Abstract
The following is an introduction to Java Matrix Benchmark (JMatBench) with a few results from the latest update. JMatBench compares different linear algebra libraries that process dense real matrices written in Java for speed, stability and memory usage. First an introduction to the problem being addressed is provided, followed by a description for how the results are computed and displayed, and finally some more results.
For a complete set of results across different architectures, visit the project webpage at http://lessthanoptimal.github.io/Java-Matrix-Benchmark/.
Introduction
Java has an active community of developers creating tools for scientific computing, which includes linear algebra. Linear algebra is the study of solving systems of linear equations. Linear algebra provides the fundamental building blocks for several other problems such as optimization, model fitting, and filtering. It has applications to a wide range of fields that include machine learning, aerospace engineering, finance, computer vision, and many more.
To represent these systems of linear equations, matrix notation is used. A dense matrix explicitly stores every element in the matrix, while a sparse matrix only stores elements which are not zero. In some specialized problems, sparse matrices can provide significant gains in performance, but dense matrices are applicable to all linear algebra problems. In this article, only dense real matrices are considered.
While there are many tools available in Java for solving these systems, which ones should be used? Perhaps the most popular and well known is Jama, however Jama has not been maintained since 2005. To help answer that question and provide developers with motivation to continue to improve their libraries, Java Matrix Benchmark (JMatBench) was developed at the end of 2009.
JMatBench evaluates the runtime performance, stability, and memory usage of each library. The primary developer of JMatBench is Peter Abeles (also developer of EJML), but it has been improved through discussions with other library authors, such has Anders Peterson (ojAlgo) and Holger Arndt (UJMP). The most recent results from March 2012 evaluated the performance of the following libraries:
Most of these libraries are written entirely in Java. The one exception is jBlas which invokes native code to provide superior performance on larger matrices.
Measuring Runtime Performance
Throughout the history of linear algebra, the focus has been on improving the performance for large matrices. At the same time, small matrices are important for many problems as well, for example in computer vision and aerospace. To address both problems, a range of matrix sizes (2 to 10,000) are evaluated and displayed in a relative runtime plot.
An example of a relative runtime plot is shown below. Faster libraries will have a number closer to one while slow libraries will have a number closer to zero. These numbers are computed by finding the number of operations per second that each library can perform at each matrix size. Then for each matrix size, the results are normalized by the best performing library. More traditional approaches of displaying results, such as FLOPS, scale poorly as a function of matrix size (even when log plots are used) making it difficult to see which library is performing best at which matrix size.
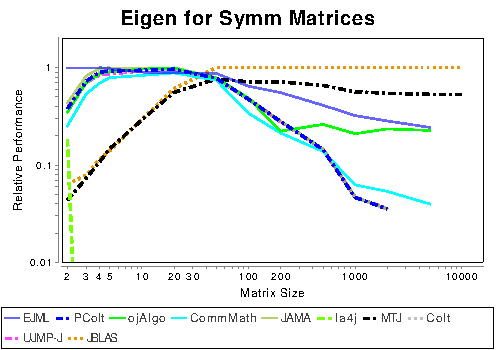
Example of a relative runtime plot.
Note how which libraries are fastest depend on matrix size. That’s because different techniques are required to optimize performance for different sized matrices. The libraries that perform best tend to switch between different algorithms depending on matrix size.
To help people see the forest through all the trees, overall results are summarized in a box and whisker plot. The overall results combine performance across all operations tested, while placing more emphasis on computationally expensive operations. In addition, results are summarized across all matrix sizes, only large matrices, and only small matrices.
Just measuring the runtime performance in Java is a tricky issue. For example, if the same operation is measured differently in the same virtual machine (VM) instance, the order in which they are processed will affect the results.
Measuring Stability
Runtime performance is what most people focus on when selecting which library to use, this is a mistake. It does not matter how fast a library is if it produces garbage results. Stability of an algorithm is the measure of how sensitive it is to small changes in input. A stable algorithm will produce a small change in output for a small change in input. In two of the primary sources of instability in linear algebra, there are nearly singular systems and numerical overflow/underflow.
To measure the stability of each library, several common operations were selected and are sent through a battery of tests. This benchmark has been shown to be particularly good at detecting bugs in a library which might not be detecting at first glance.
Measuring Memory Usage
One disadvantage of using dense matrices to solve problems is that they can use up a large amount of memory. The minimum amount of memory used by each library was found by adjusting the size of each library’s available heap using virtual machine parameters and measuring the actual memory usage using operating system calls. This approach was found to be the best and most stable after a bit of experimentation.
The same functions tested in runtime performance are tested here. In some situations, it might be possible to reduce memory usage by calling different functions. For example, if using a row-major matrix for a large matrix operation, a library might internally convert it into a block matrix to minimize cache misses. The user could reduce memory usage by working exclusively with the block matrix to begin with.
Runtime Results
Below are the summary results and a few selected relative runtime results for a CoreI7 computer. In both the summary box and whisker plot and relative runtime plots, higher values are better. More results and different architectures can be found at the links below:

As mentioned before, this is only a small sampling of the available results. If a library is omitted from a plot, that means it did not support the operation or it failed. JBLAS is often the fastest because it is not written in 100% Java.
Stability Results
Due to formatting issues, the stability results cannot be shown on this webpage. The latest stability results can be found at the website below:
http://code.google.com/p/java-matrix-benchmark/wiki/MemoryResults_2012_02
Memory Results
Shorter bars are better. Click here for complete results.
Conclusion
Hope that this introduction to Java Matrix Benchmark was helpful. If anything is not clear, please post a comment below. As mentioned several times already, the results presented here are only a brief summary of what's available at the project webpage.

