Introduction
The big ball of mud is a (tongue-in-cheek) architecture pattern that describes the vast majority of actual real-world applications. It occurs when an application or codebase grows by accretion over a long period of time without the discipline of an architecture.
The lack of architecture makes it difficult to build upon this base. Developers can start to fear the code because there is a high risk that a code change in one area can raise bugs in an unrelated part of the application. Since the source code is a very significant part of the developer's working environment, this big ball of mud leads to developer discontent and even high developer turn over.
Step 1: Recognise You Have a Problem
Just as is the case with the twelve steps program, the first step is to recognise that you have a problem. If you are a developer working in a big ball of mud, you probably will already have a feeling that something bad will be going on. Interestingly, developers from outside of the project are more likely to raise the red flag because those on the inside have familiarity with the codebase which can hide the true size of the problem.
If you don't have access to independent and trusted developers to cast an eye over the code, then the next best thing is to run some form of code analysis over the code base. In Visual Studio 2013 Professional, this can be done by selecting the menu: Analyze -> Calculate Code Metrics for Solution. You can also use the output of these code metrics to get buy-in from whoever is paying the bills to help you address the problem. By taking the output from this and running it into Excel, you can get some pretty useful graphs to show where the problems are: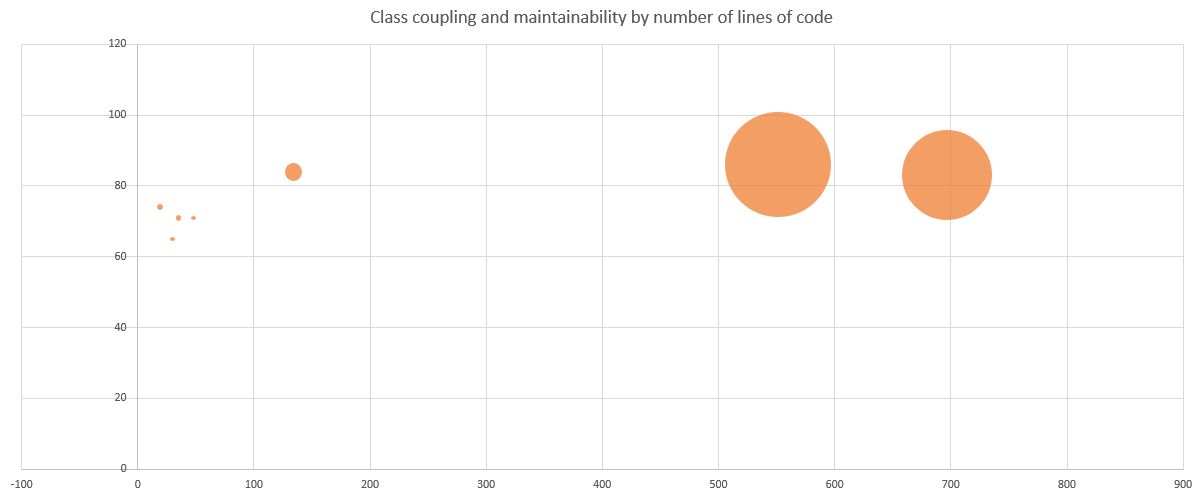
This image shows "miantainability" on the left hand axis and class coupling on the bottom axis, with code base size indicated by the size of the bubble. From this, you can see that the maintainability ranges between 60-100 regardless of project size. This would appear to be quite good, but "maintainability" is a fairly coarse metric.

This graph shows cyclomatic complexity, which shows the number of independent paths possible through the code. From this case, you can see that testing this code base and verifying each path is going to be a huge problem and a problem that gets markedly worse as the code base size increases.
Step 2: Triage
The first reaction of most people when they encounter the big ball of mud is to run away screaming. This can be leaving the job or trying to get an internal transfer to get as far away as possible. The bad news is that there are so many big balls of mud out there that you are as likely to move into a new big ball of mud when you do move.
An alternative is to improve the code from within. To do this, you should start by doing a triage: deciding what cannot be saved, deciding what does not need to be saved and deciding what needs saving and can be saved.
What Does Not Need to Be Saved?
If a particular project has a very low rate of change, then the return on investment of improving the code quality will be low no matter how bad the code itself is. This is because the most significant cost of bad code is the increase in cost to change this incurs.
What Cannot Be Saved?
If the size of a code base is so large and the problems within it so many, there comes a cross-over point where the cost of rewriting the project from scratch exceeds the cost of fixing it. If this is the case, then a decision needs to be made to create a new project that replaces the functionality of this existing project and, once that is done, to retire this existing unsaveable project.
What follows applies to the remainder - what can be saved.
Step 3: Build a Test Framework
If you are going to refactor a code base that has been deployed, then you are going to need a significant test framework to be comfortable that the changes you make to improve the code don't end up making new issues in the compiled application.
Initially, it is unlikely that there will be existing unit tests and it is also unlikely that the code will be amenable to introducing unit tests. (It is one of the stated benefits of unit testing and test driven development that it encourages good code practices. Unfortunately, the reverse is also the case - bad code practices make unit testing harder if not downright impossible.)
One possibility is to automate "whole system" tests. This can be done using available front-end test automation tools (for example "Project White") and by having side-by-side test environments set up using virtual machine so that at every step, the impact of the changes can be assessed.
Step 4: Communicate the Plan
Getting buy-in from the people who are funding the software improvement is only the first part of the communication you will need to do. The technical staff will also need to have the plan (and probably a statement of the problem) walked through with them, in particular to that they do not feel there is any implicit criticism of their own work.
"This will take too long/we can't afford it/published release schedules will slip" - you will definitely encounter this reaction. This is symptomatic of a human bias that favours the immediate over a greater long term reward.
Step 5: Get Stuck In
Start by putting together a black-box overview of the major components in the code base. What is their purpose, what inputs do they require, and what do they produce as output. Draw out the relationships between these to give you a sense of the level of entanglement in the current system.
Next, decide on the preferred architecture or model you would like to have "if you have that time again". This will indicate what the best fit software architecture is for the business processes that are performed by the software.
The exact details of what you are going to need to change will, of course, be highly dependent on your own code but the following are often a good place to start.
Examples of some code remediation techniques:
- Split large classes into smaller classes by functional area. You can do this by starting out with partial classes so that you can move the code blocks around in the IDE without breaking the build. Once you are happy with this, hive each partial class off into its own distinct class which can be tested as a unit.
- Decouple using interfaces - where classes are passed as parameters to other classes' methods or constructors, introduce an interface that is implemented by the class and pass that instead of the concrete class. Again, this aids unit testing but also makes it easier for multiple people to work on the same code base by relying on these interfaces.
- Make the compiler take on more responsibility - by replacing any implicit array indexes with enumerated types, any untyped lists or arrays with their generic equivalent and so on.
- Introduce diagnostics - trace statements and performance counters, to allow you to investigate what the compiled application is doing and how well.
- Define your own application's custom exceptions and wrap any framework exceptions in that to add business impact information to the exception if one is raised. (e.g. instead of "File not found" have a business exception like "Unable to load today's exchange rates - prior date exchange rates in use (File not found)".
- Add XML comment tags to the code. These can be built into developer documentation (using a tool like Sandcastle) or they can also show up in the IDE as the developer is referencing the components thus commented.
- Identify any cross cutting concerns (such as logging) and introduce a standard patterns and practices library (such as PRISM) in place of your own custom code. Likewise, if you have a DIY database layer, then moving to something like NHibernate or Entity Framework is advised.
There are many other code remediation techniques - in the spirit of sharing, if you have any, please leave them in the comments section and I will include them here.
Step 6: Measure and Report Progress
At the end of each sprint (or however you are breaking up your code improvement project), redo the code analysis from step 1. Graphing this over time will show the improvement which in turn will help you keep the momentum going until you get to a better place.
History
- 21st March, 2015 - Initial version

