Background
This article follows on from the previous three Searcharoo samples:
Searcharoo Version 1 describes building a simple search engine that crawls the file system from a specified folder, and indexes all HTML (or other known types) of document. A basic design and object model was developed to support simple, single-word searches, whose results were displayed ina rudimentary query/results page.
Searcharoo Version 2 focused on adding a 'spider' to find data to index by following web links (rather than just looking at directory listings in the file system). This means downloading files via HTTP, parsing the HTML to find more links and ensuring we don't get into a recursive loop because many web pages refer to each other. This article also discusses how multiple search words results are combined into a single set of 'matches'.
Searcharoo Version 3 implemented a 'save to disk' function for the catalog, so it could be reloaded across IIS application restarts without having to be generated each time. It also spidered FRAMESETs and added Stop words, Go words and Stemming to the indexer. A number of bugs reported via CodeProject were also fixed.
Introduction to version 4
Version 4 of Searcharoo has changed in the following ways (often prompted by CodeProject members):
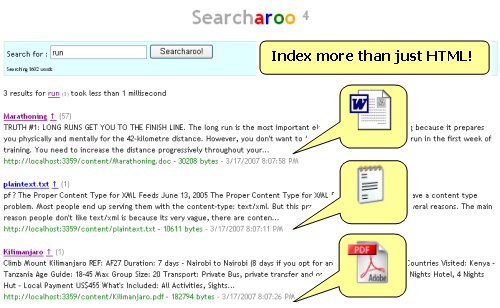
- It can now index/search Word, Powerpoint, PDF and many other file types, thanks to the excellent Using IFilter in C# article by Eyal Post. This is probably the coolest bit of the whole project - but all credit goes to Eyal for his excellent article.
- It parses and obeys your robots.txt file (in addition to the robots META tag, which it already understood) ( cool263).
- You can 'mark' regions of your html to be ignored during indexing (xbit45).
- There is a rudimentary effort to follow links hiding in javascript ( ckohler).
- You can run the Spider locally via a CommandLine application then upload the Catalog file to your server (useful if your server doesn't have all the IFilter's installed to parse the documents you want indexed).
- The code has been significantly refactored (thanks to encouragement from mrhassell and j105 Rob). I hope this makes it easier for people to read/understand and edit to add the stuff they need.
Some things to note
- You need Visual Studio 2005 to work with this code. In previous versions I tried to keep the code in a small number of files, and structure it so it'd be easy to open/run in Visual WebDev Express (heck, the first version was written in WebMatrix), but it's just getting too big. As far as I know, it's still possible to shoehorn the code into VWD (with App_Code directory and assemblies from the ZIP file) if you want to give it a try...
- I've included two projects from other authors: Eyal's IFilter code (from CodeProject and his blog on bypassing COM) and the Mono.GetOptions code (nice way to handle Command Line arguments). I do NOT take credit for these projects - but thank the authors for the hard work that went into them, and for making the source available.
- The UI (Search.aspx) hasn't really changed at all (except for class name changes as a result of refactoring) - I have a whole list of ideas & suggestions to improve it, but they will have to wait for another day.
Design & Refactoring
The Catalog-File-Word design that supports searching the Catalog remains basically unchanged (from Version 1!), however there has been a total reorganization of the classes used to generate the Catalog.
In version 3, all the code to: download a file, parse the html, extract the links, extract the words, add the to catalog and save the catalog was crammed into two classes (Spider and HtmlDocument see right).
Notice that the StripHtml() method is in the Spider class - doesn't make sense, does it?
| 
|
This made it difficult to add the new functionality required for supporting IFilter (or any other document types we might like to add) that don't have the same attributes as an Html page.
To 'fix' this design flaw, I pulled out all the Html-specific code from Spider and put it into HtmlDocument. Then I took all the 'generic' document attributes (Title, Length, Uri, ...) and pushed them into a superclass Document, from which HtmlDocument inherits. To allow Spider to deal (polymorphically) with any type of Document, I moved the object creation code into the static DocumentFactory so there is a single place where Document subclasses get created (so it's easy to extend later). DocumentFactory uses the MimeType from the HttpResponse header to decide which class to instantiate.
You can see how much neater the Spider and HtmlDocument classes are (well OK, that's because I hid the Fields compartment). To give you an idea of how the code 'moved around': Spider went from 680 lines to 420, HtmlDocument from 165 to 450, and the Document base became 135 lines - the total line count has increased (as has the functionality) but what's important is the way relevant functions are encapsulated inside each class.
The new Document class can then form the basis of any downloadable file type: it is an abstract class so any subclass must at least implement the GetResponse() and Parse() methods:
GetResponse() controls how the class gets the data out of the stream from the remote server (eg. Text and Html is read into memory, Word/PDF/etc are written to a temporary disk location) and text is extracted. Parse() performs any additional work required on the files contents (eg. remove Html tags, parse links, etc).
The first 'new' class is TextDocument, which is a much simpler version of HtmlDocument: it doesn't handle any encodings (assumes ASCII) and doesn't parse out links or Html, so the two abstract methods are very simple! From there is was relatively easy to build the FilterDocument class to wrap the IFilter calls which allow many different file types to be read.
To demonstrate just how easy it was to extend this design to support IFilter, the FilterDocument class inherits pretty much everything from Document and only needs to add a touch of code (below; most of which is to download binary data, plus three lines courtesy of Eyal's IFilter sample). Points to note:
- BinaryReader is used to read the webresponse for these files (in HtmlDocument we use StreamReader, which is intended for use with Text/Encodings)
- The stream is actually saved to disk (NOTE: you need to specify the temp folder in *.config, and ensure your process has write permission there).
- The saved file location is what's passed to IFilter
- The saved file is deleted at the end of the method
public override void Parse()
{
}
public override bool GetResponse (System.Net.HttpWebResponse webresponse)
{
System.IO.Stream filestream = webresponse.GetResponseStream();
this.Uri = webresponse.ResponseUri;
string filename = System.IO.Path.Combine(Preferences.DownloadedTempFilePath
, (System.IO.Path.GetFileName(this.Uri.LocalPath)));
this.Title = System.IO.Path.GetFileNameWithoutExtension(filename);
using (System.IO.BinaryReader reader = new System.IO.BinaryReader(filestream))
{
using (System.IO.FileStream iofilestream
= new System.IO.FileStream(filename, System.IO.FileMode.Create))
{
int BUFFER_SIZE = 1024;
byte[] buf = new byte[BUFFER_SIZE];
int n = reader.Read(buf, 0, BUFFER_SIZE);
while (n > 0)
{
iofilestream.Write(buf, 0, n);
n = reader.Read(buf, 0, BUFFER_SIZE);
}
this.Uri = webresponse.ResponseUri;
this.Length = iofilestream.Length;
iofilestream.Close(); iofilestream.Dispose();
}
reader.Close();
}
try
{
EPocalipse.IFilter.FilterReader ifil
= new EPocalipse.IFilter.FilterReader(filename);
this.All = ifil.ReadToEnd();
ifil.Close();
System.IO.File.Delete(filename);
} catch {}
}
And there you have it - indexing and searching of Word, Excel, Powerpoint, PDF and more in one easy class... all the indexing and search results display work as before, unmodified!
"Rest of the Code" Structure
The refactoring extended way beyond the HtmlDocument class. The 31 or so files are now organised into five (5!) projects in the solution:
| EPocalipse.IFilter | Unmodified from Using IFilter in C# CodeProject article |
|---|
| Mono.GetOptions | Wrapped in a Visual Studio project file, but otherwise unmodified from a Mono source repository |
|---|
| Searcharoo | All Searcharoo code now lives in this project, in three folders:
/Common/
/Engine/
/Indexer/ |
|---|
| Searcharoo.Indexer | NEW Console Application, allows the Catalog file to be built on a local PC (more likely to have a wide variety of IFilter's installed), then copied to your website for searching.
You could also create a scheduled task to regularly re-index your site (it's also great for debugging). |
|---|
| WebApplication | The ASPX files used to run Searcharoo.
They have been renamed to:
Search.aspx
SearchControl.ascx
SearchSpider.aspx
Add these files to your website, merge the web.config settings (update whatever you need to), ensure the Searcharoo.DLL is added to your /bin/ folder AND make sure your website 'user account (ASPNET)' has write permission to the web root. |
|---|
New features & bug fixes
I, robots.txt
Previous versions of Searcharoo only looked in Html Meta tags for robot directives - the robots.txt file was ignored. Now that we can index non-Html files, however, we need the added flexibility of disallowing search in certain places. robotstxt.org has further reading on how the scheme works.
The Searcharoo.Indexer.RobotsTxt class has two main functions:
- Check for, and if present, download and parse the robots.txt file on the site
- Provide an interface for the Spider to check each Url against the robots.txt rules
Function 1 is accomplished in the RobotsTxt class constructor - it reads through every line in the file (if found), discards comments (indicated by a hash '#') and builds an Array of 'url fragments' that are to be disallowed.
Function 2 is exposed by the Allowed() method below
public bool Allowed (Uri uri)
{
if (_DenyUrls.Count == 0) return true;
string url = uri.AbsolutePath.ToLower();
foreach (string denyUrlFragment in _DenyUrls)
{
if (url.Length >= denyUrlFragment.Length)
{
if (url.Substring(0, denyUrlFragment.Length) == denyUrlFragment)
{
return false;
}
}
}
if (url == "/robots.txt") return false;
return true;
}
There is no explicit parsing of Allowed: directives in the robots.txt file - so there's a little more work to do.
Ignoring a NOSEARCHREGION
In HtmlDocument.StripHtml(), this new clause (along with the relevant settings in .config) will cause the indexer to skip over parts of an Html file surrounded by Html comments of the (default) form <!--SEARCHAROONOINDEX-->text not indexed<!--/SEARCHAROONOINDEX-->
if (Preferences.IgnoreRegions)
{
string noSearchStartTag = "<!--" + Preferences.IgnoreRegionTagNoIndex +
"-->";
string noSearchEndTag = "<!--/" + Preferences.IgnoreRegionTagNoIndex +
"-->";
string ignoreregex = noSearchStartTag + @"[\s\S]*?" + noSearchEndTag;
System.Text.RegularExpressions.Regex ignores =
new System.Text.RegularExpressions.Regex(ignoreregex
, RegexOptions.IgnoreCase | RegexOptions.Multiline |
RegexOptions.ExplicitCapture);
ignoreless = ignores.Replace(styleless, " ");
}
Links inside the region are still followed - to stop the Spider searching specific links, use robots.txt.
Follow Javascript 'links'
In HtmlDocument.Parse(), the following code has been added inside the loop that matches anchor tags. It's a very rough piece of code, which looks for the first apostrophe-quoted string inside an onclick="" attribute (eg. onclick="window.location='top.htm'") and treat it as a link.
if ("onclick" == submatch.Groups[1].ToString().ToLower())
{
string jscript = submatch.Groups[2].ToString();
int firstApos = jscript.IndexOf("'");
int secondApos = jscript.IndexOf("'", firstApos + 1);
if (secondApos > firstApos)
{
link = jscript.Substring(firstApos + 1, secondApos - firstApos - 1);
}
}
It would be almost impossible to predict the infinite variety of javascript links being used, but this code should hopefully provide a basis for people to modify to suit their own site (most likely if tricky menu image rollovers or something bypass the regular href behaviour). At worst it will be extract something that isn't a real page and get a 404 error...
Multilingual 'option'
Culture note: in the last version I was really focussed on reducing the index size (and therefore the size of the Catalog on disk and in memory). To that end, I hardcoded the following Regex.Replace(word, @"[^a-z0-9,.]", "") statement which agressively removes 'unindexable' characters from words. Unfortunately, if you are using Searcharoo in any language other than English, this Regex is so agressive that it will delete a lot (if not ALL) of your content, leaving only numbers and spaces!
I've tried to improve the 'useability' of that a bit, by making it an option in the .config
<add key="Searcharoo_AssumeAllWordsAreEnglish" value="true" />
which governs this method in the
Spider:
private void RemovePunctuation(ref string word)
{
if (Preferences.AssumeAllWordsAreEnglish)
{
word = System.Text.RegularExpressions.Regex.Replace(word,
@"[^a-z0-9,.]", "",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
}
else
{
word = word.Trim
(' ','?','\"',',','\'',';',':','.','(',')','[',']','%','*','$','-');
}
}
In future I'd like to make Searcharoo more language aware, but for now hopefully this will at least make it possible to use the code in a non-English-language environment.
Searcharoo.Indexer.EXE
The console application is a wrapper that performs the exact same function as SearchSpider.aspx (now that all the code has been refactored out of the ASPX and into the Searcharoo 'common' project). The actual console program code is extremely simple:
clip = new CommandLinePreferences();
clip.ProcessArgs(args);
Spider spider = new Spider();
spider.SpiderProgressEvent += new SpiderProgressEventHandler(OnProgressEvent);
Catalog catalog = spider.BuildCatalog(new Uri(Preferences.StartPage));
That's almost identical to the SearchSpider.aspx web-based indexer interface.
The other code you'll find in the Searcharoo.Indexer project relates to parsing the command line arguments using the Mono.GetOptions which turns the following attribute-adorned class into the well-behaving console application below with hardly an additional line of code.
What it actually does when it's running looks like this:
Just as with SearchSpider.aspx you'll see the output as it follows links and indexes text from each page in your website. The verbosity setting allows you to control how much 'debug' information is presented:
| -v:0 | None: totally silent (no console output) |
| -v:1 | Minimal: Just page names and wordcounts |
| -v:2 | Informational: Some error information (eg. 403, 404) |
| -v:3 | Detailed: More exception and other info (eg. cookie error) |
| -v:4 | VeryDetailed: Still more (eg. robot Meta exclusions) |
| -v:5 | Verbose: outputs the extracted words from each document - VERY VERBOSE |
NOTE: the exe has it's own Searcharoo.Indexer.exe.config file, which would normally contain exactly the same settings as your web.config. You may want to consider using the Indexer if your website contains lots of IFilter-documents (Word, Powerpoint, PDF) and you get errors when running SearchSpider.aspx on the server because it does not have the IFilters available. The catalog output file (searcharoo.dat or whatever your .config says) can be FTPed to your sever where it will be loaded and searched!
References
There's a lot to read about IFilter and how it works (or doesn't work, as the case may be). Start with Using IFilter in C#, and it's references: Using IFilter in C# by bypassing COM for references to LoadIFilter, IFilter.org and IFilter Explorer
dotlucerne also has file parsing references).
Searcharoo now has it's own site - searcharoo.net - where you can actually try a working demo, and possibly find small fixes and enhancements that aren't groundbreaking enough to justify a new CodeProject article...
Wrap-up
Hopefully you find the new features useful and the article relevant. Thanks again to the authors of the other open-source projects used in Searcharoo.
History
- 2004-06-30: Version 1 on CodeProject
- 2004-07-03: Version 2 on CodeProject
- 2006-05-24: Version 3 on CodeProject
- 2007-03-18: Version 4 (this page) on CodeProject

