Introduction
"Nothing in the world can take the place of persistence. Talent will not; nothing is more common than unsuccessful men with talent. Genius will not; unrewarded genius is almost a proverb. Education will not; the world is full of educated derelicts. Persistence and determination alone are omnipotent. The slogan 'Press On' has solved and always will solve the problems of the human race."
-- Calvin Coolidge
Calvin is a C++ persistence library or framework that allows programmers to easily save and load objects using keys. Objects are associated with a user configurable type of key that can be used to name objects specifically and save them or load them by that name.
This feature is the primary distinguishing difference between Calvin and the many other persistent libraries.
A quick snippet shows what this means:
filesys_archive ar( "../data" );
boost::shared_ptr<C> c( new C( "c" ));
ar.save( c );
c.reset();
c = ar.load<C>( "c" );
Calvin has most of the features you would expect in a persistence library. It's relatively painless to add persistence to your objects, with the only overhead being the addition of the name member to your objects. The above snippet uses a string, but virtually any value type1 can be used as a key.
This article assumes a working knowledge of C++ and how to use templates. The accompanying code has only been tested on VC 7.1, though I suspect it would work on either the Comeau or GCC 3.3+ compilers. It also requires the Boost libraries 1.31 or greater to be accessible.
Background
There are many persistence libraries available for C++ programmers, so why write another one? The short answer is that no library had the features I needed and to revise any of them would probably have taken more time than rolling my own. Calvin isn't a large library.
That's not to say that I don't owe those other libraries an intellectual debt. Calvin builds on their ideas to enable the features that I needed. Perhaps you might need these features as well.
As you can see in the above snippet, Calvin allows a programmer to name instances and then save and load them. Of what value is this feature? To see the difference, consider what most other persistence frameworks do (or don't do as the case may be).
Other persistence frameworks are little more than serialization of an object into an alternate form. This is good for allowing an object to be sent across the wire or simply dumped to disk. But what if that object contains references to other objects? Usually these contained objects are serialized as well within the original object. Say you have objects A, B and C. B contains a pointer to A, as does C.
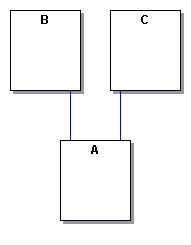
You serialize B, it in turn serializes A and both are dumped to their store. You do likewise for C, and all is good with the world.
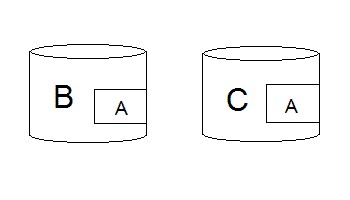
But what happens when you load B and C from the store? In most libraries, you would end up with two objects of type A that B and C each reference now. How to get around this duplication problem?
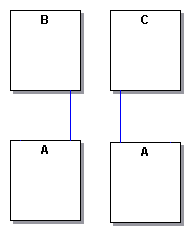
There are two commonly implemented solutions to this problem.
The first and most common is to require a root object that contains all the objects, such as a document or a 3D scene. This root object is the only object that may start a persistence operation, thereby eliminating the duplicate references outside of a single archive. This really isn't a solution but a constraint to the problem above.
Another solution is to allocate all objects to be persisted from a special pool, and then the pool is what is saved. This really doesn't eliminate the root object, but simply shifts it, making the pool the mandatory root object to be persisted.
Many applications don't find this prohibiting and can operate well within these constraints. Some applications, such as the one I write, share data across documents quite a bit, and if one piece of shared data is updated or changed, that change should be reflected in all the other documents. Calvin's solution is to allow shared instances to be named, and to then save each instance in its own record within an archive.
Therefore, in our scenario above, when B is saved, so is A, but A is stored on its own record and a reference to A is saved with B. Likewise, when C is saved, A is saved and C saves a reference to A. When C is loaded, it loads A. When B is loaded, Calvin notices that A has already been loaded and a reference to A is returned to B, so that B and C once again refer the same object.
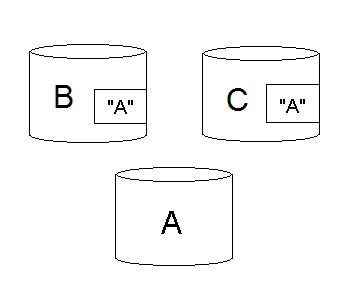
This type of late binding allows me to write utilities that operate on certain objects, such as a texture, without having to know about which 3d models use it.
Using Calvin
To use Calvin in your own applications, it requires three steps. First you must outfit your classes so that they may be persisted. Second you must name your instances when created. Last, write the code to load and save your objects in the appropriate places in your application. Let's look at how these are done in that order.
A Persistent Class
As nice as it would be to gain persistence with no additional code, C++ just doesn't have the facilities necessary to do it. Some scaffolding is necessary to achieve persistence.
The first question to ask yourself is, if the class must be made persistent in the first place? While lightweight, there is still some overhead involved. If yes, then will it need its own name? If it is an object potentially referenced by more than one object, then yes, it will need a name. Otherwise, it may be persisted inside a containing object (as Figure 2 above).
But what type to use for naming? std::string is my own preferred type, but by the virtue of template parameters, a name may be any value type that may be converted to a string via the << operator. Integers meet these requirements and only add 4 bytes of overhead. And if you keep your integer names as an enum within a single .h file, it is very quick and convenient too. (The test/example program in the accompanying source code gives an example of strings and ints as keys.)
If you're satisfied with your answers to these questions, then comes the relatively painless part of making the class potentially persistent.
#include "calvin.h"
class A : public calvin::persistent<std::string> {
int a;
float a2;
double a3;
struct Aa {
int a4;
int a5;
Aa(void) : a4(4), a5(5) {}
};
Aa a6;
public:
A( void ) : a(1), a2(2.0f), a3(3.0), a6(Aa())
{
}
A( const std::string& name ) :
persistent<std::string>(name), a(1), a2(2.0f), a3(3.0), a6(Aa())
{
}
virtual ~A( void )
{
}
protected:
template <typename Stream>
Stream& serialize( Stream& s, const unsigned int version )
{
return s ^ a ^ a2 ^ a3 ^ a6.a4 ^ a6.a5;
}
private:
friend calvin::allow_persistence<A>;
static const int version_ = 1;
};
As you can see, making a class persistent is simple. Five alterations and your class is ready to be saved to or loaded from an archive (which we will discuss further below).
- calvin.h contains all the code necessary to make a class persistent.
- The class itself must then inherit from
calvin::persistent with the template parameter being the key type that names the object. Requiring inheritance rather than just using convention does two things; it provides the necessary base variable _name, as well as type information used by the library to know how to handle objects, whether they should be written as part of their containing object or handled as independently named objects.
- The class is required to have a default constructor (one with a parameter list of type
void ) and one that takes a single parameter of the type used as a key. These are used by the library when restoring objects from persisted state.
- The workhorse of persistence is the
serialize method. The same method may be used for saving and loading through the use of the overloaded ^ operator. As well, the version parameter allows a class to update and change while maintaining backward compatibility. Order is important in this method.
- This friendship works around many issues and provides the Calvin library with necessary access to members even if they are private. It's merely for convenience, but is well worth the one line of code.
- The version of the class, persisted with the class so that backward compatibility may be preserved.
There are some additional features of the library that can be used in place of the steps above, usually to solve specific problems that the more general features might not allow.
It is a matter of convenience that the library allows you to use a single method for saving and loading objects. Sometimes this is not practical or even possible. In this case, the serialize method may be split into two as below:
std::ostream& serialize( std::ostream&, unsigned int );
std::istream& serialize( std::istream&, unsigned int );
Though it probably goes without saying, the method taking a std::ostream& as its parameter is the one called for saving, and the method taking a std::istream& parameter is the one used for loading. Also note the lack of the template parameter. Each may perform the operations necessary to save or restore the object. These methods should use the ^ operator as used in the generic method example rather than the normal >> and << operators.
To demonstrate the other features, let's examine a class that builds on the class A above.
struct made_of_prims {
int i;
float f;
double d;
};
class persistent_void_test : public calvin::persistent<void> {
std::string msg;
friend struct calvin::allow_persistence<void>;
public:
persistent_void_test( void ) : msg( "I'm a calvin::persistent<void>" ) {}
template<typename Stream>
Stream& serialize( Stream& s, unsigned int version )
{
return s ^ msg;
}
};
class B : public A {
public:
B( void ) : A(), b1(0), b2(1), stupid(NULL) {}
B( const std::string& name ) : A(name), b1(0), b2(1), stupid(NULL) {}
B( const std::string& name, const char* stupid ) :
A(name), b1(0), b2(1), stupid(stupid)
{
return;
}
virtual ~B( void ) {}
void add( made_of_prims& p)
{
vec_of_prims.push_back( p );
}
private:
int b1;
unsigned int b2;
std::vector<made_of_prims> vec_of_prims;
persistent_void_test sm;
const char* stupid;
template <typename Stream>
Stream& serialize( Stream& s, const unsigned int version )
{
return A::serialize( s, version ) ^
b1 ^
b2 ^
vec_of_prims ^
sm ^
PtrArray<const char>( stupid, (stupid == NULL) ?
0 : (unsigned int) strlen(stupid)+1 );
}
friend calvin::allow_persistence<B>;
};
The above example highlights some additional features and requirements of the library when making your class persistent.
- The type
calvin::persistent<void> is a special type that allows a class, not to have a name, but still have a serialize method be called. Since the object does not have a name, it is stored inside its containing object, and therefore may not be the base class for a shared object.
- Calvin works with all the objects in your hierarchy, no matter how deeply subclassed.
- To use it though, call any base class
serialize methods directly and before serializing your own members.
- Some of the STL containers are automatically handled. As of this writing, Calvin knows about
vectors, lists, and deques. Other container types should be trivial to add and will be as necessity dictates.
- Use the helper
PtrArray to handle arrays. This is to give Calvin a size to use since it can't be known from the array itself. STL containers such as vector are preferred by Calvin.
- Even in subclasses, friendship must be explicitly granted since friendship is not transferred to subclasses.
- An additional note, not illustrated above, is that
boost::shared_ptr is supported. boost::shared_array is not yet supported.
Calvin and Types
The examples above demonstrate how most types of data are supported, but here is a more thorough reference to how Calvin handles members of different data types in a serialize method.
- A value type, such as a plain old data (meaning a built in data type) or structure of value types is stored in the record of the named object (see
calvin::persistent<void> below for structures that are not collections of value types).
- A pointer is dereferenced and the value stored in the record as is. Upon loading, if the pointer is NULL, it is allocated with
new and then restored, otherwise it is assumed to point to a location of enough size to take the value.
- A pointer to a pointer (to a pointer, etc.) is dereferenced ad nauseum until the value type is procured. Calvin must assume that space has already been allocated. This can be done in the serialize method before reading the pointer if necessary.
- An array of known size (declared as
T[#]) is stored in the record of the object, its count stored with it. On a load, if the number in the stream is greater than the declared size, an error is signaled.
boost::shared_ptr to non Calvin objects are treated as pointers.
string is handled as a value type rather than just as an array of characters.
- Standard C++ containers are handled element by element. How and where each element is handled is determined by its type. For now only
vectors, lists, and deques are supported, though using the code in calvin.h as a template (no pun intended), any standard container should be simple to persist.
calvin::persistent value objects with a key equal to a default value (using the special template construct T()) have their serialize method invoked with the same stream as their containing object so that they are persisted in the same record.
- A structure or class that contains a pointer or container cannot be considered a value type and therefore cannot be persisted without inheriting from
calvin::persistent. It is not always desirable for a persistent class to contain the overhead of a key though. The calvin::persistent<void> class was created for this purpose. A structure that inherits from calvin::persistent<void> has a serialize method that is called to handle its members, but doesn't have the overhead of a key. They are persisted to and from the store of the containing object.
- Named objects must be stored using
boost::shared_ptr. This is so that Calvin can return pointers to already loaded objects and track them to know when an object's lifetime is expired.
Congratulations on having made it this far. Enabling classes for persistence is the most complicated part of using the Calvin library. Just persist a little more.
"What's in a name?"
Instances to be persisted need to be named. Naming your instances is as straightforward as the snippet at the beginning of the article shows. Simply invoke the object's constructor that takes a name when the object is created, or use the set_name function later to give it a name. That's it.
What are legal names for instances? As mentioned above, it can be any value type that can be converted to a string via the << operator. Also, the name must be compatible with the archive selected. See the documentation for an archive type for what is considered legal.
Names must be unique for each instance. They distinguish instances within the store and the program. As persistent objects are created or loaded, their names are added to a registry. When a second attempt to load an object by its name is attempted, the original instance is returned instead of a new instance. Calvin reports an error when an object is created with a name already used (see Error Handling in Calvin below).
To make unique names to instances possible, Calvin works with boost::shared_ptr exclusively. This way, named objects have an automatic tracking mechanism so that when they are deleted, Calvin can know to load one at the next request. Why doesn't Calvin just keep a permanent reference? Memory issues mostly, but I think that a library shouldn't do things such as that behind the curtains when the facility of another excellent library can already do it with minimal fuss.
"Where do you want this?"
Where do these objects go when they are persisted? They go into archives. Archives are collections of named objects. Archives can conceivably be the front end for any type of store such as files or a database. For now, the only implemented archive is the file_archive. file_archive has a template parameter that must match the key type of the objects to be written and read using it. A convenient filesys_archive is declared as a file_archive<string>.
As its name implies, the filesys_archive simply stores objects in files named the names given to them in the program. For this reason, when using a filesys_archive, names must consist of only valid filename characters, which depends on your particular operating system. A good rule of thumb is to stick with alphanumeric, '.', and '_', if using.
To use a filesys_archive (or file_archive), include fs_archive.h in the appropriate .cpp file and declare your archive with a single string parameter representing the root directory, as so.
filesys_archive ar( "../data" );
Initiating a save requires a boost::shared_ptr to a named object.
boost::shared_ptr<MyPersistentClass> p( "p" );
ar.save( p );
In the above you should see a file named "p" in the directory "data".
To use the object later, an archive loads an object given a name and returns a boost::shared_ptr to the object.
boost::shared_ptr<MyPersistentClass> p;
p = ar.load( "p" );
Error Handling in Calvin
Exceptions or error codes? That seems to be question. Exceptions are the standard error reporting mechanism in C++, but there are many valid reasons for avoiding them. In this regard, I took the route that the Boost libraries did and give the programmer an option.
Depending on the value of the NO_CALVIN_EXCEPTIONS macro at compile time, either an exception (of type calvin_exception) is thrown, or the function calvin::throw_exception is called. If the function option is chosen, then the programmer must define a function by that name to handle any errors. The function should take a single parameter of type calvin_exception.
calvin_exception is a subclass of std::exception, and uses the what parameter to store the cause. Call calvin_exception.what() to see the error string.
To the Persistent Go the Spoils!
That's it for using Calvin. I've been using Calvin in my own applications for several months now with nary a problem. Then again, I know it and tend to perhaps skirt its warts unintentionally. It should be considered 0.1 software. I would welcome any bug fixes.
Calvin isn't done yet though. Current plans to extend it are to include a ZIP archive and an XML archive. The next article will be a tutorial on creating new archives by subclassing stream buffers. If you'd like a deeper explanation on the inner workings of Calvin, e-mail me and I might write up another article talking about the template type matching that makes Calvin work.
In the meantime, peruse the source code. It's compact, simple, and pretty straightforward. I've included it here and written this article hopefully so that you can use it and extend it to suit your needs. The example/test program included with this article requires that Boost version 1.31 or later be installed in the calvin subdirectory. Also, the Boost file system library should be built and available to the test program for linking.
Calvin is copyright by myself, Jay Kint, and licensed for use under the MS-PL license. It should be considered "as-is" and no warranty is intended or implied.
The author would like to thank John Olsen for his contributions and feedback on this article.
Footnotes
1A value type is one that isn't a pointer or a reference. If you can assign from one variable to a second variable, assign something else to the first variable, and the second variable hasn't changed, then those variables types are considered value types. For example:
T x, y;
x = something;
y = x;
x = something_else;
print x;
print y;
If T is a value type, then x should print something_else and y
should print something.
If x and y print something_else, then T is not a value type.
References
- Boost
Specifically the serialization library, type traits, shared pointers, and file system libraries. Lots of other good things are there as well.
If you don't know the boost libraries, check them out.
- Eternity
Great little persistence library, which was my first choice, until I started running into the limitations that prompted Calvin.
- Holub, Allen; MSJ, June 1996
Every persistence library I've run across has mentioned this article as a source. Worth the read just for an idea of what
should be in a persistence library whether you're a user or designer.
History
- 1/29/2005
First draft posted for review.
- 2/5/2005
Second draft posted for review.
- 2/8/2005
Article submitted to CodeProject.
Jay Kint has been a software engineer/hacker for most of his life, starting with 8 bit Ataris. After a lengthy stint in the game industry, he now works at Microsoft in SQL Server.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






