I’ve been successfully using NHibernate as my first ORM for a few years. The complex mappings seemed like a bit of overhead initially, but after a slow start, the flexibility available usually paid off later. A few attempts to use Entity Framework for new projects ended up with me switching back to NHibernate, since EF had limited functionality, like no support for enums, for example. About a year ago, as Entity Framework got more mature and a few months after version 6 was released, I made a conscious decision to try and use it for a while. You simply need to know what’s on the other side of the fence to be able to choose between these ORMs wisely.
For every new application that I write, I usually start with an object model and design/generate the database schema later. I think this approach lets me think more about the business rules associated with the entities and not end up with a bunch of Data Transfer Objects that map directly to database tables. In Entity Framework’s terms, I’m using the Code-First approach. It was introduced in version 4.1 and has since been improved considerably.
Things I Liked
All in all, the newest EF left a positive impression. Here are a couple of things that I liked and are worth mentioning.
DbContext Design
First of all, I like the design of DbContext. Since I’m usually using Domain-Driven Design concepts in my code base, I have entities that are the roots of an aggregate. That means that you retrieve and save the whole aggregate through its root object. DbContext has some DbSet properties to expose objects that we can save and read from database. This maps very nicely with aggregate root concept, since you can define DbSets only for the roots of aggregates. This way, you ensure that all operations will go through the roots.
public class OrderingContext: DbContext
{
public DbSet<Customer> Customers { get; set; }
public DbSet<Order> Orders { get; set; }
}
Auto Mappings
A feature that I immediately took a liking to is the default, convention based mapping. To get started with EF, all you need is to follow some conventions in your object model and include these types in a DbContext derivative. For example, let’s say we have this model:
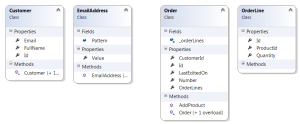
I intentionally wrote a more complex object model than a simple collection of properties to show that it can support a more complex object model. We inform EF that we need to persist this model to database by deriving from DbContext and adding specific entity sets, as shown in the previous code example.
That’s it! That’s all you need. As long as the standard conventions are being followed, the database schema will be generated as you first use the OrderingContext, so there’s no manual work involved. As you start out, you don’t even have to worry about connection strings – EF 6 uses LocalDB to store the data by default and all the configuration is already added when you install the official NuGet package.
Database Initializers
Next good feature – database initializers and the ability to recreate the whole database if the object model changes. Let’s say we add a property to Customer class:
public class Customer
{
public int Id { get; private set; }
public EmailAddress Email { get; private set; }
public string FullName { get; private set; }
public DateTime RegistrationDate { get; private set; }
...
}
If we run the application, we get an exception telling “The model backing the ‘OrderingContext’ context has changed since the database was created.”. That occurs when the object model does not match database schema. We can quickly fix that by adding a database initializer telling EF to drop and recreate the whole schema after object model changes:
public class OrderingContext: DbContext
{
public DbSet<Customer> Customers { get; set; }
public DbSet<Order> Orders { get; set; }
protected override void OnModelCreating(DbModelBuilder modelBuilder)
{
Database.SetInitializer<OrderingContext>
(new DropCreateDatabaseIfModelChanges<OrderingContext>());
base.OnModelCreating(modelBuilder);
}
}
After running the application again, it should work as expected. This allows for some quick prototyping with as little friction as possible. For the best experience, don’t forget to create the initial objects that are needed for the application to work:
public class SampleDataInitializer : DropCreateDatabaseIfModelChanges<OrderingContext>
{
protected override void Seed(OrderingContext context)
{
context.Customers.Add(new Customer
(new EmailAddress("test@test.com"), "Test Customer"));
context.SaveChanges();
}
}
public class OrderingContext: DbContext
{
public DbSet<Customer> Customers { get; set; }
public DbSet<Order> Orders { get; set; }
protected override void OnModelCreating(DbModelBuilder modelBuilder)
{
Database.SetInitializer<OrderingContext>(new SampleDataInitializer());
base.OnModelCreating(modelBuilder);
}
}
The Irritating Things
Of course, the features I mentioned above are only useful at the start of the project. You probably won’t be able to recreate the database every time the model changes if you have already deployed your application to production. And I’m not even talking about additional DB objects, like views or stored procedures – there’s no way we can manage that with just EF. As the DB schema grows bigger, you probably will have some kind of database project or script, so every change in object model will need to reflect in that project too. That leads us back to some manual work.
If you have been using EF for some time, you have probably seen the monstrous queries it can generate. There’s also a lack of SQL statement batching and second level cache support. However, I would like to point out a few other things that I didn’t like at all.
Bypassing Object Model Constraints
First, I’d like to mention a feature that enables to bypass any encapsulation rules of your object model. I first saw another developer on a project used it. Let’s say we have a Customer entity that properly protects its invariants:
public class Customer
{
public int Id { get; private set; }
public EmailAddress Email { get; private set; }
public string FullName { get; private set; }
protected Customer()
{
}
public Customer(EmailAddress email, string fullName)
{
if(email == null)
throw new ArgumentNullException("email");
if (string.IsNullOrEmpty(fullName))
throw new ArgumentException("fullName");
this.Email = email;
this.FullName = fullName;
}
}
From the code, you can see that it is ensured that for any new customer, email and full name are required. This is a simple example of how you can implement some of the business rules using only your programming language features. It is an approach that I highly recommend and try to teach everyone to know and use. However, if we are using EF, we can do this:
var invalidCustomer = context.Customers.Create();
context.Customers.Add(invalidCustomer);
Here you go, the rules have just been broken. Any ORM will require a parameterless constructor to work. It calls it to create an object of the class to restore state from DB to. That’s why there is a hidden constructor in all the classes that have any other constructors defined. It’s a necessary evil for the ORM magic to work. EF brought it conveniently on the surface by exposing a Create() method on DbSet, that uses that same constructor and creates an uninitialized object bypassing any rules that you have worked hard to implement.
Deleting Children with Uni-directional Relations
In an object model, when you model relations between objects, the relation can be bi-directional, meaning that two entities have a reference to each other, or uni-directional, meaning that only one of the entities has a reference to another entity. If we are following Domain-Driven Design guidance, you should prefer uni-directional relations to bi-directional ones. It reduces complexity of the model and creates better boundaries between different classes. Entity Framework lets you have uni-directional relationships, as seen in the demo object model, where an Order has a list of OrderLines, but OrderLine does not reference the order. We can work with a model like that, but what happens when we delete a child object from collection?:
using (var context = new OrderingContext())
{
var order = context.Orders.Include("OrderLines").Single(x => x.Id == orderId);
order.RemoveProducts(productId);
context.SaveChanges();
}
It works. Next time you get the order from the database, the order line will not be there. However, if we look at the database, we have a problem here:

What EF does is set the foreign key value to NULL and leave the deleted object’s data in the database. This effectively creates trash in your database and there’s apparently no way to fix that. There is a workaround to fix this, but it involves accessing the DbContext:
using (var context = new OrderingContext())
{
var order = context.Orders.Include("OrderLines").Single(x => x.Id == orderId);
var removedOrderLine = order.RemoveProducts(productId);
context.Entry(removedOrderLine).State = EntityState.Deleted;
context.SaveChanges();
}
This means that you cannot encapsulate deletion logic in your object model alone. In my opinion, this is an inconvenient hack. I do not want to see these details leaking into my object model.
Automatic ID Generation
Another thing that disappointed me is ID generation features. In EF, only three types of IDs are supported: assigned values, Guids and Identity. If you don’t want to use Guids or generate values manually, you’re only left with Identity generation. The problem with that is that to generate the ID, you need to write the underlying data to database. This disables any possible optimizations, like delaying the writes to DB when you want to get the ID before saving the data. Let’s say, we want to generate order number using it’s ID in the database. With EF, the only possible way is like this:
using (var context = new OrderingContext())
{
var customer = context.Customers.First();
var order = new Order(customer.Id, "123456");
context.Orders.Add(order);
context.SaveChanges();
order.SetGeneratedNumber(order.Id);
context.SaveChanges();
}
As you see in the example, you need to save the order to database, then take the generated ID, create an order number value and then save to the database again. With NHibernate, for example, it’s possible to use client side ID generation, that does not need to go to DB to generate a unique ID. This enables to achieve the same functionality with only a single save operation.
Conclusion
After using Entity Framework for all new projects over the last year, I’ve come to like it more than before. It became a mature ORM by this time, having its pros and cons. However, I still think NHibernate is more suitable for my needs in both its API and features. So after this little adventure with EF Code First, I’m planning to get back to having NHibernate as my default choice for new projects. From the experience with EF, I’ll try to figure out how to make the start with NHibernate for new projects easier, like recreating database automatically, using convention based mappings (haven’t used Fluent NHibernate’s auto mapping) and similar features.
The source code that I’ve been using for this post’s examples can be found
here.
CodeProject



