Introduction
This article is to target the beginners who usually get puzzled by the big term, "Unicode" and also those users who ask questions like, "How to store [non-english or non-ASCII] language in database and get it back too". I remember, back a few months ago I was into same situation, where most of the questions where based on the same thing... "How to get the data from database in [non-ASCII language] and print it in application". Well, this article is meant to target all these questions, users, and beginner programmers.
This article will most specifically let you understand what Unicode is, why is it used now a days (and since the day it was created), it will explain a few points about its types (such as what is UTF-8, what is UTF-16 and what is there difference, which one to use and why to use etc), then I will move on to using these characters in different .NET applications. Note that I will also be using ASP.NET web application, to demonstrate the scenario is a web-based environment too. .NET framework supports all of these encoding and the code pages to allow you to share your data among different products that understand Unicode standards. There are multiple classes provided in .NET to let you kick-start your application based on Unicode characters to support global languages.
Finally, I will be using a database example (I will be using MS SQL Server) to show, how to write and extract the data from the database; it is pretty much simple, no big deal atleast for me. Once that has been done, you can download and execute the commands on your machine to test the Unicode characters yourself... Let us begin now.
I will not talk about Unicode itself, instead I will be talking about the .NET implementation of Unicode. Also note that the number value of the characters in this article are in numeric (and decimal) form, not in U+XXXX and hexadecimal form. I will, at the end, also show how to convert this decimal value into hexadecimal value.
Starting with Unicode
What is Unicode anyway?
Unicode is a standard for character encoding. You can think of it like a standard for converting every character to its mathematical notation and every mathematical notation to its character representation; computer can only store binary data that is why non-binary data (number) is converted into binary representation to be stored on the machine. That is, each character has a separate numeric assigned to it that is used to identity which character is to be presented. The number is stored in the memory, computers works with the byte storage and other things, Unicode is not used to store the bytes in the memory, Unicode simply provides a number for each character.
Back in old days, there were not many different schemes for developers and programmers to use to represent their data in different languages; although that was because application globalization was not general back then. Only English language was used, and the initial code pages included the codes to represent and process the encoding and decoding of English letters (small and capital) and some special characters. ASCII is one of them. Back in ASCII days, it encoded 128 characters of English language to a 7-bit data, then used the last bit to represent a few special characters. ASCII doesn't only include encoding for text, but also for the directives for how text should be rendered etc; many are not used now a days. That was most widely used standard, because it fulfilled their need at that time.
As computers became widely used machines, and many developers wanted their applications to be used in a client-locale-friendly version, there originated a requirement for a new standard, because otherwise every developer could create his own code page to represent different characters, but that would have removed the unity among the machines. Unicode, had originated back in late 1980s (See history section in Wikipedia), but was not used because of its large size; 2-bytes for every character. It had capability to represent more characters as compared to ASCII coding structure. Unicode supports 65,536 characters which supports all of the worldy characters now a days. That is why, Unicode is used widely, to support all of the characters globally and to make sure that the characters sent from one machine would be mapped back to a correct string and no data would be lost (by data losing I mean by sentences not being corrected rendered back).
Putting it simply, Unicode is the standard used to map different characters to their numeric representation. Unicode allows developers to use numeric data and map them to glyphs or the fonts that can be used to represent the characters on screen. A character can be mapped to a number, Unicode would take care of the byte-wise representation in the machine, however some other encodings and mapping mechanisms are used to implement Unicode in applications and frameworks. Most of the frameworks (including and most especially, .NET framework and Java) support Unicode standard.
Encoding and mapping
Unicode is the actual standard defined by Unicode Consortium. Now it is the need to implement the Unicode standard to be consumed. There are two methods that Unicode exposes to implement the encoding of characters into bytes and to map them to numeric representation. Unicode has specified the following mappings and encodings that are used,
- UTF-8
- UTF-16
- UTF-32
There are some other obsolete and retired encoding types in Unicode,
- UTF-1
Predecessor of UTF-8 - UTF-7
Used in e-mails and is no longer a part of Unicode standard. - UTF-EBCDIC
Developed for compatibility with EBCDIC, but no longer a part of Unicode standard.
Next section discusses these encoding and mapping types.
A little in-depths about Unicode encoding?
Beginners do stumble upon UTF-8, UTF-16 and UTF-32 and then finally on Unicode and they think of them being different things... Well, no they're not. Actual thing is just Unicode; a standard. UTF-8 and UTF-16 is the name given to encoding scheme used by different sizes... UTF-8 is of 1 byte (but remember, this one can span to 2 byte , 3 byte or 4 byte too if required, and in the end of this article I will tell which one of these schemes you should use and why, so please read the article to the end) and so on.
UTF-8
UTF-8 is the variable-length Unicode encoding type, by default has 8 bits (1byte) but can span, and this character encoding scheme can hold all of the characters (because it can span for multiple bytes). It was designed so, to be a type that supports backward compatibility with ASCII; for machines that don't support Unicode at all. This standard can be used to represent the ASCII codes in first 128 characters, then in the up-coming 1920 characters, it represents mostly used global languages, such as Latin, Arabic, Greek etc and then all remaining characters and code points can be used to represent the rest of characters... (References from the Wikipedia article of UTF-8)
UTF-16
UTF-16 is also variable-length Unicode character encoding type, the only difference is that the variable is a multiple of 2bytes (2bytes or 4bytes depending on the character; or more specifically the character-set). It was initially fixed 2byte character encoding, but then it was made variable-sized because 2bytes are not enough.
Surrogate-pairs
In UTF-16 encoding scheme, a surrogate-pair is a pair of 16-bit (UTF-16) Unicode encoded characters, that are used to represent one single character. It must be noted that a surrogate-pair is of size 32-bit and not 16. Surrogate-pairs are both used to represent a single character and a single value of the pair cannot be mapped to a single character in Unicode.
By using surrogate-pairs, UTF-16 encoding gets a chance to support a million more characters. Remember, all of these character representation (their number-code) is already defined by Unicode, UTF-16 just represents them.
Technically, first value of a surrogate-pair is known as the high-surrogate and has a range from 0xD800 to 0xDBFF and the later value of surrogate-pair is known as low-surrogate pair, having a range from 0xDC00 to 0xDFFF.
Most common use of surrogate-pairs is when referring to non-BMP (Basic Multilingual Plane) characters. Thus, two values of BMP characters are used to map to a non-BMP character, and the values do come from the BMP range but map to a non-BMP character.
In .NET framework you can use the following functions to determine whether character is a low-surrogate or high-surrogate,
System.Char.IsLowSurrogate(char);
System.Char.IsHighSurrogate(char);
.NET framework's char object supports checking up for surrogation (in surrogate pairs) and many other functions that are related to Unicode data.
UTF-32
UTF-32 uses exact 32bits (or 4 bytes) per character. Regardless of code points, or character set or language, this encoding would always use 4 bytes for each of the character. The only good thing about UTF-32 (as per Wikipedia) is that the characters are directly indexible, which is not possible in variable-length UTF encodings. Whereas, I believe the biggest disadvantage of this encoding is the 4 bytes size per character, even if you're going to use Latin characters; or ASCII characters specifically.
Unicode
When you try to use the default encoding provided by Unicode, you are referring to UTF-16LE (16-bit character encoding using Little-Ending byte-representation; or byte order). Thus, apart from being just a name for the standard, Unicode is also an encoding type that refers to UTF-16LE (read about it in .NET framework).
Also, remember that this term is coined by Microsoft in their .NET framework's Encoding class members. This is not the standard, but indeed the encoding type; UTFs. That is why it is mapped to UTF-16LE. Read more about UTF-16LE below.
Endianness
Endianness is the ordering of bytes of a word in digital computing. There are two types of endianness,
- Big-Endian
A machine that uses Big-Endian stores the most-significant bit first in the memory. - Little-Endian
A machine that uses Little-Endina stores the least-significant bit first in the memory.
It depends on the machine, how it stores the bytes in the memory. If your data is going to be of one-byte, then do not bother about endianness because that is the only data you read for each character. You can also understand what Endian is being used by looking at the first byte and comparing it with other; Big-Endian would store the big-byte first and then the byte that is smaller than it and so on.
UTF-16BE
UTF-16BE is the encoding that maps the characters to their representation in bytes, but the byte representation is identical to Big-Endian; (BE stands for Big-Endian), thus a machine that uses Big-Endian can make use of UTF-16BE.
UTF-16LE
Similarly, UTF-16LE is the encoding that encodes the characters to their byte representation that is identical to Little-Endian byte-representation of the words; that is the least-signifact byte comes first and then the larger and larger and so on. In UTF-16LE, LE stands for Little-Endian.
LE and BE are total opposite as former one uses least-significant byte in the first order and the later one uses most-significant byte in the first order to arrange the bytes in the block. Thus if one uses a byte-order, he must know which Endian is he using to store the bytes in the memory. When these blocks are to be extracted from memory, machine knows how to encode the bytes back to a character (map them to a character) by looking at the first byte; Least or most significant byte.
Coming to .NET framework now
Enough of little backgroun of Unicode standard... Now I will be continuing to give the overview of .NET framework and the support of Unicode in .NET framework. The support for Unicode in .NET framework is since the basics and primitive types, char. A char in .NET framework is of 2-bytes and supports Unicode encoding schemes for characters. You can generally specify to use which-so-ever Unicode encoding for your characters and strings, but by default you can think of the support for being UTF-16 (2 bytes).
char (C# Reference) .NET documentation
Char Structure (System)
The above documents contain different content, but are similar... char is used to declare an instance of System.Char object in .NET framework. By default .NET framework supports Unicode characters too, and would render them on screen and you don't even have to write any seperate code; ensuring the encoding of the data source only. All of the applications in .NET framework, such as WPF, WCF and the ASP.NET applications support Unicode. You can use all of the Unicode characters in all of these applications, and .NET would render the codes into their character notation. Do read the coming section.
Wait, you didn't mention Console applications, why?
This is a good point to be noted here, because I mentioned every .NET application supports Unicode but I didn't mention Console applications. Well, the problem isn't generally the Unicode support, it is neither the platform or the Console framework itself. It is because Console applications were never built to support this much graphics; yes, supporting different characters is graphics and you should read about glyphs.
When I started to work around in a console application to test Unicode support in Console application, I was amazed to see that Unicode character support doesn't only depend on the framework underlying, or the library being used, but instead there is another factor that you should consider before using unicode support. That is the font family of your console; there are multiple fonts in Console, if you open the properties of your console.
Let us, now try out a few basic examples of characters from range 0-127, then from next code page to next and see how console application behaves... and what other applications might respond to out data in a way.
ASCII codes
First I will try out ASCII code (well a very basic one, 'a') in the code to see if console behaves correctly or messes something up. I used the following code to be executed in the console application,
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace ConsoleUnicode
{
class Program
{
static void Main(string[] args)
{
char a = 'a';
Console.WriteLine(String.Format("{0} character has code: {1}", a,
((int)'a').ToString());
Console.Read();
}
}
}
The above code gets the integer representation of the 'a' character; this is a simple version of getting the value of the character, which in the previous version I used to get the value by encoding it to UTF-8 based byte array, which in most of the cases gave wrong value where as this one provides us with the accurate value. Again, you might want to know how does a get 61 value in UTF? That is because the representation in the form of U+0061 is the hexadecimal representation of the integeral (decimal) value, in this case which is 97. You can check converting 97 into hexadecimal yourself! For more on conversions, please read the section, "Converting the decimal to Unicode representation (U+XXXX)" where I have explained it in a little deeper way.
The response to this above code, was like this,
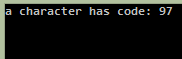
You can see that now there is no difference as if the code is from ASCII or Unicode, because a is 97 in both of them. That was pretty much basic. Now, let us take a step farther...
Non-ASCII codes
Let us now try Greek alphabets, the first one in the row, alpha.. If execute similar above code and replacing the a with alpha, you will see the following result,

Well these things are getting pretty much good.
Let us take a big step now, why not try hindi? Hindi is pretty much regularly asked about, for how to store and extract Hindi alphabets from database and so on. Let us now try Hindi characters in console application.
Nope -- I didn't order a question mark! That was meant to be a "k" sounding character in hindi.. which it isn't it is "q" sounding question mark. Why was it so?
That was not a problem in the unicode, but the console application's low support for globl fonts, to support my answer on this I created another line of code to store this code inside a txt file with Unicode support. Below is the code to store the binary of the characters (using UTF-8 encoding).
Note, notepad can support ASCII, Unicode and other schemes so make sure your file supprts the character set before saving the data.
File.WriteAllBytes("F:\\file.txt", Encoding.UTF8.GetBytes(a.ToString()));
The above code executed for the same character, on the console there was a question mark printed.. but the file presented something else.
This shows, that the characters are widely supported in .NET framework, but it is the font that also matters, the glyphs in the font are to be available to rendered the character, otherwise application would just show such characters (in other framework there is a square box denoting character not supported).
Conclusion
So according to this hypothesis, if there is any problem in your application while displaying the Unicode characters in console application, you need to make sure that the character you're trying to display is supported in the font family that you're using. The problem is similar to loading a Hindi character in console application which is not supported in font family. This would end the discussion for supporting the Unicode characters in console applications, until you update the font family to support that code page (or at least that code point).
Unicode support in other application frameworks
Now let us see how much unicodes are supported in other frameworks, such as WPF and ASP.NET. I am not going to use Windows Forms; process is similar to WPF. ASP.NET and WPF has a wide variety or fonts and glyphs that can support different charactes; almost all of the characters. So, let us continue from software frameworks to a web framework and then finally testing the SQL Server database for each of this framework, to test what would it be like to support Unicode characters...
Let me coin the data source first
Before I continue to any framework, I would like to introduce the data source that I am going to use in the article to show how you can read and write the data in unicode format from multiple data sources. In this article, I will use,
- Notepad; that supports multiple encodings, ASCII, Unicode etc.
- SQL Server database to store the data in rows and columns.
You can use either of these data sources (first one is available to you if you're using Windows-based OS) and they would support Unicode data writing and reading. If you're going to write the data and create the file from the code, then there is no need for anything.. Otherwise, if you're going to create a new file yourself and name it, then before saving make sure you've selected UTF-8 encoding (not the Unicode that is UTF-16) before hitting the save button to create the file otherwise it will be default ASCII encoding and Unicode data would be lost if saved on to it. You can use notepad as data source, or if you're having SQL Server then you can use SQL Server as your data source; they can both satisfy your needs.
Using SQL Server Database
You can use the SQL Server database in your project too, and if you're going to use the source code given here, you might require to create a sample database and inside this newly created database (or inside your current testing database you can) create a new table, to hold the Language and UnicodeData. You can also run the following SQL command to do this...
CREATE TABLE (
Langauge nvarchar(50),
UnicodeData nvarchar(500)
);
Make sure you're selecting the correct database to create the table inside, or use the USE DATABASE_NAME command before this command to execute. Initially, I filled the database with the following data.
Langauge | UnicodeData
Arabic | بِسْمِ اللهِ الرَّحْمٰنِ الرَّحِيْمِ
Hindi | यूनिकोड डेटा में हिंदी
Russian | рцы слово твердо
English | Love for all, hatred for none!
Urdu | یونیکوڈ ڈیٹا میں اردو
Quite enough data and languages to test our frameworks again. I am sure console would never support it, so why even try? Yet if you want to see the output in a console application, I won't deny...
WPF and Unicode
The only problem in console application was the less support of character glyphs in font family, that has just been overcome in WPF. In WPF you can use quite a bunch of fonts (system based fonts or your own custom generated fonts) that you can use to display different characters in your applications, in a way that you want them to be.
WPF supports all of the characters, we will see why I am talking about this. First of all, let us write a simple expression in plain text, starting to print the same characters now in WPF.. once I finish this, I will try to see if fonts are a factor in WPF or not.. stay tuned.
1. 'a' character
First of all, I will try printing the 'a' character on the screen, and see what the encoded code for it is; which would be similar to that of ASCII too. Following code can be interpreted,
text.Text = String.Format("character '{0}' has a code: {1}", "a", ((int)'a'));
Int32 can map to all of the characters in Unicode and can store their decimal value.
Now the above code, once executed, would print the following output.
Quite similar output to that of the console application. Moving forward now...
2. 'α' character
Now, moving to that greek character and trying it out would result in the following screen,
3. 'क' character
Now coming to the problematic character, the Hindi character to test in our application to see what is the affect of it in our application. When we change the code to print and fill it with क, we get,
This shows that WPF really does support the character, because the font family; Segoe UI, supports the unicode characters. Which at current instance is Hindi alphabet set.
Testing SQL Server data in WPF
We saw how console application treated the data, now it is time to test our WPF application to see how it treats our Unicode data coming from SQL Server, and see if it represents raw data on the screen, or do we need to do something with it. I am going to create an SqlClient and run some SqlCommands on SqlConnection of my database.
You will need a connectionString for your SQL Server database.
using (SqlConnection conn =
new SqlConnection("server=your_server;database=db_name;Trusted_Connection=true;"))
{
conn.Open();
SqlCommand command = new SqlCommand("SELECT * FROM UnicodeData", conn);
text.FontSize = 13;
text.Text = "Langauge\t | \tUnicodeData" + Environment.NewLine + Environment.NewLine;
using (SqlDataReader reader = command.ExecuteReader())
{
while (reader.Read())
{
text.Text += reader[0] + "\t \t | \t" + reader[1] + Environment.NewLine;
}
}
}
Now the WPF shows me the following output on screen...
Now the above image shows us, that there is no other effort required by us to do anything for the data to be rendered, WPF does that for us.
Adding and retrieving the data
Usually people say that they stored the data in correct format, but when they try to extract the data, they get the data in a wrong format. Mostly, Hindi, Arabic, Urdu and Japanese users are asking such questions, so I thought I should also try to give an overview of what happens when a user stores the data to the data source. I used the following code to insert 3 different rows to the database,
SqlCommand insert = new SqlCommand(@"INSERT INTO UnicodeData (Language, UnicodeData)
VALUES (@lang, @data)", conn);
var lang = "language in every case";
var udata = "a few characters in that particular language";
insert.Parameters.Add(new SqlParameter("@lang", lang));
insert.Parameters.Add(new SqlParameter("@data", udata));
if (insert.ExecuteNonQuery() > 0)
{
MessageBox.Show("Greek data was stored into database, now moving forward to load the data.");
}
The data I inserted was,
Greek | Ελληνικών χαρακτήρων σε Unicode δεδομένων
Chinese | 祝好运
Japanese | 幸運
So now the database table should look like this,
Does font matter in WPF too?
In the console application, the font-family also matters, the same question arises, "Does font family matters in WPF too?". The answer is, "Yes! It does matter". But the actual underlying process is different. WPF framework maps characters to their encodings, and encodings to their characters for every font-family. If cannot map a character to an encoding then it uses a fallback to default font family which supports that character.
If you read the FontFamily class documentation on MSDN, you will find a quite interesting section named as, "Font Fallback", which states...
Quote:
Font fallback refers to the automatic substitution of a font other than the font that is selected by the client application. There are two primary reasons why font fallback is invoked:
Now wait, it doesn't end there. It doesn't mean, WPF would use a custom font instead of that font or would create a box or question mark. What actually happens is wonderfull (in my opinion), WPF uses default font fallback font family, and thus provides a default, non-custom font for that encoding. You should read that documentation to understand the fonts in WPF. Anyhow, let us change our font in WPF application and see what happens.
Adding this following code would change the font family of my TextBlock,
text.FontFamily = new FontFamily("Consolas");
The output on screen now is something like this.
What we see is quite similar to the previous output. That is because, only those characters which were mapped to Consolas font family were rendered as Consolas font, else (Urdu, Arabic, Hindi etc) were mapped back to Segoe UI font using the font fallback mechanism enabling our application to view the data without having our to user to see question marks and sqaure boxes. This feature of WPF, is one of the features that I love. Everything happens in the background.
ASP.NET support for Unicode
Now let us see, if ASP.NET also supports Unicode data, or do we need to do some work on it to display the characters of Unicode encoding. As far as it has been, I have always been saying that "ASP.NET runs right over .NET framework, so anything that runs on .NET framework can be used on the back-end of ASP.NET if cannot be used on front-end". Now it is time for Unicode support to be tested.
Testing SQL Server data in ASP.NET
I am going to skip the three characters that I have had shown in WPF example, because everyone knows that these characters if can be written in HTML can be parsed in ASP.NET. So, I am going towards the data coming from SQL Server now.
I will use the same code from WPF application and test it in my ASP.NET website, once rendered, it shows the following output.
I know the format of the paragraphs is a bit messy, but I didn't want to work out the HTML rendering and CSS of the web document, so I left it out to your intellect to see that everything is working. The output in this case is also similar to that of WPF output and shows that the characters are correctly rendered; font-family of this web page is also Segoe UI.
Does font matters in ASP.NET?
The answer here is also similar, the font does matter... But there are some other factors that would come in action here.
- ASP.NET from the server-side would send the response in correctly and properly formatted HTML form; with all of the Unicode characters embedded in the document.
- The web browser would play a major role in supporting the character-set. You have to rely on the browser to support the characters that were sent, unlike WPF there is no font fallback that can show a default font to the client; most new browsers would have a custom mechanism for their own softwares and would act just like font fallback.
(Now it does make sense for using <meta charset="utf-8" />, doesn't it?) - The OS being used, OS should also support the Unicode, you cannot expect everyone to be running a latest version of everything and the best machine with most rated OS.
Checking these conditions, you can assume that ASP.NET, on server-side would try to do everything that it can, to make sure that the data is not lost (by data lost, I mean the data being represented in square box form or some diamond box with question mark in it and so on). So, in ASP.NET the font doesn't only matter, the web browser, and the character-set also matters... Making it somewhat different for developer to assume what would happen. WPF has .NET framework's versions running in the background to perform a fallback, ASP.NET doesn't get such a chance, because a user using Windows 95 (which rarely would be) can make a web request to your ASP.NET 5 based website.
Changing the font to Consolas in ASP.NET and testing in my Windows 8.1 based Google Chrome web browser, I don't find any difference...
But if you notice, the fonts are not fallen back, but there is a slight difference in them, (See the Arabic, Russian for a slight change) and it shows that there is a custom support for them in the web browser itself, to render the characters on itself.
Bonus data and examples...
Guidance for users using Notepad
If you're going to use Notepad, you would have to use System.IO namespace, and inside the File class you can use the read all bytes to make sure that you're using the correct encoding scheme. For example the following code, can be used to read all of the bytes from the file.
byte[] bytes = File.ReadAllBytes("location");
Then to write these bytes on the screen, you can use the Encoding class of System.Text namespace, to convert them to String using an encoding. See below,
string data = Encoding.UTF8.GetString(bytes);
Now the data would contain Unicode characters. You can then represent them on screen by outputting them using methods used in your own framework. You can also encode the data back and store in the file, you can convert the string to byte array and store all bytes to the file... Look below,
string data = GetData();
byte[] bytes = Encoding.UTF8.GetBytes(data);
File.WriteAllBytes("location", bytes);
Now the file (if supports Unicode encoding) would display the Unicode characters stored in it. The process is almost similar to using SQL Server, just the classes and method is different. You cannot say, that either one better than the other one. Both are free, and don't take much of a time.
Converting the decimal to Unicode representation (U+XXXX)
Mostly, people think that both data A and U+0041 represent different characters; I did... Maybe because 65 and 41 are for different characters in decimal base. Well, you're wrong and so was I. They represent the same character, 'A'. You should read this Wikipedia article, before moving on. It covers all of the basic characters and special characters.
Now, the basic idea behind them is that the 65 number for character is decimal-based number. Whereas the 41 is a hexadecimal-based data, and represents the same character; makes sense? They are just different notations in different bases for the same number. You can convert one to other and other to your own just as you would convert one number to another base. In .NET framework the code to get the numeric representation of a character and to get the character based on a number is,
char a = 'A';
int b = (int)a;
int a = 65;
char b = (char)a;
Using this mechanism, you can easily get the integeral value from character, and a character from an integer value. Now, once you've gotten decimal representation, you can use it to convert it into Unicode representation of that character. Have a look at the following code,
string str = String.Format("Character '{0}' has code: {1} and Unicode value: U+{2}",
'A', ((int)'A'), ((int)'A').ToString("X4"));
What happens when the above code executes?
The above image is worth a thousand words, isn't it? It clears a lot of ambiguity how these numbers are represented and what the actual value is and so on and so forth. You can denote the numbers in either way, depending on the way you like it.
Do not use byte to assume you got the value of character
File.ReadAllBytes makes sense as to hold the value of the data in byte array, but never try to believe that a single character value would be held in a single byte. A byte can hold data from 0-255, any data exceeding 255 would be then mapped as in a way to denote the character; thus a byte array. If you would try to get the value of that byte, you will get wrong value although the result of the render would be correct. For example, have a look at the following line of code.
That is absolutely wrong value, the correct value of alpha ('α') is, 945.
The values in the byte array are mapped in order to maintain the correct character scheme and not to hold the values of each character at their own indices. If you try to get the first value; in the array, you will get the wrong value and will assume you got it right!
Why prefer UTF-8 instead of other encodings?
I mentioned why prefer UTF-8 instead of other encoding schemes. Let me tell, why. The major factor is the light-weight of UTF-8 encoding. It is an 8-bit variable-length encoding scheme provided by Unicode consortium. It uses 1 byte for characters ranging from 0 - 255, then a 2 byte data for next code page and so on. Whereas, UTF-32 is fixed size but UTF-16 uses minimum of 2 bytes for each character.
UTF-8, if being used for an English-based website, maps to ASCII codes, thus providing a support to older machines supporting only ASCII encoding schemes. If you go to this MSDN documentation and read the example in the Examples section, you will find out UTF-8 being the best version to be used among all of the Unicode standards. There are quite other threads too, talking about the different... I might take you there for more.
- Wikipedia: Comparison of Unicode encodings
- Jon Skeet's answer on Stack Overflow about UTF-8 vs Unicode
- UTF8, UTF16 and UTF32 (on Stack Overflow)
- Difference between UTF-8 and UTF-16 (on Stack Overflow)
What classes are provided in System.Text?
In .NET framework, <a href="https://msdn.microsoft.com/en-us/library/system.text%28v=vs.110%29.aspx">System.Text</a> namespace is responsible for all of the encoding based on characters. It includes the Encoding class, which can be used to encode the string into bytes and/or encode the bytes into a string and so on. There are quire a lot of options allowed in .NET framework to be used.
The ambiguity comes, when there are members, Unicode, UTF8, UTF7, UTF32 in the Encoding class (note that there is no UTF16, that is Unicode itself). To note there, there is a class for these encodings too. You can use them both, as Encoding.UTF8, or as UTF8Encoding for your application. The documentation about System.Text has a lot of more resources for you to read and understand the concept of encodings in .NET framework.
Note: UTF8Encoding inherits from Encoding. Or specifically every class ending with Encoding in System.Text namespace inherits from Encoding class and has similar functionality as being a member of Encoding class.
Points of Interest
Unicode
Unicode is a standard for character encoding and decoding for computers. You can use different encodings from Unicode, UTF-8 (8 bit) UTF-16 (16 bit) and so on. These encodings are used to globalize the applications, and provide a locale interface to the users enabling them to use the applications in their own language, not just English. In most frameworks (including .NET and Java) Unicode means UTF-16 encoding; 2-bytes size for each character. Surrogate-pairs are used to represent the rest of characters that cannot map directly in 2-byte UTF-16 encoding code page.
Why use UTF-8?
UTF-8 is a variable-length encoding provided by Unicode and can accomodate every character, its size ranges from 1 byte to 4 bytes, depending on the code page that the character exists on. All of the websites, news applications and media devices use UTF-8, because of its light weight and efficiency.
Unicode in .NET
.NET framework has a built-in support for Unicode characters; the char object in .NET framework represents a unicode character; UTF-16.
You can use Unicode characters in different .NET applications from Console application, WPF application all the way to web applications based on ASP.NET framework. You can encode and decode the strings into characters, and integers. In console application you need to ensure that the character and the code page is supported in the font family that you're going to use otherwise you might face a question mark on screen.
You do not need to write anything to support Unicode, it is there by default.
Character-mapping problems
As the discussion started on this question, mostly the data captured in Unicode is lost somewhere, and the character is no longer mapped to a valid character. Thus the program would try to print '?' on screen. Possible reason to such a problem is mentioned in the question (attached) and you can have a look at it.
Also, Sergey Alexandrovich Kryukov has suggested how to tackle such scenarios by saying,
Sergey Alexandrovich Kryukov: (Ignore the text in italics; specific to the question)
If font-family was a problem it shows a box, not '?'. And Perso-Arabic is supported nearly everywhere. There is a non-Unicode encoding. And it could be this damn 864 - totally inappropriate. Or it could be due to, say, varchar. It's simple: if you transcode Unicode string in encoding not representing some characters, all software generates '?'. As simple as that. So the answer would be: use Unicode and only Unicode. There is no need to use any UTF (it's better to stay away unless stream is used). For example, nvarchar is automatically mapped to .NET Unicode strings via ADO.NET.
You can read about the Unicode and the UTFs in the article above.
History
First version of the post.
Second version of the post: I have fixed most of the problems; most specially that character-to-integer conversion in Console application code block. I have added a few more paragraphs to clarify the purpose of codes, and fixed some typo also formatter the paragraphs to add some better readability.
Third version: Made a lot of positive and helpful changes (thanks to Sergey Alexandrovich Kryukov for their excellent support and guidance). Changed the header from "Different Unicodes" (ambiguous) to "A little in-depths about Unicode encoding (pretty much obvious). Added Endianness details, Unicode as standard and Unicode as encoding.

