See also: Most current code on github.
Introduction
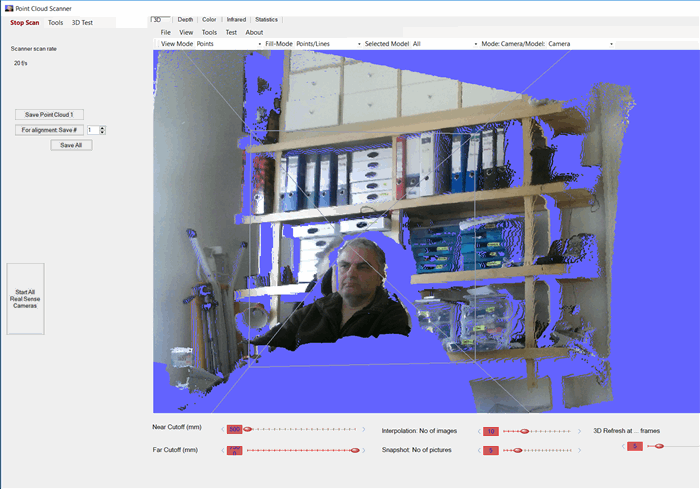
This article is the follow-up of my article on grabbing a point cloud using the Microsoft Kinect v2. Main features:
- grab a point cloud using the Kinect v2 scanner or the Intel Realsense F200 scanner
- real time display of the point cloud in a OpenGL control
- possibility to adjust scanning parameters like maximum depth, scanned point cloud as obj file save
For the details of the OpenGL implementation, please read this article. It uses the library OpenTK as C# interface for OpenGL.
Prerequistes
- Microsoft Kinect SDK v2
- .NET 4.6
- Visual Studio 2015 or higher (for the source code)
Quick Start
A short how for the main program:
- Start the program PointCloudScanner.exe
- Click on „Start Scan“
- Click on „Save Point Cloud“ to save and stop scanning
Motivation
Why not using the Kinect SDK samples
Since some time, but in fact after I published this article, the Kinect SDK samples include the Kinect Studio Explorer, which allows a live viewing of the point cloud in 3D. Before that, only 2D images of the Depth, color, body and infrared frames were possible.
However, the Kinect Studio Explorer is available only as executable file and not as source code, so you cannot use this in your own project,
This available source code allows viewing in 3D as well as some additional features in comparison to the Kinecet Explorer, like cutting the grabbed data etc.
Why OpenGL
First you may ask: Why not use a WPF window for displaying point clouds, but the OpenGL control I used?
Well, in WPF you cannot display simple point clouds. You can only display surfaces (or areas, triangles). So you would have to first program a triangulation – which is not an easy task.
And I have to admit: I dislike WPF.
The main reasons why WPF has been introduced is:
- Separation between UI and logics – which in principle should allow a designer to use Blender for designing the UI, and a programmer to use Visual Studio for coding.
- Support for graphics/animation and desktop programs
There are other reasons like data binding, ability to run in a browser, etc. which I consider to be only not so relevant reasons.
Now the main reasons why I dislike WPF is related to the above points:
- Changing the UI is VERY time consuming – e.g. why should I use two tools for a simple change in the UI?? Code change in the WPF is very tedious. Try to open a simple WPF control in Visual Studio – it takes more than 5 s for displaying. The Message box appearing which says, I could do other tasks during this time is a kind of joke. What other task should I do - I just want to change the code now!
Then you have to search for your control, found out which is the code handler for an event, then search in your code for this method. About 4 steps to do. With Windows Forms this was a double – click. - The support for graphics within WPF is poor and slow. A Point Cloud cannot be displayed in WPF. Displaying large data is slow.
Besides that, the OpenGL community is large, and there are several code tips and libraries which help development.
Code
If you follow the process of scanning starting from clicking on the button to displaying the data in the 3D control, it goes
1. ScannerUC.StartScanning()
We use the Kinect camera, this calls the method
2. KinectBO.StartScanner()
The KinectBO class encapsulates everything done by Kinect, like frame capturing, data conversions to 3D etc.
The StartScanner method sets delegates for receiving the data from the scanner and sets the output to display the data on the user control
3. KinectBO.Scanner_MultiSourceFrameArrived() is called on every frame from the scanner. For displaying the 3D data, the method called is
4. KinectBO.ProcessDepthFrame() and from here, the method:
5. KinectBO.UpdateOpenGLControl()
Here, the frame data is converted to a point cloud in the method:
6. KinectBO.ToPointCloudRenderable(false);
This is done in the line:
7. MetaDataBase.ToPointCloudVertices(this.ColorMetaData, this.DepthMetaData, this.coordinateMapper);
The depth frame data and the color frme data are mapped to world points by
myCoordinateMapper.MapDepthFrameToCameraSpace(myDepthMetaData.FrameData, myRealWorldPoints);
myCoordinateMapper.MapDepthFrameToColorSpace(myDepthMetaData.FrameData, mycolorPointsInDepthSpace);
After that, the point cloud is created by taking the depth frame and getting color data for each pixel in the method:
8. MetaDataBasePointCloudVerticesWithColorParallel()
th
Here I use parallelisation, otherwise the performance is very low, and an update of the UI is done about once per second or slower. By using parallisation, the performance is up to 10 frames/s.
The code used is:
private static PointCloud PointCloudWithColorParallel(ColorSpacePoint[] mycolorPointsInDepthSpace, CameraSpacePoint[] myRealWorldPoints, ColorMetaData myColorMetaData, DepthMetaData myDepthMetaData, BodyMetaData myBodyMetaData)
{
Vector3[,] arrV= new Vector3[DepthMetaData.XDepthMaxKinect, DepthMetaData.YDepthMaxKinect];
Vector3[,] arrC = new Vector3[DepthMetaData.XDepthMaxKinect, DepthMetaData.YDepthMaxKinect];
try
{
System.Threading.Tasks.Parallel.For(0, DepthMetaData.XDepthMaxKinect, x =>
{
for (int y = 0; y < DepthMetaData.YDepthMaxKinect; y++)
{
int depthIndex = (y * DepthMetaData.XDepthMaxKinect) + x;
if (myDepthMetaData.FrameData[depthIndex] != 0)
{
if (PointCloudScannerSettings.BackgroundRemoved && myBodyMetaData != null)
{
byte player = myBodyMetaData.Pixels[depthIndex];
if (player != 0xff)
{
SetPoint(depthIndex, x, y, arrV, arrC, mycolorPointsInDepthSpace, myRealWorldPoints, myColorMetaData);
}
}
else
SetPoint(depthIndex, x, y, arrV, arrC, mycolorPointsInDepthSpace, myRealWorldPoints, myColorMetaData);
}
}
});
However, the mapping of color, method; MapDepthFrameToColorSpace behaves strange.
-The doc says, you should get a list of "colorpoints" of size of the depth frame (i.e. 512* 424 = 210788 points) which contain the color info. The colorpoints contain x and y coordinates, which should map to the color image (i.e. from coordinate 0,0 to 1920, 1080).
If you inspect the result while debugging, most of the points contain negative coordinates or infinity values.
OK, you ignore them (see also the code snippet above, where you check the x and y coordinates to be in the bounds
-still, the result contains artefacts at the edges of objects, E.g. if you scan a human face, you will see curious artefacts at the edges
I read all MS docs, and scanned the internet for known samples.
As also the Kinect Studio from Microsoft does not show the point clouds coloured, I assume this is a known problem.
Usage of the Unit Tests
I have spent a lot of effort to put the whole functionality of the code in unit tests. Work is in progress for some functionality – mainly the triangulation. Hopefully some of you will contribute to fill the gaps! Just send some code, and I will incorporate it.
To see the samples, you would have to first install NUnit and then configure the path of the NUnit exe in the Visual Studio project, in order to run the tests.
Hint: I did not manage to use NUnit 2.6 which uses .NET 2.0, but compiled NUnit using .NET 4.5. Possible that NUnit 3.0 (alpha version) works as well – I did not try that.
e.g. to open a Point cloud
[TestFixture]
[Category("UnitTest")]
public class Example3DModelsFromDisk : TestBase
{
[Test]
public void Bunny_obj_Triangulated()
{
string fileNameLong = pathUnitTests + "\\Bunny.obj";
TestForm fOTK = new TestForm();
fOTK.OpenGL_UControl.LoadModelFromFile(fileNameLong);
fOTK.ShowDialog();
}
Class Diagram of the Kinect project
This is a very rudimentary class diagram, created within Visual Studio just as an overview. But the code hierarchy is so simple that sophisticated class diagrams are not required :)

What is shown when starting the program KinectPointCloud is the form "MainWindow", which contains a user control: ScannerUC. This user control encapsulates all Kinect code. Here you have methods for start/stop grabbing, building the entropy image, statistic display, opening the grabbed point cloud in the OpenTK dialog etc.
There are two business objects for scanning, one for the Kinect, the other for Intel Real Sense camera.
The code for Intel realsense is not yet ready, since I do not use the Intel driver, but try to attach multiple RealSense cameras. This works, but I do not have the color info for the point cloud, as I need a mapper between color and frame data - and for the mapper I need the exact calibration data between color and depth sensor.
Some important members of the Kinect user control are the classes for handling the data grabbed by the Kinect. As the name suggest, you see the DepthMetaData for handling depth, resp. the ones for color and body meta data. Within theses classes you find numerous methods (mostly static) for data handling, like conversion, I/O.
Class Diagram of the OpenTK.Extension project
Again, the same rudimentary class diagram
What is displayed is the OpenGL user control, which contains a more basic control, without any combo boxes, etc
This OpenGL Control contains all methods for the 3D handling within OpenGL resp. the OpenTK port of OpenGL.
The member doing all 3D work is OpenGLContext, which contains 1..n 3D objects of type RenderableObject. They contain the PointCloud objects.
Image and Feature gallery
1. The 3D Bunny from the Stanford university, in various views:
The images show (from left to right): Point cloud, wireframe, solid, convex hull wireframe, convex hull solid.
You can get the first three views by loading the bunny file (included in the bin/TestModels directory), and then changing the View mode. The convex hull you can get by using the NUnit testcases
ConvexHullTest.Bunny_Hull
2. A sphere in the different vews
Other code used
I took various codes from others, here is the list. You can see the list also in the Help-About window.
Note: This list was created for the version 0.9.0.9, for the current version additional source code is used like:
-KDTree by Matthew B. Kennel, Article: https://arxiv.org/abs/physics/0408067. C++, Fortran code : https://github.com/jmhodges/kdtree2
-KDTree in C# by Jeremy C., https://github.com/Jerdak/KDTree2
-json library from: http://www.newtonsoft.com/json
Points of Interest
The triangulation should be improved, the whole part is work in progress.
The alignment of point clouds was the original reason this article was published. However, it seems that the point clouds scanned by the Kinect are not suitable for alignment - the quality of the points is not good enough, and for scanning a face, due to the minimum distance of 0,5 m, the number of points is too low.
See also
Point cloud viewer article
Point cloud alignment article
Most current code on github:
History
Version 0.9.0.11 on 4/18/2017 - fixed UI and Kinect scan issues
Version 0.9.0.10 on 4/03/2017
Version 0.9.0.9 on 8/14/2016

