I have been studying the new PLINQ and Parallel Task Library in .NET 4 looking for various ways to do things that we can’t do in .NET 2.0. PLINQ is huge, and there are a lot of new ways to do multi threaded programming using .NET 4. In this article, I want to cover a particular problem I have had many times over the years. How do you speed up multithreaded apps that are bound by blocking functions, or long running I/O operations?
I started looking at this method to speed up some long running file I/O routines deep in the VistaDB engine. Most of the time, we are blocked in reads from disk before we can continue working, but usually we have part of the blocks we need. So we could start working, and then continue when the rest of the blocks are loaded. Adding that logic is complex and prone to error with traditional threading code. Fortunately PLINQ has a way to make some of these types of operations very simple.
Reading Multiple Websites
For this example, I am going to read the first page of 8 websites and then act on that information afterwards. This is the type of very simple parallel operation that splits up really well. But these types of long running reads are very similar to what happens in many applications.
Side Note on C# 4.0 In a Nutsell Book
I actually adopted this example from one given in Joseph Albahari’s book C# 4.0 In a Nutshell (he is also the author of the excellent LinqPAD). Weighing in a 1000 pages is not exactly a Nutshell, but it is a fantastic book for developers who already know C# and just want to go through C# and CLR 4. The concepts in the book cover older versions of .NET as well, but the juicy parts for me were all the new changes.
LINQ Expression
Ok, this expression will go to 8 websites in this list and get the first page of each. The content length of the page and the content type are then stored in a variable to be used outside of the parallel computation later.
static void Main(string[] args)
{
Stopwatch sw = new Stopwatch();
sw.Start();
var results = from site in new[]
{
"http://infinitecodex.com",
"http://www.vistadb.net",
"http://stackoverflow.com",
"http://cornerstonedb.com",
"http://www.bing.com/",
"http://www.linqpad.net",
"http://www.cnn.com",
"http://www.microsoft.com"
}
let p = WebRequest.Create( new Uri(site)).GetResponse()
select new
{
site,
Length = p.ContentLength,
ContentType = p.ContentType
};
foreach (var result in results)
{
Console.WriteLine("{0}:{1}:{2}",
result.site, result.Length, result.ContentType);
}
sw.Stop();
Console.WriteLine("Total Time: {0}ms", sw.ElapsedMilliseconds);
}
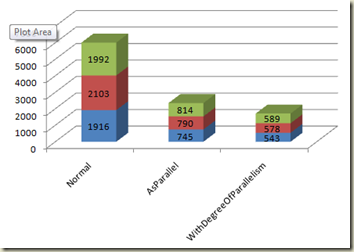
The initial runs were done with no Parallel extensions being used. Just go through each site and get the first page, storing the ContentLength and the ContentType in the temp variable p. Afterwards, I foreach over the results to output them to a command line. If you take this step out, nothing actually happens because of deferred execution in LINQ (you have to do something with the collection before it is really run). I wrapped all of this in a Stopwatch so I would know how long it took. The graph at the top of this article are the 3 fastest times I received after running each method 10 times.
Three fastest times normal execution (ms): 1916, 2103, 1992.
Adding Parallel (PLINQ)
Now, let's make this use PLINQ and see if it runs faster.
The only change we have to make is to add a single line of code above the let statement like this.
}
.AsParallel()
let p = WebRequest.Create( new Uri(site)).GetResponse()
That’s it, and the entire LINQ query will now run parallel. It is faster, but not as fast as we can get it.
Three fastest times with AsParallel() (ms): 745, 790, 814.
What PLINQ is doing under the hood is creating a thread pool and spinning up 4 threads on my 4 core machine. But what it doesn’t know is that each of these operations are blocking waiting on I/O from the website. PLINQ assumes that each thread will have a moderate amount of CPU work to do, so it prevents spinning up a lot of threads that would just overwhelm the CPU.
How can we tell the .NET framework that each of these parallel operations are not CPU intensive?
WithDegreeOfParallelism
From the MSDN help: WithDegreeOfParallelism<TSource> - Degree of parallelism is the maximum number of concurrently executing tasks that will be used to process the query.
Now that doesn’t exactly explain in plain English that you can use this to tell the framework the task is not CPU intensive. Technically, you are overriding the default behavior of PLINQ and telling it you know how many of these should be allowed to run concurrently.
In this case, I am going to set 8 because I know that two of these objects per CPU core is not going to tax my system at all. The maximum you can set is 64. Now each of these thread pools will attempt to run more than 1 thread at a time. Why can we do this without incurring a lot of task switching overhead? Because the objects are all blocked in I/O. The OS will put them to sleep and release the CPU for other tasks to run anyway, we are just going to give each of those tasks more work to keep them a little busier.
Again, a single line change to the first query is all that is needed:
}
.AsParallel().WithDegreeOfParallelism(8)
let p = WebRequest.Create( new Uri(site)).GetResponse()
Three fastest times with 8 Parallelism set (ms): 543, 578, 589.
That is 3.5 times faster than the original query with one line code changed!
Summary
PLINQ and the .NET 4 framework give you a lot of power to speed up parallel operations very easily. In my page manager application, I was able to get a 4.5x improvement in the page cache manager through the techniques listed in this article. And through changing my queue mechanisms over to the new Concurrent classes, I was able to eliminate a lot of dead time wasted on locking and gained even more performance, but that is another blog post at some point in the future.

