A process that runs as a Windows service is meant to provide a service or do work without stopping. It should always be there and provide that service or do the work when it needs to be done, it should never fail. These services could be running mission critical processes, executing trades for banks, or transactions for e-commerce platforms, insurance claims for insurers, the list goes on. Almost all companies have these systems and the impact a failed service can have on a company and resources can be significant. People are either having to scramble to work through a backlog, or are being called at out of office hours to restart a failed system.
These services fail all too often though, and for really bad reasons. For mature products (that have gone through a through a QA cycle), the cause is most often the unavailability of another resource. This can be a database that's busy and is generating timeout errors, or has gone temporarily offline (a reboot or similar), an external webservice that's not available or any number of other resource with availability issues.
In this blog, I'm going to show you how to build high availability windows services that can deal with these and many other issues, recover or even fix failures and continue to execute their mission critical task with minimal delay.
I started working on this problem at Merrill Lynch. The director I was working for suggested at one of the many design meetings I had with him, that I figure out a way to design a service pattern that could withstand temporary db, network and other service outages. That initial design has evolved many iterations, this one is I think the most concise and cleanest. It can be adapted to work outside of the service framework as well, by incorporating it into an exception management framework for example.
The Service State Engine
This solution uses the 'State Engine' or 'State' design pattern from the 'Gang of Four' to solve the problem. A service is typically in the 'Running' State, but when exceptions that can't be handled occur, the service changes into its 'Diagnostic' State. In this state, the service tries to determine what happened, it may probe the environment to come to a conclusion, but typically, a regular expression analysis of the exception message is enough to diagnose the error. The state of the service then changes to the 'Recovery' state. Diagnostic information is provided to the recoverer and depending on the diagnosis, it can take different actions to get the system back to the 'Running' state. In the case of outage for example, the recovery state may simply wait until the outage is resolved and then resumes work by changing back to the 'Running' state. Often, the Recoverer will actively take steps to 'fix' a problem, this could be starting an external service that it depends on, or any other type of action that a user would have to take to get a system back in working condition.
Design & Implementation
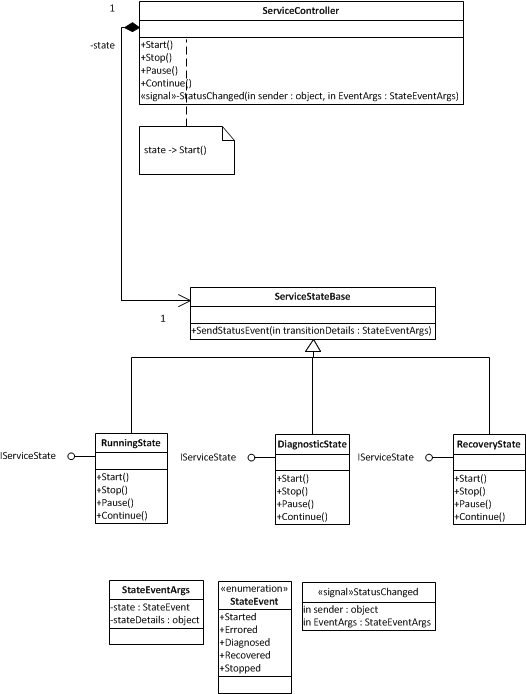
This solution is easy to apply to any given service because the RunningState is essentially the service as it would be implemented without the Diagnostic/Recover states. By separating out the Diagnostic and Recovery States into their own classes, we give them a single responsibility, it keeps the solution clean and ensures that the states don't muddle each other's logic. Transitions from one state to another are managed through the ServiceController. The Service States fire events as necessary and the controller receives them and assigns a new state to manage the events as necessary (shown below).
void ServiceStateBase_StatusChanged(object sender, EventArgs<StateEventArgs> e)
{
switch (e.EventData.state)
{
case StateEvent.Errored: ChangeState(diagnosticState);
diagnosticState.SetException((Exception) e.EventData.stateDetails);
diagnosticState.Start();
break;
case StateEvent.Diagnosed: ChangeState(recoveryState);
recoveryState.Diagnosis = (Diagnostic) e.EventData.stateDetails;
recoveryState.Start();
break;
case StateEvent.Recovered: ChangeState(runningState);
runningState.Start();
break;
case StateEvent.Stopped : ChangeState(runningState);
break;
}
}
The code above is a snippet from the service controller, the code snippet is really the heart or brain of the controller. When the states fire events, the controller intercepts them and assigns a new state manager as necessary to deal with the event. Line 5 shows the controller handling an error event, it changes state to the diagnosticState and sets the exception property for the diagnostic to analyze. The responsibility of the diagnostic is as its name implies to diagnose the error. It is usually enough to just analyze the error message, but it may sometimes be necessary to probe the environment for more information if the error string doesn't provide enough information for a complete diagnosis.
The diagnosis of an error is very specific to the environment, dependencies and logic of the solution that has been implemented. Solutions tend to exhibit failure trends that start to show themselves as soon as a product goes into integration testing, by the time the product goes into production, you'll have encountered most of the failure scenarios. As you encounter them, you should update the diagnostic to be able to recognize them, and the recoverer to be able to deal with them. The code snippet below deals with the most common errors I've discussed above. We first deal with the sudden unavailability of external systems. With regard to the sample solution, that's a companion to this blog that would be the database and messagebus. We can recognize those issues by simply looking at the exception type or analyzing the exception message.
protected void Diagnose(Exception e)
{
if (MessageBusError(e))
{
diagnosis = Diagnostic.MessageBusUnavailable;
}
else if (DatabaseError(e))
{
diagnosis = Diagnostic.DatabaseError;
}
else if (errorsInInterval() < 100)
{
diagnosis = Diagnostic.Unknown;
}
else
{
logger.Fatal("Fatal error occurred", exception);
diagnosis = Diagnostic.FatalForUnknownReasons;
}
}
Other exception may occur and I've added a counter and interval check to recognize a sudden surge in exceptions that could indicate a new failure scenario that's as yet unhandled. If that's the case, the system will report it and diagnose the error as a Fatal error.
Recovery from database failure is very simple, you wait a set amount of time and try test the connectivity, when the database is available again a "recovered" event is fired and the controller sets the state to the "runningState" again. This recovery scenario applies to most external systems that go offline for some reason.
In "real life" scenarios, I've had to deal with external services that would periodically fail, but who I could programmatically restart from within the service I was building. In those instances, the recoverer would execute the restart logic and a previous failure that would have killed the service was recognized and fixed within milliseconds of occurring. In fact, this previously common failure scenario was all but considered fixed, even though the issue kept recurring, but it no longer had no impact on dependent services. By far, the most common 'recovery' scenario though is simply waiting for an external system to come back online.
The beauty of this system is that it really works well, in fact it works so well that it's sometimes easier to recover from a defect in another system than it is to fix that system. And that is something that you do have to keep in mind, not to just treat the symptoms but to still go after the cause. However, the benefits to having a system that can solve problems, instead of just quitting is really great, especially for those mission critical systems. It also creates a much more stable environment, where services can adapt to the standard 'hicups' in an environment as it occurs. Rebooting a machine or restarting a database no longer requires the coordinated effort of an operations team spread out over many divisions when the services that depend on it can deal with the temporary outage.
The entire solution can be found in this blogs companion website, the source code repository at CodePlex. The LogService is built using the Service State Engine described in this blog.
Happy coding!
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




