Introduction
The purpose of this tip is to show how images can be extracted from an Office document which is saved using Office Open XML format, for example extensions xlsx, wordx and pptx.
The example project lets a user select an Office file, lists the images found in a grid and when an image is selected, a preview is shown.
The user interface looks like this:
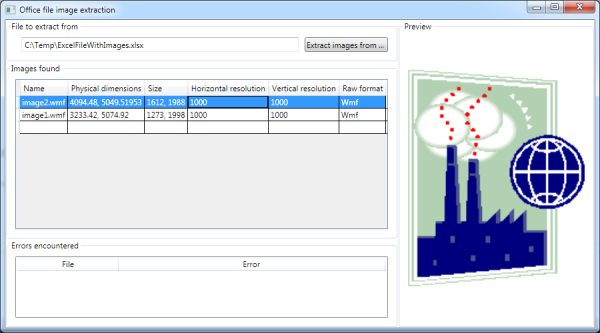
Image Extraction
The image extraction is actually quite simple since the Office documents are basically just zipped XML files in a directory structure. Of course, there is binary content in some of the compressed files and so on, but the images are located separately in a specific media folder. The location of the media folder depends on the document type, like this:
- Excel workbook:
/xl/media - Word document:
/word/media - Powerpoint presentation:
/ppt/media
So the idea in the program is simple, uncompress the archive and get the images from the folder one-by-one.
Let's have a look at some code.
public static ExtractResult ExtractImages() {
ExtractResult result = new ExtractResult();
System.Drawing.Image image;
System.IO.Compression.ZipArchive documentArchive;
string mediaPath;
string fileExtension;
Microsoft.Win32.OpenFileDialog openDialog = new Microsoft.Win32.OpenFileDialog();
openDialog.Multiselect = false;
openDialog.Title = "Select an Office file";
openDialog.Filter = "All office documents|*.xlsx;*.docx;*.pptx|Excel Workbooks
(*.xlsx)|*.xlsx|Word Documents (*.docx)|*.docx|Powerpoint Presentations (*.pptx)|*.pptx";
if (openDialog.ShowDialog().Value) {
result.File = openDialog.FileName;
fileExtension = openDialog.FileName.Substring(openDialog.FileName.LastIndexOf('.') + 1).ToLower();
switch (fileExtension) {
case "xlsx":
mediaPath = "xl/media/";
break;
case "docx":
mediaPath = "word/media/";
break;
case "pptx":
mediaPath = "ppt/media/";
break;
default:
throw new System.ArgumentException
(string.Format("Unknown Office file type: {0}", fileExtension));
}
try {
using (documentArchive = new System.IO.Compression.ZipArchive(openDialog.OpenFile())) {
foreach (System.IO.Compression.ZipArchiveEntry entry in documentArchive.Entries) {
if (entry.FullName.StartsWith(mediaPath)) {
try {
image = System.Drawing.Image.FromStream(entry.Open());
result.ImageItems.Add(
new ImageItem() {
Name = entry.Name,
Image = image
});
} catch (System.Exception exception) {
result.Errors.Add(
new ExtractError() {
File = entry.Name,
Error = exception.Message
});
}
}
}
}
} catch (System.Exception exception) {
System.Windows.MessageBox.Show(exception.Message, "Error opening the Office document",
System.Windows.MessageBoxButton.OK, System.Windows.MessageBoxImage.Stop);
}
}
return result;
}
As you can see, the program first asks for the document to extract images from and then decides the path to the media folder based on the file type.
After that, the archive is opened and each file (entry) inside the archive is investigated. If the path for an entry inside the archive is pointing to the media path, then the image is read from the archive entry.
Of course, not all of the media can be read into an image so in case of an exception, the information about the error and the file is gathered to be shown in the user interface.
After all the entries have been investigated, the result is returned. Note that I'm using separate classes for images, errors and the overall result. The definitions are as follows:
public class ExtractResult {
public string File { get; set; }
public System.Collections.Generic.List<ImageItem> ImageItems { get; private set; }
public System.Collections.Generic.List<ExtractError> Errors { get; private set; }
public ExtractResult() {
this.ImageItems = new System.Collections.Generic.List<ImageItem>();
this.Errors = new System.Collections.Generic.List<ExtractError>();
}
}
public class ExtractError {
public string File { get; set; }
public string Error { get; set; }
}
public class ImageItem {
public string Name { get; set; }
public System.Drawing.Image Image { get; set; }
}
Presentation
The other half of the program is the user interface. As shown in the beginning of the tip, it's quite simple but there are few things to have a look at.
When the images are extracted, the collections are bound to corresponding controls.
result = Extractor.ExtractImages();
if (!string.IsNullOrEmpty(result.File)) {
this.nameOfTheFile.Text = result.File;
this.errorList.ItemsSource = result.Errors;
this.imageGrid.ItemsSource = result.ImageItems;
this.imageViewer.Source = null;
}
The event SelectionChanged in the DataGrid is wired in order to show the preview of the image whenever the selection changes.
private void imageGrid_SelectionChanged(object sender, System.Windows.Controls.SelectionChangedEventArgs e) {
Extractor.ImageItem image;
System.IO.MemoryStream imageStream;
System.Windows.Media.Imaging.BitmapImage bitmap;
if (e.AddedItems != null && e.AddedItems.Count > 0) {
image = e.AddedItems[0] as Extractor.ImageItem;
if (image != null) {
imageStream = new System.IO.MemoryStream();
bitmap = new System.Windows.Media.Imaging.BitmapImage();
this.imageViewer.Source = null;
image.Image.Save(imageStream, System.Drawing.Imaging.ImageFormat.Png);
imageStream.Position = 0;
bitmap.BeginInit();
bitmap.StreamSource = imageStream;
bitmap.EndInit();
this.imageViewer.Source = bitmap;
}
}
}
The trick in showing the preview is that the Image object needs to be converted to an object derived from ImageSource, such as BitmapImage. In the code above, that is done by saving the image in PNG format into a memory stream and the bitmap image is then read from the stream. This bitmap image can now be used as a source for the Image control.
You can find all the source code from inside the downloadable project.
History

