Introduction
We know that PDF files store their data in a tree structure. So retrieving data from PDFs should be an easy process. But it is not, like Tables when they are untagged. Untagged (not marked content) Table extraction from PDF is uncommon and almost impossible, therefore some online tools and software like docParser, ABBYY FineReader, Tabula, etc. offer you this extraction facility but they are not free and reliable.
Requirements or dependencies: iText.kernel.dll, itext.oi.dll, BouncyCastle.Crypto.dll, Common.Logging.Core.dll, Common.Logging.dll --> all are included in packages folder of the zip project.
** iText is a opensource tools. For this project, I have modified the iText.kernel library. So the original iText.Kernel will not work here. To run, please add the reference of my modified iText.kernel.dll.
** To run this project, Visual Studio 2015 or above is needed.
Background
iText, iTextSharpe are very popular and opensource tools for read, write, parse and other various kind of PDF manipulations and operations. In this project, iText is used. So if you are in a situation like that, you have to extract untagged table data from PDF files. This article may help you to understand why it is complex and shows a simple way to do that with the help of iText.
* This article cover tables which have borders.
PDF file Structure: Four main parts of PDF files are:
- Header- Contains PDF file signature
- Body – Direct/indirect objects
- Cross-reference Table - Map the objects to find them
- Trailer- Has information about Cross-reference Table size, Root object(/Catalog), encryption information
Basic data types:
- boolean
- number
- string
- name
- array
- dictionary
- stream
null
Here, I am not going to discuss details about PDF file structures, rather we focus on our specific problem.
From PDF data types, we see that there is nothing like table, cell, row or column. So how does a table data store in a PDF. It is simple just Text(stream/string) and path. Path is not a data type but most PDF parsers parse data from PDF in text, path, image, glyphs form. So in PDF files, a table is nothing but some pieces of lines, rectangles, text or shape. Let us see a simple PDF with a table and its corresponding internal structure.
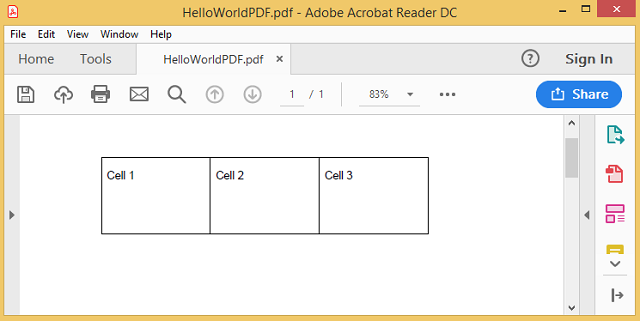

From the above pictures, we see a PDF file and its code behind. In the real world, you can’t see code behind like this rather than some bunch of compressed unreadable stream. For better understanding, we will deal here with readable and much understable code behind. From the code behind, we see that there is no table, cell or row, rather than there are some line draw code and text render code instructions.
Text Render Code
BT /F1 10 Tf 80 700 Td (Cell 1)Tj ET
BT /F1 10 Tf 180 700 Td (Cell 2)Tj ET
BT /F1 10 Tf 280 700 Td (Cell 3)Tj ET
Line Draw Code
75 720 m 375 720 l 375 650 l 75 650 l h S
175 720 m 175 650 l 275 720 m 275 650 l S
Here, some instructions meaning: BT- Begin Text, ET- End Text, m- MoveTo, l- LineTo S- Stroke
Table is saved in PDF just some piece of line and text. Now we are quite clear why it is hard to retrieve table data from PDF. Now what we can do is retrieve data by its location. In this article, I will just show retrieving table data with border. Table without border extraction will be covered in my next article or in the next part of this article.
Using the Code
Add the required DLL references, add FilterTableEventListener.cs to your project or add TableExtractionFromPDFDLL.dll to your project. The following example reads a PDF file, parses a certain PDF page and extracts the table/tables (with full border) from the page into Dataset.
using iText.Kernel.Pdf;
using TableExtractionFromPDFDLL;
static void Main(string[] args)
{
PdfReader reader = new PdfReader(@"your pdf file path\TableTest01.pdf");
PdfDocument document = new PdfDocument(reader);
PdfPage page = document.GetPage(1);
FilterTableEventListener renderListener = new FilterTableEventListener(page, true);
System.Data.DataSet ds = renderListener.GetTables();
System.Data.DataSet[] dsList = new System.Data.DataSet[document.GetNumberOfPages()];
int startPage = 1, index = 0;
int endPage = 9 < document.GetNumberOfPages() ? 9 : document.GetNumberOfPages();
for (int i = startPage; i <= endPage; i++)
{
PdfPage temPage = document.GetPage(i);
renderListener = new FilterTableEventListener(temPage, true);
dsList[index++] = renderListener.GetTables();
}
document.Close();
reader.Close();
}
Here, FilterTableEventListener has two arguments. The first one is the page where to extract table, the second one is a Boolean value that indicates whether table has borders or not.
Points of Interest
A table with the same data and cell can store differently in PDFs. By studying various PDF files, it is observed that a line can render in PDF by LineTo(l) command and also by Rectangle(re) command. That means that a line is saved in PDF as rectangle with very tiny width (vertical line) or very tiny height (horizontal line).
Same data of PDF can store many different ways in PDF. Same Text, same shape / structure or path can store different ways. That’s why table extraction from PDF mainly depends on location / position extraction and parsing data and object based on location/position.
This project, mainly parses the table border as path to map the table position and its cells position, discards the other paths rather than table border, extracts the cell data by border position.
Discussion about iText.kernel Modification
Some new features added to iText.kernel.dll. Following list of files are modified:
** For readers help and some request modified iText.kernel development code have added to itext.kernel.zip attachment.
History
- 11th October, 2018: Initial version

