This tip shows how to prevent insert for a record when a maximum number of rows has been reached.
Introduction
Sometimes, you may have a need to control how many records can be added into a table. This could be an overall limit or a limit based on some column of the table, for example, based on a foreign key.
A simplified example could be that you want to limit the number of order rows to three for an individual order.
So How?
Let's first create a simple test scenario. We need an OrderItem table like the following:
CREATE TABLE OrderItem (
OrderId INT NOT NULL PRIMARY KEY ,
Ordered DATETIME
);
And of course, an OrderRow table:
CREATE TABLE OrderRow (
OrderRowId INT NOT NULL PRIMARY KEY ,
OrderId INT NOT NULL FOREIGN KEY REFERENCES OrderItem (OrderId),
Product VARCHAR(100) NOT NULL,
Amount INT NOT NULL,
Price DECIMAL NOT NULL
);
A small disclaimer at this point: Normally, the primary keys would be an auto-incremented columns, but I've used a traditional column for the sake of simplicity in this trick.
Now we can try to add some data to the table, first the order:
INSERT INTO OrderItem (OrderId, Ordered)
VALUES (1, CURRENT_TIMESTAMP);
And then the order rows:
INSERT INTO OrderRow (OrderRowId, OrderId, Product, Amount, Price)
VALUES (1, 1, 'Product A', 1, 100);
INSERT INTO OrderRow (OrderRowId, OrderId, Product, Amount, Price)
VALUES (2, 1, 'Product B', 1, 200);
INSERT INTO OrderRow (OrderRowId, OrderId, Product, Amount, Price)
VALUES (3, 1, 'Product C', 1, 300);
INSERT INTO OrderRow (OrderRowId, OrderId, Product, Amount, Price)
VALUES (4, 1, 'Product D', 1, 400);
INSERT INTO OrderRow (OrderRowId, OrderId, Product, Amount, Price)
VALUES (5, 1, 'Product E', 1, 500);
If you test this, everything works smoothly and five rows are inserted into OrderRow table. So how to limit the amount of rows?
Perhaps the easiest way is to define a trigger for the table. The purpose of the trigger is to check if too many rows are added and throw an error if too many are found. The trigger could look like the following:
CREATE TRIGGER OrderRow_Trigger
ON OrderRow
AFTER INSERT
AS
BEGIN
DECLARE @orderId int;
DECLARE @totalCount int;
DECLARE @maxCount int = 3;
DECLARE @errorText varchar(100);
DECLARE curAmountCheck CURSOR FAST_FORWARD FOR
WITH OrderIds AS (
SELECT DISTINCT
i.OrderId AS OrderId
FROM inserted i
)
SELECT oi.OrderId AS OrderId,
COUNT(*) AS Amount
FROM OrderIds oi
INNER JOIN OrderRow o on o.OrderId = oi.OrderId
GROUP BY oi.OrderId
HAVING COUNT(*) > @maxCount
ORDER BY oi.OrderId
OFFSET 0 ROWS
FETCH FIRST 1 ROW ONLY;
OPEN curAmountCheck;
FETCH NEXT FROM curAmountCheck INTO @orderId, @totalCount;
IF @@FETCH_STATUS = 0 BEGIN
SET @errorText = 'Order ID ' + _
CAST(@orderId AS VARCHAR(100)) + ' has too many rows (' + _
CAST(@totalCount AS VARCHAR(100)) + ')';
END;
CLOSE curAmountCheck;
DEALLOCATE curAmountCheck;
IF @errorText IS NOT NULL BEGIN
THROW 50001, @errorText,1;
END;
END;
Let's break the logic into pieces:
First the trigger definition, this trigger is executed whenever new rows are INSERTed to the table. The trigger logic is executed AFTER the insert meaning that all constraints have been checked. For example, if a NOT NULL constraint would be violated, this trigger won't execute because the row is not added to the table.
Then we have a few variables which are used in the program logic. The @maxCount is actually not necessary but it helps to see the maximum limit of the rows.
The query. This is the main component for the trigger. The query fetches all orders that have too many order rows. To keep the query simplified, I used Common Table Expression (CTE) to break the query into smaller pieces. The named OrderIds query simply fetches all individual OrderIds that have been inserted in the batch. The query is done from inserted table which is a virtual table triggers can use to see what rows were inserted in the batch.
Now that we know all the OrderIds, the outer part of the CTE simply fetches the number of order rows for each OrderId that has been increased. Note that the same batch could also delete order rows but we don't need to worry about those unless there have also been insertions. The overall amount is fetched from the actual OrderRow table, grouped and then only groups having more than the max limit are returned.
The query is defined as a cursor. This could be done in several ways, but in this example, I chose to use cursor to easily fetch some informative data to include into the potential error message.
And finally, the cursor is opened and data fetched using it. If fetch succeeds, it means that we have an OrderId that has too many order rows. In such a case, an error is thrown.
Now we have to test if this actually works. Let's do it using the following script:
INSERT INTO OrderItem (OrderId, Ordered)
VALUES (2, CURRENT_TIMESTAMP);
GO
INSERT INTO OrderRow (OrderRowId, OrderId, Product, Amount, Price)
VALUES (6, 2, 'Product A', 1, 100);
INSERT INTO OrderRow (OrderRowId, OrderId, Product, Amount, Price)
VALUES (7, 2, 'Product B', 1, 200);
INSERT INTO OrderRow (OrderRowId, OrderId, Product, Amount, Price)
VALUES (8, 2, 'Product C', 1, 300);
INSERT INTO OrderRow (OrderRowId, OrderId, Product, Amount, Price)
VALUES (9, 2, 'Product D', 1, 400);
INSERT INTO OrderRow (OrderRowId, OrderId, Product, Amount, Price)
VALUES (10, 2, 'Product E', 1, 500);
GO
When run, it produces the following output:
(1 row affected)
(1 row affected)
(1 row affected)
(1 row affected)
Msg 50001, Level 16, State 1, Procedure OrderRow_Trigger, Line 29 [Batch Start Line 73]
Order ID 2 has too many rows (4)
So that's it, we've successfully limited the number of rows. Of course in real life, the scenario and the conditions would be more complex, but this should get you started.
Important note! Since this is not a constraint but a trigger, it will not enforce this logic unless the trigger exists and is activated (rows inserted for a specific order). What this means is that old rows are left as they are. If you go to the beginning of this trick, you notice that we added 5 order rows for OrderId 1. Nothing has changed and those rows still exist in the table. So you may need to check old data manually, depending on the requirements.
About Performance
Triggers and cursors always raise discussion about performance and potential issues. It's good to have this discussion so let's dive into the subject a bit.
First of all, we need to consider what we are comparing against. If this business rule is enforced, there are at least four different possibilities:
- Check the amount of rows using a SQL query from the client side before inserting an individual row.
- The same check as in the previous bullet but the query is implemented in a stored procedure which is called from the client.
- Check the amount from client side after the
insert. - Check done by the trigger as explained in this tip.
Comparing bullets one, two, and three to the fourth option, there are at least three major differences that should be taken into account:
- Roundtrip cost. Other options require that a separate call from client to the database is performed before (or after) the
insert is executed. This requires a roundtrip which causes network traffic and possibly other resource usage, depending on the architecture. This may or may not introduce bottlenecks to the operation. - Inserting multiple rows. If the application wants to insert multiple rows to the table using a single run, how are the row amounts validated? This situation would happen, for example, when
INSERT INTO .. SELECT -structure or MERGE statements are used. The application must somehow know the rows that should be checked or the single statement needs to be broken into a loop. Obviously, breaking the statement to use a loop would be a bad option performance wise. - The third option in differences is a bit similar compared to the previous bullet. Somehow the application needs to know which rows were inserted in order to make the check afterwards. This is simple if only one row is inserted but in case of multiple rows, the situation is different. In the worst case, all existing rows need to be checked over and over again.
Looking at those three differences, the benefit when using the trigger based solution is that roundtrips are not needed and the trigger handles all rows that are inserted in the batch, regardless how many of them.
Roundtrip impact is environment specific so we can't analyse it in this tip. Inserting multiple rows during a single run is an architectural point so it's also outside the scope of this. The thing we can compare is the individual SQL statement executions so let's have a look at those.
Resource Consumption
So, how much does the trigger check cost? An easy, even though not comprehensive, way to look at this is to investigate the execution plans. What I did was that I added 10'000 rows to OrderItem and 30'000 rows to OrderRow and then executed a single INSERT INTO OrderRow statement and checked the actual plans.
The plan for the INSERT looks like this:
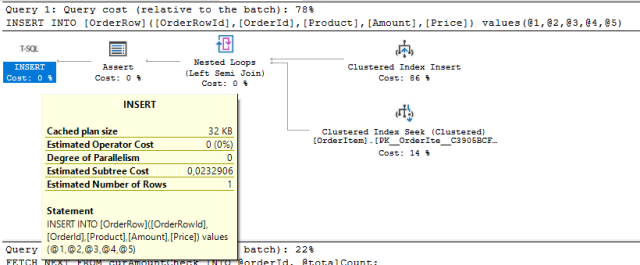
And the plan for the FETCH CURSOR usage like this:

As you see, the fetch in the trigger causes 22% of the overall cost. In general, that's actually not much compared to the insert statement. Of course, one has to keep in mind the cost of index maintenance that is needed because of the insertion.
Well, not bad but the key question is, how this compares to an individual, separately used check. For the comparison, I used the statement below:
DECLARE @orderId int = 2;
DECLARE @maxCount int = 3;
SELECT o.OrderId AS OrderId,
COUNT(*) AS Amount
FROM OrderRow o
WHERE o.OrderId = @orderId
GROUP BY o.OrderId
HAVING COUNT(*) > @maxCount;
The plan looks like this:
Looking at the cost only, it's about half the amount of the query used in the trigger. However, keep in mind that the difference of the cost is not because of the location of the query (trigger or outside), instead it's because the query in the trigger uses inserted table to check all the inserted rows. This is not possible outside the trigger as discussed earlier.
Also note that we're only comparing the plan, not the whole execution so network traffic, etc. is not included.
Conclusion
As a conclusion, I'd say that from the performance point of view, there's not much difference even if the logic is placed inside the trigger, as long as the implementation is well designed. However, when using the trigger based solution, it gives two major benefits:
- Business logic is always enforced, regardless of how inserts are done.
- Business logic is always enforced, even for set based inserts
Points of Interest
Some links you may find useful are:
History
- 16th May, 2021: Initial version
- 2nd June, 2021: Added discussion about performance

