In my previous post, I wrote about unit testing and refactoring as tools for managing changes. Change management in that context is a form of dealing with risks. This time, I'd like to discuss risk management a bit more generically.
In development - and almost all areas of life - we often face problems where we have choices. Making a decision can be more difficult when there are many unknown factors. To such uncertainty, we feel inclined to react by making decisions to clear things up, it is a natural thing to do. It is controversial though, making decisions when we are uncertain can easily lead to bad decisions. However, there is an important question to ask: is there a strong need to make that decision right away? If the answer to that question is no, there is an additional, often overlooked alternative: postponing the decision.
Risk is defined in ISO 31000 as the "effect of uncertainty on objectives". In the context of software development, the risk can be interpreted as investment or commitment to a choice with many unknowns. The more we invest in a bad choice the more we lose, the goal is to minimize that. Not making a decision on the other hand doesn't require any commitment, therefore there is no risk. If it doesn't block development immediately, postponing can be an viable alternative: it gives an opportunity to gain knowledge on the problem as we proceed with other tasks and have the potential to make a better decision when the time comes.
How is this Applicable in Practice?
Not the "Ah, let's just do it tomorrow!" kind of way, the job needs to be done, there are usually deadlines to meet. When we feel we're doing too much guess-work, we can stop for a moment to think. In some cases, postponing can be obvious. In other cases, it is not trivial but can be supported by careful design (hiding the effects of a decision behind an abstraction for instance).
This sounds a bit vague, so here is a practical example. It involves using a method which I think is a great asset in software design. We have a component like this, our plan is to extend it with new features in the future:
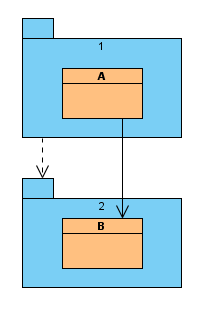
At this point, it is unclear how to get on with some of the new features but we don't make decisions yet. We summarize all our options, possible scenarios, estimate what changes they require and where, then mark them on the diagram:
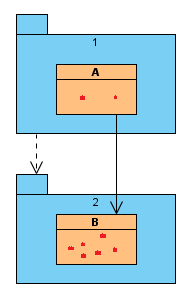
We can see that class B in component 2 doesn't look very stable. Class A in component 1 depends on it. This is a bad sign, a change in class B will affect class A too and class B is likely to change often. We can address this in many ways, in this concrete case we decide to perform Dependency Inversion:
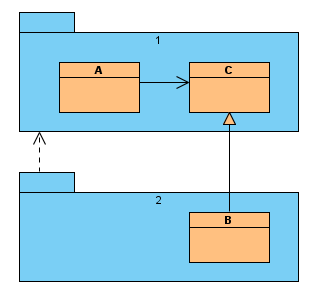
After this transformation component 2 depends on component 1. Changes in component 2 will not have as much impact on component 1. We haven't added any features yet, but our system is probably better suited for the upcoming development.
This change counting method can be used retrospectively too. A change log extracted from version control systems holds very similar information. Finding out why there are so many changes in a component can provide useful hints for pinpointing design flaws.

