Introduction
Big Data is too big and complex to manage in the traditional solutions such as the relational databases using Windows SQL Server or Mysql, etc.
That is why Hadoop has been a very convenient solution for those who want to process huge amount of data to help them make the right business desicion. Hadoop is an Apache open source project for distributed data processing. Working with hadoop can be complex especially when caring about the storage, the computing, the total nodes used and how to ensure communication between them in order to process the data quickly. However, Microsoft offers Hadoop solution called HDInsight that make the work easier and let big data workers gain time and think deeper about their business.
In this tip, we are going to run the traditional word count example.
Using the Code
First of all, connect to Microsoft Azure to start the work. Select the HDInsight server and click on New Button on specifying the name of HDInsight Cluster, Admin's password and name of the storage account as the picture below:
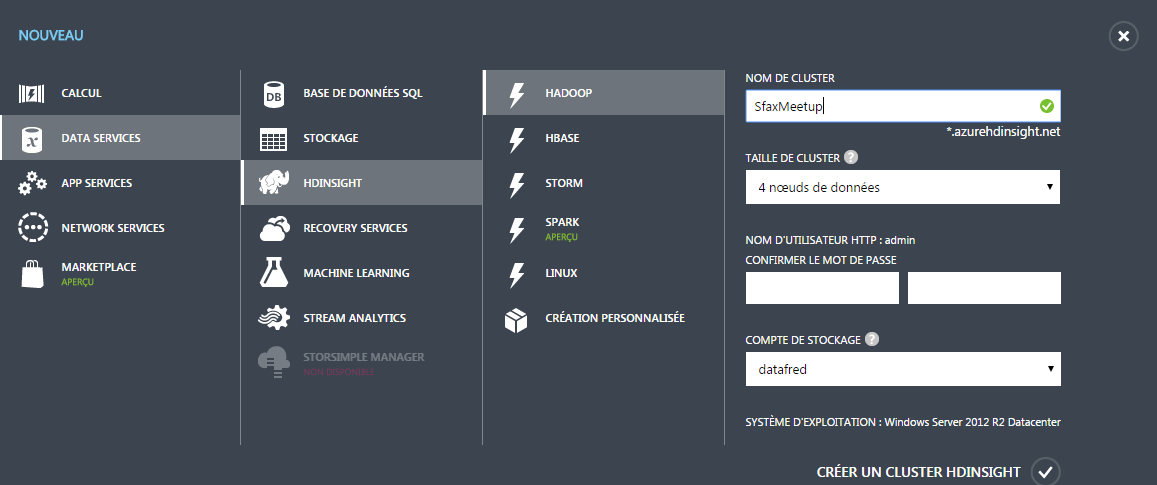
Once the cluster is created, access it and choose Configuration option. Click on Distant Activate and specify the user name and password.

Click on connect to download the Remote Desktop Protocol example. Click on it and specify the user and the password.
Now you are in the Hadoop cluster Virtual Machine. We will work with the Hadoop Comand line as below:
Click on it. We can see the HDFS (Hyper distributed File System: the Hadoop storage where the processing can be done) using this command:
hadoop fs -ls /
To work with hadoop, we use hadoop coomand and fs is related to File System and the hyphen used to specify the Unix Command. We can see the following results:
What we want to do is to count the number of each word in the textfile provided as template in the hdfs as follows: /example/data/gutenberg/davinci/txt.
That is why we have to process it using the map reducer to make this quicker. Mapper is used to divide the textfile into pieces where we will make the word count and the reducer with count all the results provided by the mapper.
In order to let it happen, run the following comand line:
hadoop jar hadoop-mapreduce-examples.jar wordcount /example/data/gutenberg/davinci.txt example/results
In the example above, we are calling the hadoop-mapreduce-example Java file and we are specifying the input which is the textfile and the output which is the path of the results directory:
In order to see the results, we have to run the following comand line:
hadoop fs -cat /example/results/part-r-00000
Finally, we can see the results as below:

