Intel® Developer Zone offers tools and how-to information for cross-platform app development, platform and technology information, code samples, and peer expertise to help developers innovate and succeed. Join our communities for Android, Internet of Things, Intel® RealSense™ Technology, and Windows to download tools, access dev kits, share ideas with like-minded developers, and participate in hackathon’s, contests, roadshows, and local events.
Introduction
This sample demonstrates the use of the extension GL_INTEL_fragment_shader_ordering, which is written against the OpenGL* 4.4 core profile and GLES 3.1 specifications. The minimum OpenGL version required is 4.2 or ARB_shader_image_load_store. The extension introduces a new GLSL built-in function, beginFragmentShaderOrderingINTEL(), which blocks execution of a fragment shader invocation until invocations from previous primitives that map to the same xy window coordinates have completed. The sample makes use of this behavior to provide a real-time solution for providing order-independent transparency (OIT) in a typical 3D scene.
Order-Independent Transparency
Transparency is a fundamental challenge in real-time rendering due to the difficulty of compositing an arbitrary number of transparent layers in the right order. This sample builds on the work originally detailed in the articles on adaptive-transparency and multi-layer-alpha-blending by Marco Salvi, Jefferson Montgomery, Karthik Vaidyanathan, and Aaron Lefohn. These articles show how transparency can closely approximate the ground-truth results obtained from A-buffer compositing, but can be between 5x and 40x faster by using various lossy compression techniques to compress the transparency data. This sample demonstrates an algorithm based on these compression algorithms, suitable for inclusion in a real-time application such as a game.
The Transparency Challenge
The sample rendering the test scene using normal alpha transparency blending is shown in Figure 1:
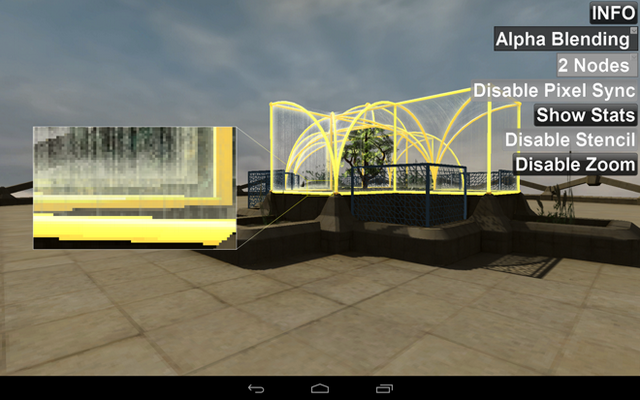
Figure 1: OIT Sample
The geometry is rendered in a fixed order: ground followed by the objects inside the dome, then the dome, and finally the outside plants. Solid objects are drawn first and update the depth buffer, and then transparent objects are drawn in the same order without updating the depth buffer. The zoomed-in area highlights one of the visual artifacts resulting from this: the foliage is inside the dome but in front of several planes of glass. Unfortunately, the rendering order means that all of the glass planes, even the ones behind the foliage, are drawn on top. Having the transparent object update the depth buffer creates a different set of problems. Traditionally this could only be solved by breaking the objects into smaller pieces and sorting them front to back based on the camera view point. Even then, it's not perfect as objects can intersect, and the cost of rendering increases as more objects are sorted and drawn.
Figure 2 and Figure 3 show the visual artifact zoomed in, with all the glass planes drawn before the foliage in Figure 2 and correctly sorted in Figure 3.

Figure 2: Unsorted
Figure 3: Sorted
Real-time Order-Independent Transparency
There have been several attempts to solve the compositing of arbitrarily ordered geometric primitives without the need to sort on the CPU or to break the geometry down into non-intersecting elements. These include depth-peeling, which requires the geometry to be submitted multiple times and A-buffer techniques, where all fragments that contribute to a given pixel are stored in a linked list, sorted, and then blended in the correct order. Despite the A-buffer's success in offline renderers it has not been adopted by the real-time rendering community due to its unbounded memory requirements and generally low performance.
A New Approach
Rather than the A-buffer approach of storing all color and depth data in per-pixel lists and then sorting and compositing them, this sample uses the work of Marco Salvi and re-factors the alpha-blending equation to avoid recursion and sorting and produces a "visibility function" (Figure 4):
Figure 4: Visibility Function
The number of steps in the visibility function corresponds to the number of nodes used to store visibility information on a per-pixel level during the render stage. As pixels are added they are stored in the node structure until it is full. Then on attempted insertion of more pixels, the algorithm calculates which previous nodes can be merged to create the smallest variation in the visibility function while maintaining the data set size. The final stage is to evaluate the visibility function vis() and composite fragments using the formula final_color=.
The sample renders the scene in the following stages:
- Clear the Shader Storage Buffer Object to default values on the first pass.
- Render all solid geometry to the main frame buffer Object, updating the depth buffer.
- Render all transparent geometry while reading the depth buffer without updating; the final fragment data is discarded from the frame buffer. The Fragment data is stored in a set of nodes inside a Shader Storage Buffer Object.
- Resolve the data inside the Shader Storage Buffer Object and blend the final result to the main Frame Buffer Object.
|
Figure 5: Render Path
Given that the cost of reading the Shader Storage Buffer Objectin the resolve stage can be very high due to the bandwidth required, an optimization that this sample uses is to use the stencil buffer to mask the areas where transparent pixels would be blended into the frame buffer. This changes the rendering to that shown in Figure 6.
- Clear the Stencil buffer.
- Clear the Shader Storage Buffer Object to default values on the first pass.
- Set the following Stencil Operation:
glDisable(GL_STENCIL_TEST);
- Render all solid geometry to the main frame buffer object, updating the depth.
- Set the following Stencil Operations:
glEnable(GL_STENCIL_TEST);glStencilOp(GL_KEEP, GL_KEEP, GL_REPLACE);glStencilFunc(GL_ALWAYS, 1, 0xFF);
- Render all transparent geometry while reading the depth buffer without updating; the final fragment data is blended to the main frame buffer with an alpha of 0. The stencil buffer is marked for each fragment drawn to the frame buffer. The fragment data is stored in a set of nodes inside a Shader Storage Buffer Object. Discarding the fragment isn't possible as this prevents the stencil being updated.
- Set the following Stencil Operations:
glStencilOp(GL_KEEP, GL_KEEP, GL_REPLACE);glStencilFunc(GL_EQUAL, 1, 0xFF);
- Resolve the data inside the Shader Storage Buffer Object for just the fragments that pass the stencil test and blend the final result to the main Frame Buffer Object.
- Set the following Stencil Operations:
glStencilFunc(GL_ALWAYS, 1, 0xFF);glDisable(GL_STENCIL_TEST);
|
Figure 6: Stencil Render Path
The gain from using the stencil buffer can be seen in the new cost of the resolve phase, which drops by 80%, although this is very dependent on the percentage of the screen that is covered by transparent geometry. The greater the percentage of the screen covered by transparent objects the smaller the performance win.
void PSOIT_InsertFragment_NoSync( float surfaceDepth, vec4 surfaceColor )
{
ATSPNode nodeArray[AOIT_NODE_COUNT];
PSOIT_LoadDataUAV(nodeArray);
PSOIT_InsertFragment(surfaceDepth,
1.0f - surfaceColor.w, surfaceColor.xyz,
nodeArray);
PSOIT_StoreDataUAV(nodeArray);
}
Figure 7: GLSL Shader Storage Buffer Code
The algorithm above can be implemented on any device that supports Shader Storage Buffer Objects, but there is one very important flaw as currently described: it's possible to have multiple fragments in flight that map to the same window xy coordinates.
If multiple fragments run on the same xy coordinates at the same time, they will all read the same starting data in PSOIT_LoadDataUAV but will end up with different values that they try and store in PSOIT_StoreDataUAV with the last to complete overwriting the others that were processed. The effect of this is the compression routine can vary between frames, and this can be seen in the sample by disabling Pixel Sync. The user should see a subtle shimmer on areas where there are overlapping transparencies. The zoom feature was implemented to make this easier to see. The more fragments the GPU can execute in parallel, the greater the likelihood that the shimmer is visible.
By default, the sample avoids this problem by using the new GLSL built-in function, beginFragmentShaderOrderingINTEL(), which can be used when the extension string GL_INTEL_fragment_shader_ordering is shown for the hardware. The beginFragmentShaderOrderingINTEL() function blocks fragment shader execution until completion of all shader invocations from previous primitives that map to the same window xy coordinates. All memory transactions from previous fragment shader invocations mapped to the same xy window coordinates are made visible to the current fragment shader invocation when this function returns. This allows the merging of the previous fragments to create the visibility function in a deterministic manner. The beginFragmentShaderOrderingINTEL function has no effect on shader execution for fragments with non-overlapping window xy coordinates.
An example of how to call beginFragmentShaderOrderingINTEL is shown in Figure 8.
GLSL code example
-----------------
layout(binding = 0, rgba8) uniform image2D image;
vec4 main()
{
... compute output color
if (color.w > 0) {
beginFragmentShaderOrderingINTEL();
... read/modify/write image }
... no ordering guarantees (as varying branch might not be taken)
beginFragmentShaderOrderingINTEL();
... update image again }
Figure 8: beginFragmentShaderOrderingINTEL
Note there is no explicit built-in function to signal the end of the region that should be ordered. Instead, the region that will be ordered logically extends to the end of fragment shader execution.
In the case of the OIT sample, it's simply added as shown in Figure 9:
void PSOIT_InsertFragment( float surfaceDepth, vec4 surfaceColor )
{
#ifdef do_fso
beginFragmentShaderOrderingINTEL();
#endif
PSOIT_InsertFragment_NoSync( surfaceDepth, surfaceColor );
}
Figure 9: Adding Fragment ordering to Shader Storage Buffer access
This is called from any fragment shader that potentially writes transparent fragments as shown in Figure 10.
out vec4 fragColor;void main( )
{
vec4 result = vec4(0,0,0,1);
float alpha = ALPHA().x;
result.a = alpha;
vec3 normal = normalize(outNormal);
vec3 eyeDirection = normalize(outWorldPosition - EyePosition.xyz);
vec3 Reflection = reflect( eyeDirection, normal );
float shadowAmount = 1.0;
vec3 ambient = AmbientColor.rgb * AMBIENT().rgb;
result.xyz += ambient;
vec3 lightDirection = -LightDirection.xyz;
float nDotL = max( 0.0 ,dot( normal.xyz, lightDirection.xyz ) );
vec3 diffuse = LightColor.rgb * nDotL * shadowAmount * DIFFUSE().rgb;
result.xyz += diffuse;
float rDotL = max(0.0,dot( Reflection.xyz, lightDirection.xyz ));
vec3 specular = pow(rDotL, 8.0 ) * SPECULAR().rgb * LightColor.rgb;
result.xyz += specular;
fragColor = result;
#ifdef dopoit
if(fragColor.a > 0.01)
{
PSOIT_InsertFragment( outPositionView.z, fragColor );
fragColor = vec4(1.0,1.0,0.0,0.0);
}
#endif
}
Figure 10: Typical material Fragment Shader
Only fragments that have an alpha value above a threshold are added to the Shader Storage Buffer Object, effectively culling any fragments that wouldn't end up contributing any meaningful data to the scene.
Building the Sample
Build Requirements
Install the latest Android SDK and NDK:
Add the NDK and SDK to your path:
export PATH=$ANDROID_NDK/:$ANDROID_SDK/tools/:$PATH
To Build:
- cd to OIT_2014\OIT_Android folder
- First time only, you may need to initialize your project:
android update project –path . --target android-19. - Build the NDK component:
NDK-BUILD - Build the APK:
ant debug - Install the APK:
adb install -r bin\NativeActivity-debug.apk or ant installd - Run it
Conclusion
The sample demonstrates how the research into adaptive order-independent transparency by Marco Salvi, Jefferson Montgomery, Karthik Vaidyanathan, and Aaron Lefohn originally done on high end discrete video cards using DirectX 11* can be implemented in real time on an Android tablet using GLES 3.1 and fragment shader ordering. The algorithm runs inside a fixed memory footprint that can be varied based on the required visual fidelity. Optimizations such as the stencil buffer allow the technique to be implemented on a wide range of hardware at acceptable performance providing a practical solution for one of the most challenging problems in real-time rendering. The principles shown in the order-independent transparency sample can be applied to a variety of other algorithms that would normally create per-pixel linked lists including volumetric shadowing techniques and post processing anti-aliasing.
Related Articles and References
https://www.opengl.org/registry/specs/INTEL/fragment_shader_ordering.txt
https://software.intel.com/en-us/articles/adaptive-transparency
https://software.intel.com/en-us/articles/multi-layer-alpha-blending

