Introduction
This article is an entry for the Lean and Mean competition, which ran on The Code Project during August 2009.
This is a console version of my previous entry. As such, it also uses the diff algorithm with the linear space refinement. I have included the original paper in the downloads. In this version, I have halved the memory requirements, but the algorithm is the same.
Correction: According to Wikipedia, the algorithm was written by Douglas McIlroy in the early 70's while Eugene W. Myers only described it in his paper. Apologies.
Background
If N = number of lines in the first file, M = number of lines in the other file and D = number of different lines, then the diff algorithm is O( (N+M) D ) in time and O( N+M ) in space.
This is far better than the LCS algorithm, which is O( N * M ) in both time and space. For the test files N = 1784, M = 1789 and D = 19. So in this case, the complexity of the LCS algorithm is several orders of magnitude fatter and slower than the diff algorithm.
I have to repeat my appreciation of McIlroy's algorithm. The more I have learned about it, the more impressed I have become. I certainly couldn't invent anything better!
Using the Code
The demo is a console application that uses the diff implementation, which is in a separate assembly. The demo takes two file paths as arguments. It reads the files, calculates the diff and displays the results and some timing measurements. There is a #define in program.cs that optionally measures the change in Process.PeakWorkingSet64.
Results
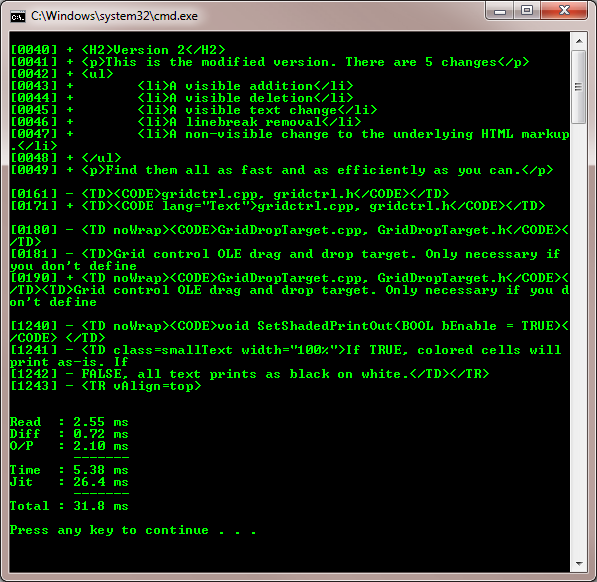
The screenshot above shows the timing results for a typical run. Not including the JIT compilation gives times of about 5.5 ms. Including it gives overall times of about 32 ms.
The main arrays used by the algorithm are now a bit under 30 KB, so the calculated memory use is 420 KB plus change.
Other entries measure the change in Process.PeakWorkingSet64, so I will do the same. The measurements vary dramatically, but values of 600 - 700 KB are common.
History
- 2009 08 31: First edition

