Introduction
What data structure should you use? What data structure should you avoid?
Imagine that you have to use a data structure. It is nothing fancy,
only a storage for raw numbers, or POD data carriers that you will use now and then and some later on.
These items will be inserted, then removed intermittently. They will have
some internal order, or significance, to them and be arranged accordingly.
Sometimes insertions and removal will be at the beginning or the end but
most of the times you will have to find the location and then do an insertion
or removal somewhere in between. An absolute requirement is that
the insertion and removal of an element is efficient, hopefully even O(1).
Now, what data structure should you use?
On-line resources
At a time like this it is good advice to double check with books and/or on-line
resources to verify that your initial hunch was correct. In this situation maybe
you recollect that vectors are generally fast for accessing an item but can
be slow in modifying operators since items not at the end that are inserted/removed
will cause part of the contents in the array to be shifted. Of course you also
know that an
insertion when the vector is full will trigger a re-size. A new array storage
will be created and all the items in the vector will be copied or moved to the
new storage. This seems intuitively slow.
A linked list on the other hand might have slow O(n) access to the item but the
insertion/removal is basically just switching of pointers so this O(1) operations
are very much appealing. I double check with a few different online resources
and make my decision. Linked-list it is…
BEEEEEEEEP. ERROR. A RED GNOME JUMPS DOWN IN FRONT OF ME AND FLAGS ME DOWN.
HE
TELLS ME IN NO UNCERTAIN WAYS THAT I AM WRONG. DEAD WRONG
.
Wrong? How can this be wrong? This is what
the online resources say:
www.cplusplus.com/reference/stl/list Regarding std::list[...]
Compared to other base standard sequence containers (vector
and deque), lists perform generally
better in inserting, extracting and moving elements in any position within the
container, and therefore also in algorithms that make intensive use of these,
like sorting algorithms.
www.cplusplus.com/reference/stl/vector
Regarding std::vector[...] vectors are generally the most efficient
in time for accessing elements and to add or remove elements from the end of
the sequence. [...] For operations that involve inserting or removing elements
at positions
other than the end, they perform worse than
deques and
lists.
http://en.wikipedia.org/wiki/Sequence_container_(C%2B%2B)#List
Vectors are inefficient at removing or inserting elements
other than at the end. Such operations have O(n) (see
Big-O notation) complexity compared with O(1) for linked-lists. This is
offset by the
speed of access — access to a random element in a vector is of complexity O(1)
compared with O(n) for general linked-lists and O(log n) for link-trees.
In this example most insertions/removals will definitely not be at the end, this
is already established. So that should mean that the linked-list
would be more effective than the vector, right? I decide to double check with
Wikipedia,
Wiki.Answers and
Wikibooks on Algorithms. They all seem to agree and I cannot understand what
the RED GNOME is complaining about.
I take a break to watch
Bjarne Stroustrup’s Going Native 2012 keynote. At time 01:44 in the video-cast
and slide 43, something interesting happens. I recognize what the RED GNOME
has tried to to tell me. It all falls into place. Of course. I should have known.
Duh. Locality of Reference.
Important Stuff comes now
- It does not matter that the linked-list is faster than vector for inserting/removing
an element. In the slightly larger scope that is completely irrelevant.
Before the element can be inserted/removed the right location must be
found.
And finding that location is extremely slow compared to a vector. In fact, if
both linear search is done for vector and for linked-list, then the linear search
for vector completely, utterly and with no-contest beats the list.
- The extra shuffling, copying overhead on the vector is time-wise cheap.
It is dirt cheap and can be completely ignored if compared to the huge overhead
for traversing a linked-list.
Why? you may ask?
Why is the linear search so
extremely efficient for vector compared to the supposedly oh-so-slow linked-list
linear search? Is not O(n) for linked-list comparable to O(n) for
vector?
In a perfect world perhaps, but in reality it is NOT! It is
here that
Wiki.Answers
and the other online resources are wrong! as the advice from them seem to suggest
to use the linked-list whenever non-end insertion/removals are common. This is
bad advice as they completely seem to disregard the impact of
locality
of reference.
Locality of Reference I
The linked-list have items in disjoint areas of memory. To traverse
the list the cache lines cannot be utilized effectively. One could say that the
linked-list is cache line hostile,
or that the linked-list maximizes cache line misses. The disjoint memory will make
traversing of the linked-list slow because RAM fetching will be used extensively.
A vector on the other hand is all about having data in adjacent memory. An insertion
or removal of an item might mean that data must be shuffled, but this is cheap for
the vector. Dirt cheap
(yes I like that term).
The vector, with its adjacent memory layout maximizes cache
utilization and minimizes cache line misses. This makes the whole difference,
and that difference is huge as I will show you soon.
Let us test this by doing insertions of random integer values. We will keep the
data structure sorted and to get to the right position we will use linear search
for both vector and the linked-list. Of course this is silly to do for
the vector but I want to show how effective the adjacent memory vector is compared
to the disjoint memory linked-list.
The Code
template <typename Container>
void linearInsertion(const NumbersInVector &randoms, Container &container)
{
std::for_each(randoms.begin(), randoms.end(),
[&](const Number &n)
{
auto itr = container.begin();
for (; itr!= container.end(); ++itr)
{
if ((*itr) >= n) { break; }
}
container.insert(itr, n); });
}
template <typename Container>
TimeValue linearInsertPerformance(const NumbersInVector &randoms, Container &container)
{
g2::StopWatch watch;
linearInsertion(std::cref(randoms), container);
auto time = watch.elapsedMs().count();
return time;
}
The time tracking (StopWatch
that I wrote about
here) is easy with C++11... Now all that is needed is the creation of the
random values and keeping track of the measured time for a few sets of random numbers.
We measure this from short sets of 10 numbers all the way up to 500,000. This will
give a nice perspective
void listVsVectorLinearPerformance(size_t nbr_of_randoms)
{
std::uniform_int_distribution distribution(0, nbr_of_randoms);
std::mt19937 engine((unsigned int)time(0)); auto generator = std::bind(distribution, engine);
NumbersInVector values(nbr_of_randoms);
std::for_each(values.begin(), values.end(), [&](Number &n)
{ n = generator();});
NumbersInList list;
TimeValue list_time = linearInsertPerformance(values, list);
NumbersInVector vector;
TimeValue vector_time = linearInsertPerformance(values, vector);
std::cout << list_time << ", " << vector_time << std::endl;
}
Calling this for values going all the way up to 500,000 gives us enough values
to plot them in a graph and which shows exactly what
Bjarne Stroustrup told us at the Going Native 2012. For removal of items we
get a similar curve but that is not as time intensive. I have
google doc collected some timing results that I made on IdeOne.com and
on a x64 Windows7 and Ubuntu Linux laptop for you to see.
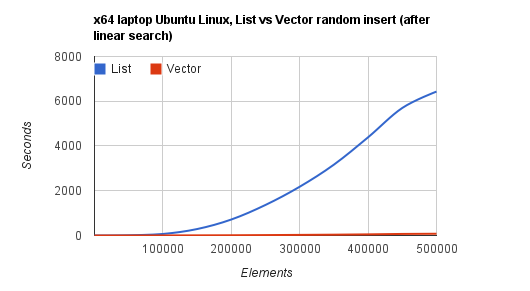
So 500,000 sorted insertions in a linked-list took some 1 hour and 47 minutes.
The same number of elements for the vector takes 1 minute and 18 seconds. You can
test this yourself. The code is attached with this article and available at the
pastebin and online compiler IdeOne: http://ideone.com/pi2Od
Locality of Reference II
The
processor
and cache architecture has a lot of influence on the result obviously. On a
Linux OS the cache level information can be retrieved by '
grep . /sys/devices/system/cpu/cpu*/index*/cache
On my x64 quad-core laptop that gives each core-pair 2x L1 cache a 32 KBytes,
2x L2 cache a 256 KBytes. All cores share a 3 MBytes L3 cache.

Conceptual drawing of quad core Intel i5
I thought it would be interesting to compare my quad-core against
a simpler and older computer. Using the
CPU-Z freeware
software I got from my old dual-core Windows7 PC that it has 2xL1 caches a 32KBytes
and 1xL2 cache a 2048 KBytes. Testing both with a smaller sets of values shows
the cache significance clearly (disregarding different bus bandwidth and CPU
Speed )
x86 old dual-core PC
Devil's Advocate I
The example above is of course somewhat extreme. This integer example brings
out another bad quality of linked-list. The linked-list need 3 * size of integer
to represent one item when the vector only need 1. So for small data types it makes
even less sense to use a linked-list. For
larger types you would see the same behavior as shown above but obviously the times
would differ. With larger types that are more expensive to copy the vector
would loose a little performance,. but likely outperform the linked-list similar
to what I described above.
Another objection to the testing as shown above is that they
are of
too large sets for a linked-list. The point is even for smaller numbers the vector
will generally perform almost as good or better than the linked-list. Then in time
the code will change and as your container is expanded it will
fare better if it is a vector than if it is a linked-list.
Wikipedia being the great source of information of it is I should also point
out that it of course also
compares linked-list to vector (i.e. dynamic array). You can read of it
here for more detailed pro’s and cons.
Devil's Advocate II : Algorithms with merge, sort
Yes, what about it? The online resources pointed out earlier are stating that
merge rand sort of the containers is where the linked-list will outperform the vector.
I am sorry to say but this is not the case for a computer with a modern cache architecture.
Once again these resources are giving you bad advice.
From a mathematical perspective YES it does makes sense when calculating big
O complexity. The problem is that the mathematical model (at least the ones I have
seen) are flawed. Computer cache, RAM, memory architecture are completely disregarded
and only the mathematical, SIMPLE, complexity is regarded.
To show this some simple sort testing is layed out below.
void listVsVectorSort(size_t nbr_of_randoms)
{
std::uniform_int_distribution<int> distribution(0, nbr_of_randoms);
std::mt19937 engine((unsigned int)time(0)); auto generator = std::bind(distribution, engine);
NumbersInVector vector(nbr_of_randoms);
NumbersInList list;
std::for_each(vector.begin(), vector.end(), [&](Number& n)
{ n = generator(); list.push_back(n); } );
TimeValue list_time;
{ g2::StopWatch watch;
list.sort();
list_time = watch.elapsedUs().count();
}
TimeValue vector_time;
{ g2::StopWatch watch;
std::sort(vector.begin(), vector.end());
vector_time = watch.elapsedUs().count();
}
std::cout << nbr_of_randoms << "\t\t, " << list_time << "\t\t, " << vector_time << std::endl;
}
The sort testing I made is available on the
google spreadsheet on tab “sort comparison“. I used std::sort
(vector) vs std::list::sort. This might be a leap of faith since this assume that
both sortings are at their best and that is where the linked-list (supposedly) was
the winner (not).
The std::sort (vector) beats the std::list::sort hands-down. The complete code is
attached and available here http://ideone.com/tLUeK
.
The testing above for sort was not repeated for merge,.
but for merge of two sorted structures, that after the merge should still be sorted,
then that involves traversal again and once again the linked-list is no good.
What to do now?
Donald Knuth made the
following
statement regarding optimization:
“We should forget about small
efficiencies, say about 97% of the time: premature optimization is the root of all
evil” .
Meaning that “Premature Optimization” is when the software developer
thinks he is doing performance improvements to the code without knowing for a fact
that it is needed or that it will greatly improve performance. The changes made
leads to a design that is not as clean as before, incorrect or hard to read. The
code is overly complicated or obfuscated. This is clearly an anti-pattern.
On the other hand we have the inverse of the extreme Premature Optimization
anti-pattern, this is called Premature Pessimization.
Premature pessimization is when the programmer chose techniques that are known
to have worse performance than other set of techniques. Usually this is done out
of
habit or just because.
Example 1: Always copy arguments instead of using const reference.
Example 2: Using the post increment ++ operator instead of pre increment ++.
I.e value++ instead of ++value.
For incrementing native types pre- or post-increment is of little difference
but for class types the performance difference can have an impact. So using value++
always is a bad habit that when used for another set of types actually is degrading
performance. For this reason
it is always better to just do pre increments. The code is just as clear
as post increments and performance will always be better (albeit
usually only a little better).
Using linked-list in a scenario when it has little performance benefit (say
10 elements only touched rarely) is still worse compared to using the vector.
It is a bad habit that you should just stay away from.
Why use a bad performance container when other options are available? Options
that are just as clean and easy to work with and have no impact on code clarity.
Stay away from Premature Optimization but be sure to not fall
into the trap of Premature Pessimization! You should follow the best (optimal)
solution, and, of course, common sense
without
trying to optimize and obfuscate the code and design. Sub-optimal techniques such
as linked-list should be avoided since there are clearly better alternatives out
there.
C++ only?
Of course this could be true for other languages and containers as well. I leave
it as a fun test for whomever feel challenged to test for for C#
(List<T> vs LinkedList<T>) .... [ Java, Python
...?]
Disclaimer & Conclusion
Contrary to what you might believe when reading this I am no fanatical no-linked-list
ever type radical on the subject. In fact I can come up with
examples where linked-list would fit in nicely.
However these examples are rare - maybe you can point some out for me?
Until then, why do not we all just stay away from the linked-list
for the time being? After all C++ is all about performance - and linked-list is
not!
Last, a little plea. Please, before I get flamed to pieces for this obstinate
article, why not run some sample code on ideone.com or similar, prove me wrong and
educate me. I live to learn =)
Oh, and yes. I know, thank you for
pointing it out. There are other containers out there, but this time I focused on
Linked-list vs Vector
History
Enjoying Colorado! Family and intense software development.
Kjell is a driven developer with a passion for software development. His focus is on coding, boosting software development, improving development efficiency and turning bad projects into good projects.
Kjell was twice national champion in WUKO and semi-contact Karate and now he focuses his kime towards software engineering, everyday challenges and moose hunting while not being (almost constantly) amazed by his daughter and sons.





