Introduction
I have been working as a senior software engineer for more than 7 years and have worked on several domains in IT companies in different roles. I worked with many developers, some of whom have good hands on SQL or others who don't. But most of the time, one thing which is common in both sort of developers is while writing a query, they sometimes ignore the performance aspect. I think we should bear in mind the performance as well at the same time addition to get accurate results.
There are too many things which raise the performance of our queries. But I am describing some of them which are generally used.
1. Query Should Be Well Formed (First)
I saw many SQL queries, functions, stored procedures, etc. But most developers wrote queries which are not in good format (Yeah, nobody has the intentions to do so). I am one of them who does the same thing, so I preferred using tools to format the query.
There are numerous tools or online SQL query formatter providers available, I prefer to use poorSQL tool. It also provides the plug-ins for SQL.
Before using formatter:
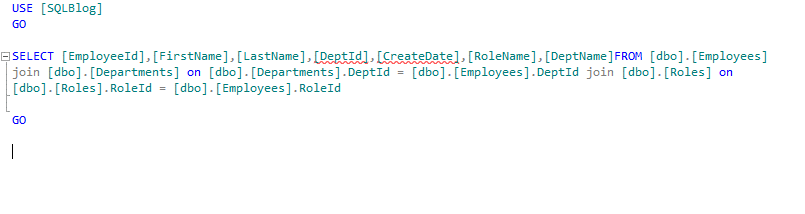
The code is not readable, in a single shot of view, it’s really hard to check the join and other related information that what’s going on in the query.
After using formatter:

Now, the code is more readable and everyone can understand the joins between the tables and what would be the outcome of this query.
2. Avoid Using ‘SELECT *’ In Your Query
In my personal experience, nobody wants to write a lengthy code or query. Everyone wants shortcuts to complete the job/task. ‘SELECT *’ is doing the same thing in a perfect manner. But there is some performance issue when we are working on a large scale of data because ‘*’ returns all the columns of all the tables when we executing the query and returns all the columns using network bandwidth.
So, we should be using only required columns in the select list instead of using ‘SELECT *’.
Like below:
3. Avoid Using Table Name When Query Has More Than One Table
If more than one table is involved in a ‘FROM’ clause, each column name must be qualified using either the complete table name or an alias. The alias should be preferred. It is more human readable to use aliases instead of writing columns with no table information.
Like below:
4. Avoid Using ‘IN’ When Multiple Filter Criteria
Usually ‘IN’ has slower performance as compared to ‘EXISTS’. Basically ‘IN’ is efficient when most of the filter criteria is in the sub-query and EXISTS is efficient when most of the filter criteria is in the main query.
Below example using (IN):
Below example using (EXISTS):
Because, EXISTS will be faster because once the engine has found a hit, it will quit looking as the condition has proved true.
With IN, it will collect all the results from the sub-query before further processing.
5. Avoid Using 'DISTINCT' When Needed Unique Column Values
Use EXISTS instead of DISTINCT when using joins which involves tables having one-to-many relationship.
Below example using (DISTINCT):
Below example using (EXISTS):
EXISTS will be faster because once the engine has found a hit, it will be looking as the condition is true. On the contrary, DISTINCT will collect all the results from before further processing.
6. Avoid Using 'OR' When Needed Multiple Condition in the Same Column
I have found most of the time, OR is less efficient compared to UNION. Let’s see by following the examples below:
Using (OR) with 2 conditions in the same column:
Using (UNION) with 2 conditions in the same column:
Conclusion
UNION causes more seeks instead of scans because each operation needs to meet selectivity requirement. OR’s in a single operation so when the selectivity for each column is combined and it goes over a certain percentage, then a scan is deemed more efficient.
Since a UNION by default performs a separate operation for each statement, the selectivity of each column is not combined giving it a greater chance of performing seek. Now since the UNION performs two operations, they need to match their result sets using a concatenation operation above. Generally, this is not an expensive operation.
7. Avoid Using Maximum Sub-query in Your Main Query
Sometimes, we have to build the query with the help of some sub-queries in it. But, we should try to minimize the use of subqueries as much as we can. There are other ways to avoid subquery using CTE. Subquery execute for each record and it will impact the performance of your query.
Using 2 subqueries:
Using group by and having to avoiding the subqueries:
8. Avoid Using 'COUNT' When We Need to Check the Existence of a Particular Data
Most of us might have sometimes used COUNT to determine whether a particular data exists or not. Please see the example below:
EXISTS will be faster because once the engine has found the particular text/value, it will quit looking as the condition has proved true. Whereas the COUNT(1) does read each and every row in the entire table to determine if they match the criteria and how many records are there. That is the key, folks.
Points of Interest
I wrote my first article on Code Project. In my next post, you shall find more about database performance topics in a deeper way.

