(Contains the Mono Project files including all the required Acoustic Models and 2 additional Sample Wave Audio Files. Just click the "Download zip" button on the bottom right corner.)
The framework used in this article is available as an open-source project. You can find a link to the repository below.
https://github.com/SynHub/syn-speech
Introduction
This article explains continuous speaker independent Speech Recognition in Mono by taking 2 different approaches to transcribe an Audio file (encoded in WAVE Format) to text.
Background
Coming to speech recognition in Mono Linux - I had been waiting patiently for a revelation to hit me. Especially because I am working on a smart-house project and I do not wish to use Windows as my primary OS in the project. Instead, I use Linux and Mono framework. I was indeed in need of a Speech Recognition library that I could use. So after months of whining all over the internet, I finally found a suitable candidate.
A glowing amber ring appeared over my head and I decided to share my experience and some useful code here on CodeProject.
GitHub Repository
Recently (at the time of this edit), the framework has been open-sourced. You can find the entire source code of the Speech Recognition engine here.
Getting Started
Now to get to business, I am not going to create some sci-fi GUI to demonstrate the functionalities and the usage paradigms. Instead, I am going to make use of the good-old-fashioned Console interface.
In MonoDevelop
I am going to work with MonoDevelop but Visual Studio developers shouldn't find it hard to follow. On the contrary, this should be easier for developers using Visual Studio.
Launch MonoDevelop -> File -> New -> Solution and Select Console C#
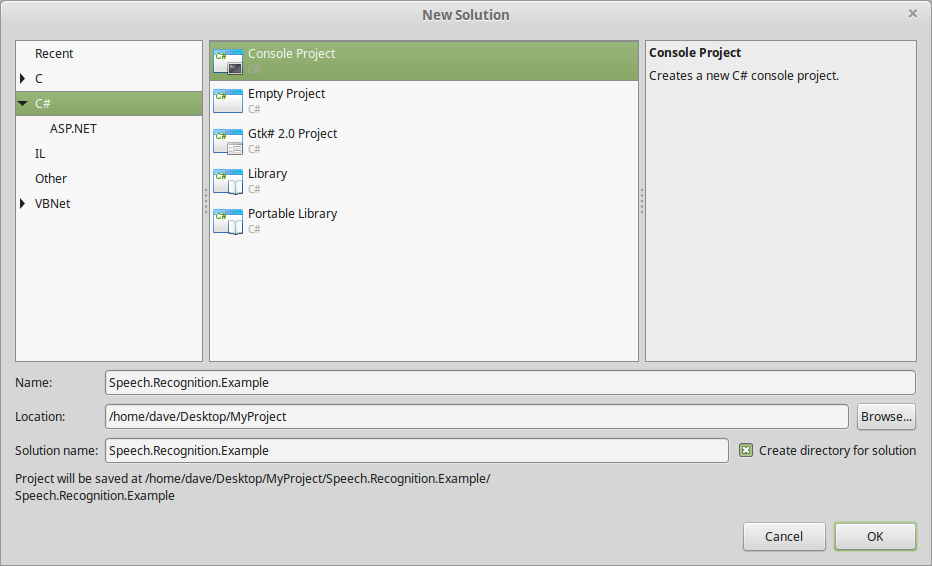
Once you've created your Console Project, you'll have to go ahead and import the required NuGet package.
To do so (if you've already installed the NuGet Package Manager in MonoDevelop), right click your Project name and select Manage NuGet Package...
You'll be presented with a Manage Package... dialog. In the search box, type Syn.Speech and press enter.

Once the library is found, click on Add.
In Visual Studio
Select FILE -> New -> Project -> Visual C# -> Console Application
To import the library into your project, click on TOOLS -> NuGet Package Manager -> Package Manager Console and type:
PM> Install-Package Syn.Speech
Fantastic! We've imported the required library.
Moving on, the library on its own cannot just transcribe a given audio file without some data backing it up. In the field of speech recognition, these are called the Acoustic Models.
Getting the Required Files
Most of the models are pretty large since they are trained on a large amount of data and describe a complex language. And that's one of the reasons why I haven't uploaded them to this article.
So bear with me and download the project file attached to this article..
Once you've downloaded the file, extract the archive. Browse to the Bin/Debug directory and you'll find the Models and the Audio folders. Copy and paste these folders within your Mono Project's Bin/Debug directory.
Alright, so we've got the required Models (Acoustics Models) and the Audio files to transcribe.
Time to write some code...
Transcribing an Audio File without Grammar
The speech recognition engine that we are making use of can (at the moment of writing this tutorial) only deal with WAVE Audio files.
In the Audio directory, we have 2 audio files namely Long Audio.wav and Long Audio 2.wav. Before we go ahead and try to transcribe these files, listen to Long Audio 2.wav. You'll find someone speaking "The time is now exactly twenty five to one".
For any offline speech recognition engine (that deals with a limited set of Acoustic Models), the above sentence is a pretty long sentence to transcribe. But we are going to transcribe it anyways, so hang on.
Within the MainClass of your Console application, add the following C# code:
static Configuration speechConfiguration;
static StreamSpeechRecognizer speechRecognizer;
The above code declares 2 important objects that we'll be initializing later on.
The first is the Configuration class. This class holds information like the location of the Acoustic Models, Language Models and Dictionary. On top of that, it also tells the speech recognizer whether we intend to use Grammar files or not.
Moving on, the StreamSpeechRecognizer class is the main class that allows you to direct Audio stream into the speech recognition engine. And once the computation is done, it's this same class that we'll use to get the results back.
Getting the Log Information
We cannot just blindly let the StreamSpeechRecognizer transcribe the audio file for us without knowing what's going on internally. We should instead try to learn more about it. End of story.
To get the internal log generated by the Speech Recognition Engine, add the following C# code just below the aforementioned static variables.
static void LogReceived (object sender, LogReceivedEventArgs e)
{
Console.WriteLine (e.Message);
}
Now within the Main method, add the following line:
Logger.LogReceived += LogReceived;
Great! So now, whatever message is received by the logger, it will be written into the Console.
Let's initialize and setup the Configuration and StreamSpeechRecognizer class.
Add the following code within the Main method.
var modelsDirectory = Path.Combine (Directory.GetCurrentDirectory (), "Models");
var audioDirectory = Path.Combine (Directory.GetCurrentDirectory (), "Audio");
var audioFile = Path.Combine (audioDirectory, "Long Audio 2.wav");
if (!Directory.Exists (modelsDirectory)||!Directory.Exists(audioDirectory)) {
Console.WriteLine ("No Models or Audio directory found!! Aborting...");
Console.ReadLine ();
return;
}
speechConfiguration = new Configuration ();
speechConfiguration.AcousticModelPath=modelsDirectory;
speechConfiguration.DictionaryPath = Path.Combine (modelsDirectory, "cmudict-en-us.dict");
speechConfiguration.LanguageModelPath = Path.Combine (modelsDirectory, "en-us.lm.dm
In the code above, I created a few variables that hold the location of the Models and the Audio directory within the Bin/Debug folder.
Later in the code, there's this naggy check - To verify if you've properly copied the Audio and Models directory into the right folder.
Down the line, we meet the speechConfiguration variable and initialize its properties.
speechConfiguration.AcousticModelPath - Path where most of our Acoustic Model files have been placedspeechConfiguration.DictionaryPath - Path to the dictionary file (which in our case is present within the Models directory)speechConfiguration.LanguageModelPath - Path to the Language Model file (also present within the Models directory)
All of the above properties MUST be assigned before we transfer the configuration to the speech recognizer.
Why So Many Path.Combine(s) ?
Well, the path separator-character in Windows and Linux are different, i.e., Windows uses backslash (\) while Linux uses forward slash (/). Path.Combine takes care of this mess while combining paths making sure that our code works both in Windows and in Linux.
Firing Up the StreamSpeechRecognizer
Add the following code after the above code:
speechRecognizer = new StreamSpeechRecognizer (speechConfiguration);
speechRecognizer.StartRecognition (new FileStream (audioFile, FileMode.Open));
Console.WriteLine ("Transcribing...");
var result = speechRecognizer.GetResult ();
if (result != null) {
Console.WriteLine ("Result: " + result.GetHypothesis ());
}
else {
Console.WriteLine ("Sorry! Coudn't Transcribe");
}
Console.ReadLine ();
In the above code, we first instantiate the speechRecogizer object and then call the StartRecognition method and pass a FileStream that points to the Audio file we're trying to transcribe.
Speech recognition actually doesn't start after we call the StartRecognition method, instead the computation begins only when we call the GetResult method.
Once the result has been computed, we call the GetHypothesis method to retrieve the hypothesis as a string.
Overall Code for Transcribing an Audio File without Grammar
using System;
using Syn.Speech.Api;
using System.IO;
using Syn.Logging;
namespace Speech.Recognition.Example
{
class MainClass
{
static Configuration speechConfiguration;
static StreamSpeechRecognizer speechRecognizer;
static void LogReceived (object sender, LogReceivedEventArgs e)
{
Console.WriteLine (e.Message);
}
public static void Main (string[] args)
{
Logger.LogReceived += LogReceived;
var modelsDirectory = Path.Combine (Directory.GetCurrentDirectory (), "Models");
var audioDirectory = Path.Combine (Directory.GetCurrentDirectory (), "Audio");
var audioFile = Path.Combine (audioDirectory, "Long Audio 2.wav");
if (!Directory.Exists (modelsDirectory)||!Directory.Exists(audioDirectory)) {
Console.WriteLine ("No Models or Audio directory found!! Aborting...");
Console.ReadLine ();
return;
}
speechConfiguration = new Configuration ();
speechConfiguration.AcousticModelPath=modelsDirectory;
speechConfiguration.DictionaryPath = Path.Combine (modelsDirectory, "cmudict-en-us.dict");
speechConfiguration.LanguageModelPath = Path.Combine (modelsDirectory, "en-us.lm.dmp");
speechRecognizer = new StreamSpeechRecognizer (speechConfiguration);
speechRecognizer.StartRecognition (new FileStream (audioFile, FileMode.Open));
Console.WriteLine ("Transcribing...");
var result = speechRecognizer.GetResult ();
if (result != null) {
Console.WriteLine ("Result: " + result.GetHypothesis ());
} else {
Console.WriteLine ("Sorry! Couldn't Transcribe");
}
Console.ReadLine ();
}
}
}
If you run the above code (Press Ctrl+F5 in MonoDevelop), you should see a Console with lots of information flowing up. In the end (after a couple of seconds), you should see the result on your screen. Something like the following:
Hopefully, you've transcribed your audio file.
You might have noticed that it took the application a couple of seconds to transcribe the Long Audio 2.wav file. This is because we haven't used any Grammar file in our configuration. Which shrinks the search domain to a limited number of specified tokens.
Next, we'll see how to use a Grammar file to specify a set of words and sentences we wish to recognize.
Transcribing an Audio file using Grammar (JSGF)
To transcribe an audio file or stream using Grammar, we first need to create a Grammar file duh! The library supports JSGF (JSpeech Grammar Format) grammar files.
Syntax of JSGF is pretty simple and is the actual syntax from which SRGS (Speech Recognition Grammar Specification) was initially derived.
JSGF Syntax is beyond the scope of this article. However, I will place a simple exemplary code in front of you.
Suppose you wish to recognize 2 bizarrely isolated sentences like:
- The time is now exactly twenty five to one
- This three left on the left side the one closest to us
Your JSGF Grammar file's content would look something like the following.
#JSGF V1.0;
grammar hello;
public <command> = ( the time is now exactly twenty five to one |
this three left on the left side the one closest to us );
More information on creating JSGF Syntax can be found here.
For simplicity, I have already created a JSGF Grammar file for you and placed it within the Models directory. (With the name "hello.gram"). The content of which you're seeing above.
To make the StreamSpeechRecognizer use the Grammar file we've created, we need to set 3 important properties of the Configuration class prior to passing it as an argument to the StreamSpeechRecognizer.
speechConfiguration.UseGrammar = true;
speechConfiguration.GrammarPath = modelsDirectory;
speechConfiguration.GrammarName = "hello";
speechConfiguration.UseGrammar = true; - Tells the speech recognizer that we intend to use a Grammar filespeechConfiguration.GrammarPath - The path where the Grammar file is located- speechConfiguration.GrammarName - Name of the grammar we wish to use (case-sensitive in Linux). Omit .gram extension as it's automatically appended
Overall Code for Transcribing an Audio File using Grammar
using System;
using Syn.Speech.Api;
using System.IO;
using Syn.Logging;
namespace Speech.Recognition.Example
{
class MainClass
{
static Configuration speechConfiguration;
static StreamSpeechRecognizer speechRecognizer;
static void LogReceived (object sender, LogReceivedEventArgs e)
{
Console.WriteLine (e.Message);
}
public static void Main (string[] args)
{
Logger.LogReceived += LogReceived;
var modelsDirectory = Path.Combine (Directory.GetCurrentDirectory (), "Models");
var audioDirectory = Path.Combine (Directory.GetCurrentDirectory (), "Audio");
var audioFile = Path.Combine (audioDirectory, "Long Audio 2.wav");
if (!Directory.Exists (modelsDirectory)||!Directory.Exists(audioDirectory)) {
Console.WriteLine ("No Models or Audio directory found!! Aborting...");
Console.ReadLine ();
return;
}
speechConfiguration = new Configuration ();
speechConfiguration.AcousticModelPath=modelsDirectory;
speechConfiguration.DictionaryPath = Path.Combine (modelsDirectory, "cmudict-en-us.dict");
speechConfiguration.LanguageModelPath = Path.Combine (modelsDirectory, "en-us.lm.dmp");
speechConfiguration.UseGrammar = true;
speechConfiguration.GrammarPath = modelsDirectory;
speechConfiguration.GrammarName = "hello";
speechRecognizer = new StreamSpeechRecognizer (speechConfiguration);
speechRecognizer.StartRecognition (new FileStream (audioFile, FileMode.Open));
Console.WriteLine ("Transcribing...");
var result = speechRecognizer.GetResult ();
if (result != null) {
Console.WriteLine ("Result: " + result.GetHypothesis ());
} else {
Console.WriteLine ("Sorry! Couldn't Transcribe");
}
Console.ReadLine ();
}
}
}
If you run the application, you'll get the audio file transcribed within milliseconds and the output would still be the same.
So that concludes my venture for this initial release.
External Resources
Points of Interest
Transcribing an Audio file is a slow and time consuming process. I recommend sticking with JSGF Grammar files for faster speech recognition. But do remember that the Grammar file names are case-sensitive in Linux.
Coming to performance, the library performed slightly well under .NET Framework when compared to Mono but the differences were virtually non-existent when I used a custom limited-in-size Grammar file.
The speech recognition engine can make use of all the acoustic Models published by Carnegie Mellon University. They are available on source forge but I would rather encourage using the bleeding edge Acoustic Models data found in this GitHub repository of the Sphinx4 project.
History
- Friday, 29th of March 2015 - Initial release
- Monday, 9th of October 2017 - Minor edit
- Wednesday, 26th of August 2020 - Minor edit (Added a link to the the open-source library code)

