Introduction
You have a data file with multiple columns.
You want to predict the value of one column based on the values of the other columns.
You want to find the best algorithm to do it.
Using the Code
Download the complete code example.
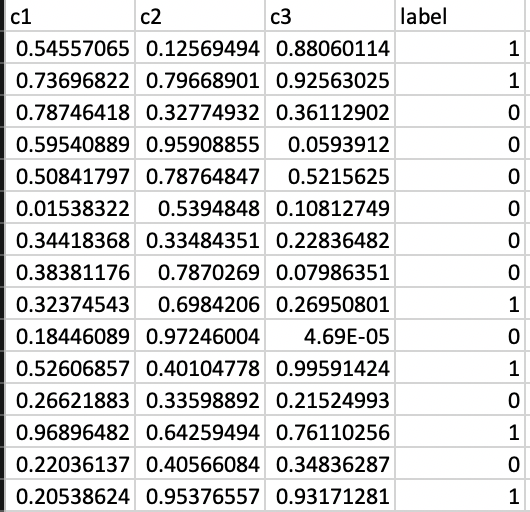
In this example, all the data is found in a CSV file - data.csv, that looks like this:
* c1,c2,c3 are continuous features between 0 and 1, we want to use them in order to predict the binary label.
Make sure you have all the required python packages:
pip install pandas
pip install sklearn
pip install json-config-expander
pip install xgboost
You can download the complete code example, or follow the instructions to understand each step.
Open a new python file, and add those imports:
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score
from sklearn.model_selection import train_test_split
from json_config_expander import expand_configs
from xgboost import XGBClassifier
import pandas as pd
Read the data:
df = pd.read_csv('data.csv')
Split it to X (the feature columns - the columns we base on) and y ( the column we want to predict):
X = df[[column for column in df.columns if column != 'label']]
y = df['label']
Split the data to train and test:
X_train_complete, X_test, y_train_complete, y_test = train_test_split(X, y, test_size=0.2)
Because we are going to tune algorithms parameters, it is a good idea to leave the test set aside for later steps and perform another split on the train set, to create a validation set. If you are not familiar with the purpose of a validation set - please read this.
X_train, X_validation, y_train,
y_validation = train_test_split(X_train_complete, y_train_complete, test_size=0.2)
Now, we are going to train the model on the train set, and evaluate it on the validation set:
results = expand_configs(BASE_CONFIG,
lambda config: evaluate_model(config, X_train, X_validation, y_train, y_validation))
In the code above, we have two missing things - BASE_CONFIG and evaluate_model function, so we need to define them. BASE_CONFIG represents all the different models we want to test, and evaluate_model is a function that returns a representation of "how well the model performed".
Define BASE_CONFIG:
BASE_CONFIG = {"classifier*": [
{
"name": "random_forest",
"parameters": {"max_depth*": [3, 5], "n_estimators*": [50, 100, 200]}
},
{
"name": "logistic_regression",
"parameters": {"max_iter*": [10, 100, 1000], "C*": [0.1, 0.5, 1]}
},
{
"name": "xgboost",
"parameters": {"max_depth*": [3, 4, 5], "n_estimators*": [50, 100, 200],
"learning_rate*": [0.01, 0.05, 0.1]}
}]
}
We are going to use three different models - Random Forest, Logistic Regression, and XGBoost. Every algorithm has its own parameters, I picked some of them in the code above, to test what works better on this data. The expand_configs code is going to run all the options there are to pick the parameters (Disclaimer - expand_configs is part of an open-source library, of which I was one of the writers).
Some mapping of the model's names to the sklearn classes:
CLASSIFIER_MAPPINGS = {"random_forest": RandomForestClassifier,
"xgboost": XGBClassifier, "logistic_regression": LogisticRegression}
Now, we need to write the evaluation function:
def evaluate_model(config, X_train, X_test, y_train, y_test):
classifier = CLASSIFIER_MAPPINGS[config["classifier"]["name"]]
(**config["classifier"]["parameters"])
classifier.fit(X_train, y_train)
test_scores = classifier.predict_proba(X_test)[:, 1]
roc_auc = roc_auc_score(y_test, test_scores)
return {"config": config, "roc_auc": roc_auc}
This function receives a model configuration, a training and test set - trains the model on the training data and evaluates it on the test set. In order to evaluate, we need to decide how we want to evaluate our model - it depends on the real problem we want to solve. More on this topic can be found here.
For the purpose of this example, I decided to use ROC-AUC to evaluate the model.
After expand_configs function runs, these are the results on all the possible combinations of parameters:

Select the best model, with the best parameters:
best_result = max(results, key=lambda res: res["roc_auc"])
And the best classifier with the best parameters is:
'classifier': {
'name': 'xgboost',
'parameters': {'max_depth': 3, 'n_estimators': 50, 'learning_rate': 0.01}
}
We got an AUC-ROC of 0.89, which is higher than any other model I ran.
Do you remember the test set we put aside before? Now we can use it to see how well the model we trained performs on it:
result_on_test = evaluate_model
(best_config, X_train_complete, X_test, y_train_complete, y_test)
We got 0.89 ROC-AUC on the validation set and 0.84 ROC-AUC on the test set. This is a common result, the selected model on validation usually performs better on the validation than on the test set.
Complete Example
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score
from sklearn.model_selection import train_test_split
from json_config_expander import expand_configs
from xgboost import XGBClassifier
import pandas as pd
CLASSIFIER_MAPPINGS = {
"random_forest": RandomForestClassifier,
"xgboost": XGBClassifier,
"logistic_regression": LogisticRegression}
BASE_CONFIG = {"classifier*": [
{
"name": "random_forest",
"parameters": {"max_depth*": [3, 5], "n_estimators*": [50, 100, 200]}
},
{
"name": "logistic_regression",
"parameters": {"max_iter*": [10, 100, 1000], "C*": [0.1, 0.5, 1]}
},
{
"name": "xgboost",
"parameters": {"max_depth*": [3, 4, 5],
"n_estimators*": [50, 100, 200], "learning_rate*": [0.01, 0.05, 0.1]}
}]
}
def evaluate_model(config, X_train, X_test, y_train, y_test):
classifier = CLASSIFIER_MAPPINGS[config["classifier"]["name"]]
(**config["classifier"]["parameters"])
classifier.fit(X_train, y_train)
test_scores = classifier.predict_proba(X_test)[:, 1]
roc_auc = roc_auc_score(y_test, test_scores)
return {"config": config, "roc_auc": roc_auc}
if __name__ == '__main__':
df = pd.read_csv('data.csv')
X = df[[column for column in df.columns if column != 'label']]
y = df['label']
X_train_complete, X_test, y_train_complete,
y_test = train_test_split(X, y, test_size=0.2)
X_train, X_validation, y_train, y_validation =
train_test_split(X_train_complete, y_train_complete, test_size=0.2)
results = expand_configs(BASE_CONFIG,
lambda config: evaluate_model
(config, X_train, X_validation, y_train, y_validation))
best_result = max(results, key=lambda res: res["roc_auc"])
best_config = best_result["config"]
result_on_test = evaluate_model
(best_config, X_train_complete, X_test, y_train_complete, y_test)
print(f"Best config: {best_config}")
print(f"ROC AUC on Validation: {best_result['roc_auc']}")
print(f"ROC AUC on Test: {result_on_test['roc_auc']}")
Points of Interest
History
- 17th January, 2020: Initial version

