Introduction
Semantic Versioning (SemVer) is a specification that provides guidance for developers to help manage API-level dependencies between components. Unfortunately, most developers create line-of-business applications without APIs, and that means SemVer doesn't exactly provide much semantics (i.e. meaning) to consumers of the application.
Fortunately, it's pretty easy to create meaningful version numbers that everyone - developers, testers, operations, managers, and even end-users - will find helpful.
When talking about version numbers, it's important to first differentiate between a release and a build. The difference isn’t always that obvious, especially in corporate IT and other custom software shops.
Simply put, a release is merely requirements; i.e., a set of planned changes to a particular application. A build, on the other hand, is an attempt at fulfilling a release’s requirements; the build is what actually gets pushed through dev, staging, and production.
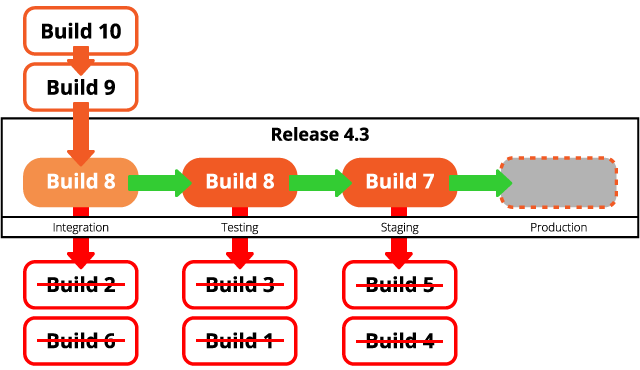
Though seemingly subtle, it’s an important distinction, not unlike that of classes and interfaces, and virtual and abstract methods. When you combine the concepts of build and release into one, you’re faced with unnecessary challenges in figuring who’s working on what, and where things are.
Of course, before being able to distinguish one release from the next, you have to be able to uniquely identify your releases. Referring to your releases (i.e., your planned sets of changes) as “staging” or “next Tuesday” is obviously sub-optimal.
Picking a Release Numbering Scheme
The two most important aspects of release identification are usage and scalability.
If the target audience of the release number (whether that’s end-users or project stakeholders) can’t differentiate between one release and the next, then that defeats the entire purpose of identification. As an example, a scheme where the release number asymptotically approaches π (such as the one TeX uses) would frustrate many non-technical users who don’t appreciate the difference between 3.141592 and 3.1415926.
On the same note, if a release identification system can’t scale, it’s equally as useless. An obviously silly example would be naming releases after Snow White’s seven dwarfs, but a more practical one might be identifying a release by only the month and year. It’s rather sub-optimal when users need to ask “which July 2010 release are you referring to?”
While virtually anything from colors of the rainbow to baroque compositions can be used to identify releases, numbers are the most appropriate. They have a natural ordering (3 always precedes 7) are universally understood.
There are five generally-recognized numbering schemes. No single one is the “correct” one to use, as “usage” and “scalability” will determine appropriateness.
| Major/Minor | Most end-users have become accustomed to this, as seemingly everything nowadays (software and non-software) is identified with a something-dot-something number; for the most part, this is the most appropriate choice for in-house/custom applications. |
| Major/Minor/Revision | Useful if you need “behind the scenes” (i.e., not transparent to end-users or product managers) releases to fix bugs; a must-have for product companies, but often confusing for in-house development.
Note that SemVer is well-defined version of this scheme: Revision is replaced by Patch, modifying it to Major/Minor/Patch. |
| Sequential | Perhaps the easiest to work with, this scheme involves simply incrementing an integer for every release; the main downside is the inability to plan for far-out versions (e.g. 3.0, 4.0) while still working on current versions (e.g. 1.8, 2.3), which generally isn’t a problem for extremely simple applications like a static website. |
| Date-based | Based on the target release date, such as 2010Q4; while seemingly convenient, this scheme can be confusing when Release 2011-Jan is delayed until March; for relatively infrequent and rigid release schedules (monthly, quarterly), this is an appropriate choice. |
| Free-form | Everything else; obviously the least-desirable scheme, as there’s no consistency and few people will inherently understand it. |
As for deciding what’s a major release and what’s minor… that’s always arbitrary. And besides, as Microsoft has shown us with .NET 2.0/3.0/3.5 and Windows 7/8/10, it’s often a decision that gets left to marketing anyway.
Build vs Release vs Version Numbers
Once you've separated the concepts of builds and releases, you can see that a build identifier is really only needed in the pre-production phases as a means of differentiating one build from the next. Once a single build is shipped to production, the rejected builds are merely historic artifacts, and the release number is all that's needed to describe the released version of the application.
In the same way that release numbers need to be only unique within an application, build numbers need only be unique within a release. The easiest and simplest way to do this is an auto-incrementing integer that starts at "1" for each new release, similar to the sequential release numbering scheme, but it can be any value.
The factors are much less nuanced for build numbers, and the most important criteria is communication between members of the development organization (developers, testers, etc.), and using a really long number (or a LongGuid) is rather impractical.
So where do version numbers fit into all of this? It's whatever combination of Application Name, Release Number, and Build Number that will communicate the most relevant information to the relevant party in a given context with a single, short string. And in most cases, you can accomplish this by simply sharing the Release Number.
For an indepth description of releases within BuildMaster, check out our BuildMaster Release Documentation.

