }
}
public interface IPerson<TAddress, TPhone, TCollectionPhone>
where TAddress : IAddress
where TPhone : IPhone
where TCollectionPhone : ICollection<TPhone>
{
string FirstName { get; set; }
string LastName { get; set; }
DateTime BirthDay { get; set; }
TAddress Address { get; set; }
TCollectionPhone Phones { get; set; }
}
This type of contract reveals all its power for data transformation between the business layer and UI layer because most of the time, the business layer needs simple generic lists while the GUI entities need observable collections in order to be easily binded to the views.
With this generic contract, both worlds can implement the interface by declaring on one side a List<BusinessPhone> and on the other side an ObservableCollection<UiPhone>. This is not a problem for the transformation system!
But how does it go if our subtypes also contain subtypes of the corresponding contracts?
The best method in this case is to separate our contract into two interfaces (or more).
First, a base interface will declare all basic typed members, and a second one will declare all generic typed members. We can apply types constraints (inherited from the base interface) which will avoid having to declare the generic types in every implementation.
For example, supposing we are to add GPS coordinates to our address. The contracts would then become:
public interface IGpsLocation
{
double Latitude { get; set; }
double Longitude { get; set; }
}
public interface IAddress
{
string Street { get; set; }
string City { get; set; }
string Country { get; set; }
}
public interface IAddress<TGpsLocation> : IAddress
where TGpsLocation : IGpsLocation
{
TGpsLocation GpsLocation { get; set; }
}
And the implementation level in our domain A:
public class GpsLocationA : IGpsLocation
{
public double Latitude { get; set; }
public double Longitude { get; set; }
}
public class AddressA : IAddress<GpsLocationA>
{
public string Street { get; set; }
public string City { get; set; }
public string Country { get; set; }
public GpsLocationA GpsLocation { get; set; }
}
public class PersonA : IPerson<AddressA>
{
public string FirstName { get; set; }
public string LastName { get; set; }
public DateTime BirthDay { get; set; }
public AddressA Address { get; set; }
}
Here, the PersonA class is very simple, despite the fact that the contract has an IAddress member with generic constraint.
If you don't understand anything, this is what you must know:
- Contracts are interfaces
- Non-native typed members must be declared as a generic type.
- Members of collection types must also be reported as a generic type with a constraint on the
ICollection interface. - Generic interfaces that contain other generic interfaces can be separated into two parts. A basic interface that contains all native members and a generic interface that inherits from the base interface. Thus, contracts can keep their simplicity declaring only the base interface.
The data transformation system
Now that you know the interest in isolating your layers with contracts, and how to build these contracts, we will move on to the interesting part: the transformation system.
As I have been explaining from the beginning, the aim is to copy data from a source object into a destination object of a different type.
Unfortunately, business softwares must interact with databases that may contain hundreds of tables, and best practice for developers in this case is to use an ORM to evolve peacefully.
However, most ORM provide materialized objects from database, and allow to generate requests for changes to these objects. The detection mechanisms are based directly on the instances maintained by an internal context!
Our problem, then, is not to make a simple copy of data, but to make data synchronization for the cluster of objects to maintain compliance with the ORM.
Now you begin to understand why software architects do not want to take the lead with a real separation of areas :)
Thus, the transformation tool I will present is called MergeCopy because the system can not only copy objects that meet a common contract, but also synchronize the destination with the source without affecting the integrity of object instances that constitute them.
Usage
The MergeCopy system comes in the form of a simple extension method called MergeCopy().
To use it, add to your contract the generic interface IMergeableCopy<T>, where T is the type of the unique identifier of the object's instance that will be accessible via the property "MergeId"
This property is a technical member allowing the MergeCopy to distinguish an object instance from another of the same type in order to synchronize them.
Choosing the right type for this identifier property is at the developer's discretion. Generally, it's mapped to the primary key of the object from the DAL.
Let's reuse the example from the previous section.
First, I add the IMergeableCopy<T> interface to my contracts, assuming my entities will be uniquely identified by a Guid:
public interface IPerson : IMergeableCopy<Guid>
{
string FirstName { get; set; }
string LastName { get; set; }
DateTime BirthDay { get; set; }
}
public interface IPerson<TAddress, TPhone, TCollectionPhone> : IPerson
where TAddress : IAddress
where TPhone : IPhone
where TCollectionPhone : ICollection<TPhone>
{
TAddress Address { get; set; }
TCollectionPhone Phones { get; set; }
}
public interface IPhone : IMergeableCopy<Guid>
{
string Number { get; set; }
string Type { get; set; }
}
public interface IAddress : IMergeableCopy<Guid>
{
string Street { get; set; }
string City { get; set; }
string Country { get; set; }
}
public interface IAddress<TGpsLocation> : IAddress
where TGpsLocation : IGpsLocation
{
TGpsLocation GpsLocation { get; set; }
}
public interface IGpsLocation : IMergeableCopy<Guid>
{
double Latitude { get; set; }
double Longitude { get; set; }
}
Now that my contracts are well defined, I can move on to the implementation in two areas with different responsibilities:
- BusinessDomain will provide APIs for creating and manipulating persons
- StorageDomain will meanwhile have the responsibility to serialize and deserialize the objects in a text file with a specific format.
Let's not forget that physically, BusinessDomain and StorageDomain are two separate DLL that are referenced by a third DLL containing our contracts.
Let's implement everything in the Business section:
First, I will create a base class to centralize the management of the MergeId:
public abstract class Business : IMergeableCopy<Guid>
{
protected Business()
{
MergeId = Guid.NewGuid();
}
public Guid MergeId { get; set; }
}
then, I implement contracts that do not require generic types (they do not contain complex types, as explained earlier):
public class BusinessPhone : Business, IPhone
{
public string Number { get; set; }
public string Type { get; set; }
}
public class BusinessGps : Business, IGpsLocation
{
public double Latitude { get; set; }
public double Longitude { get; set; }
}
Once these classes are implemented , I can go on to the ones that use them:
public class BusinessAddress : Business, IAddress<BusinessGps>
{
public string Street { get; set; }
public string City { get; set; }
public string Country { get; set; }
public BusinessGps GpsLocation { get; set; }
}
public class BusinessPerson : Business, IPerson<BusinessAddress, BusinessPhone, List<BusinessPhone>>
{
public string FirstName { get; set; }
public string LastName { get; set; }
public DateTime BirthDay { get; set; }
public BusinessAddress Address { get; set; }
public List<BusinessPhone> Phones { get; set; }
}
Alright, now let's declare some specific behaviors to our business objects:
public class BusinessPerson : Business, IPerson<BusinessAddress, BusinessPhone, List<BusinessPhone>>
{
private string _lastName;
public string FirstName { get; set; }
public string LastName
{
get { return _lastName; }
set
{
if( string.IsNullOrWhiteSpace(value) )
throw new Exception("The lastname cannot be empty");
_lastName = value.ToUpper();
}
}
public DateTime BirthDay { get; set; }
public BusinessAddress Address { get; set; }
public List<BusinessPhone> Phones { get; set; }
public int Age { get { return DateTime.Now.Year - BirthDay.Year; } }
}
The property "LastName" can not be empty and is converted to uppercase when defined. A new property "Age" has been added to calculate the age of the person depending on his date of birth.
Now, let's implement the Storage part:
public class StoragePerson : Storage, IPerson<StorageAddress, StoragePhone, List<StoragePhone>>
{
public string FirstName { get; set; }
public string LastName{ get; set; }
public DateTime BirthDay { get; set; }
public StorageAddress Address { get; set; }
public List<StoragePhone> Phones { get; set; }
public override string ToString()
{
var builder = new StringBuilder(FirstName + "^" + LastName + "^" + BirthDay + "^" + (Address != null ? Address.ToString() : ""));
foreach (var storagePhone in Phones)
builder.Append("|" + storagePhone);
return builder.ToString();
}
}
public class StorageAddress : Storage, IAddress<StorageGps>
{
public string Street { get; set; }
public string City { get; set; }
public string Country { get; set; }
public StorageGps GpsLocation { get; set; }
public override string ToString()
{
return Street + "^" + City + "^" + Country + "^" + (GpsLocation != null ? GpsLocation.ToString() : "");
}
}
public class StoragePhone : Storage, IPhone
{
public string Number { get; set; }
public string Type { get; set; }
public override string ToString()
{
return Number + "^" + Type;
}
}
public class StorageGps : Storage, IGpsLocation
{
public double Latitude { get; set; }
public double Longitude { get; set; }
public override string ToString()
{
return Latitude + "^" + Longitude;
}
}
public abstract class Storage : IMergeableCopy<Guid>
{
protected Storage()
{
MergeId = Guid.NewGuid();
}
public Guid MergeId { get; set; }
}
As you can see, our purpose here is to generate one line per person with the following format: FirstName Lastname ^ ^ ^ Street BirthDay ^ ^ City ^ Country Latitude Longitude ^ | ^ Type Number | Number Type ^ | ...
But a question arises: how will the business side be able to tell the storage part to save the entity?
Indeed, this article is focused on copying data, as I mainly focused on the DTO problem (Data Transfer Object) that arises between our modules. The question of how to send orders between modules is a general architecture issue to which you will find excellent answers through the use of "Services" and "Repository".
In our case, the DLL that contains the contracts also has interfaces that define how the repository must be implemented. The fundamental difference is that only the Storage section will implement the repository. The business part may have access through a dependency injection mechanism, which is not the subject of this article.
For our example, this is what the Repository interface looks like :
public interface IStorageRepository
{
void SavePerson(string filePath, IPerson person);
}
The implementation located in the Storage section looks like this:
public class StorageRepository : IStorageRepository
{
public void SavePerson(string filePath, IPerson person)
{
var personToSave = new StoragePerson();
personToSave.MergeCopy(person);
File.AppendText("\r\n" + personToSave);
}
}
Here, we can see the magic of transformation!
Some explanations are necessary:
The repository has the function of recording our person in a text file, but as you can see, the argument is a IPerson, which means that the object that will be passed will not have behavior that allows the storage to format the string as explained above.
Thus, we need to transform this IPerson into a StoragePerson. This is the role of the two lines of code that are:
var personToSave = new StoragePerson();
personToSave.MergeCopy(person);
Once we are in possession of a StoragePerson, it becomes easy to save it in the requested file.
To get the opposite effect, that is to say, to have a BusinessPerson from a StoragePerson deserialized, just do the same thing in the service used by the Business section.
For example, if I change my repository as follows:
public interface IStorageRepository
{
IPerson Load(Guid personId);
void SavePerson(string filePath, IPerson person);
}
Imagining that the Storage part implements the Load function, I will create in the Business part a service to handle the Repository
public interface IBusinessService
{
BusinessPerson GetPerson(Guid id);
void SavePerson(BusinessPerson person);
}
public class BusinessService : IBusinessService
{
private readonly IStorageRepository _storageRepository;
public BusinessService(IStorageRepository storageRepository)
{
if (storageRepository == null) throw new ArgumentNullException("storageRepository");
_storageRepository = storageRepository;
}
public BusinessPerson GetPerson(Guid id)
{
var storageObject = _storageRepository.Load(id);
BusinessPerson result = new BusinessPerson();
result.MergeCopy(storageObject);
return result;
}
public void SavePerson(BusinessPerson person)
{
_storageRepository.SavePerson("d:\\database.txt",person);
}
}
As you see in the GetPerson() method, we retrieve a record from the storage, then we turn it into a BusinessPerson. With this strategy, our service has the capacity to do more than just manipulating BusinessObject.
This example has allowed us to establish the following architecture:
Thanks to full decoupling, we can imagine several kinds of substitution, such as:
- Replacing storage part by a mock object in order to test the business side
- Adding a second parallel repository that would save our objects in a database rather than a text file
- Testing some internal logic of the business part by replacing the service through a mock object.
Such malleability opens up a lot of possibilities for software architects. If you are interested in the Behavior Driven Development, it gives you the opportunity to make business applications with test scenarios that can use some records in a completely virtual database. This guarantees robustness for your software at any time!
But this is still a new topic ...
Back to the subject! A few last things to know about MergeCopy:
- Good management of
MergeId does not only handle the case of object copy, but also manages recursive child that points to its parent. So do not worry about infinite loops that can occur in other copying systems. - As your central system architecture, the
MergeCopy has several optimization systems for preventing the copy from slowing down your application too. However, too large or too complex objects that are often processed can have an impact on performance. Be vigilant on this point.
One last thing we have not talked about is the properties' copy order.
Sometimes, a property is based on another property to maintain integrity of controls, for example:
public class BusinessAddress : Business, IAddress<BusinessGps>
{
private string _city;
private string _country;
private BusinessGps _gpsLocation;
public string Street { get; set; }
public string City
{
get { return _city; }
set
{
if(string.IsNullOrWhiteSpace(Street))
throw new Exception("Define street before the city");
_city = value;
}
}
public string Country
{
get { return _country; }
set
{
if (string.IsNullOrWhiteSpace(City))
throw new Exception("Define city before the country");
_country = value;
}
}
public BusinessGps GpsLocation
{
get { return _gpsLocation; }
set
{
if( string.IsNullOrWhiteSpace(Street) || string.IsNullOrWhiteSpace(Country) || string.IsNullOrWhiteSpace(City) )
throw new Exception("define all the properties before the gps location");
_gpsLocation = value;
}
}
}
The business rule depicted here is that the street is filled before the city, the city is filled before the country and the GPS location is informed when all the data are defined.
If you don't tell the MergeCopy what is the right order, it will inevitably fail.
To overcome this problem, the MergeCopy provides an attribute named [MergeCopy] to place on the properties of your classes.
This attribute can be used in several ways:
Using the Order property
With this property, you can specify the exact order in which the copy is to be performed. Several properties can have the same "order". Example:
public class BusinessAddress : Business, IAddress<BusinessGps>
{
private string _city;
private string _country;
private BusinessGps _gpsLocation;
[MergeCopy(Order = 1)]
public string Street { get; set; }
[MergeCopy(Order = 2)]
public string City
{
get { return _city; }
set
{
if(string.IsNullOrWhiteSpace(Street))
throw new Exception("Define street before the city");
_city = value;
}
}
[MergeCopy(Order = 3)]
public string Country
{
get { return _country; }
set
{
if (string.IsNullOrWhiteSpace(City))
throw new Exception("Define city before the country");
_country = value;
}
}
[MergeCopy(Order = 4)]
public BusinessGps GpsLocation
{
get { return _gpsLocation; }
set
{
if( string.IsNullOrWhiteSpace(Street) || string.IsNullOrWhiteSpace(Country) || string.IsNullOrWhiteSpace(City) )
throw new Exception("define all the properties before the gps location");
_gpsLocation = value;
}
}
}
Using the property StackBottom
It happens in some cases that you want one or more properties to be copied first or last.
The MergeCopy consider all the properties of an object as stack elements. Playing with StackBottom and Order, you can tell if the property is to be copied on top or bottom of the stack.
Diagram:
I think you know everything.
Conclusion
The method presented here has been implemented on a health care software where many developers have the opportunity to add new modules on it.
With full decoupling brought by the MergeCopy, different teams can work on several aspects of the software that are the same components of a single business functionality.
The contract system acts like a specification between developers, allowing them to agree on the APIs that must be provided. Any modification of the contract is thus detected at compile time bringing more communication between developers if changes are made to the APIs.
Nonetheless, MergeCopy does not do everything. To take full advantage, you will have to master all the patterns to implement a good SOLID architecture.
The subject is vast and full of pitfalls, but it is only at this price you can put on the market softwares whose users will appreciate each update you provide them.

