Introduction
I noticed that the perennial favorite topic developers want to hear about is database. This is probably because it is the common denominator of all projects but there is also another common reason. If you are a programmer and spend any time at all with a DBA, you will hear the mantra spoken that you need to learn to think in sets. What do sets have to do with databases? Why is thinking in sets important?
Let's not get too idealistic, but delve into it a bit. Sets work for databases because that is how they are designed. Relationships and relational expressions are set expressions. And it is literally true that you can get almost anywhere you want to in the database world if only you have this set thing down pat.
Loops in databases are bad. Instead, we want to talk about relationships. So what is the simplest relationship? Two tables with some segment of the two in common.
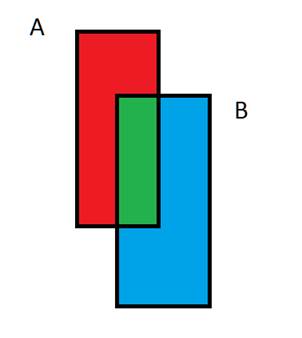
The green in the above diagram represents the chunk of common indexes that A and B share. For our example, we will say table A has an Aid and a Bid for each common element. Every row has an Aid, but some rows have a null in Bid. And in the B table, every row has a unique Bid. To select all the rows with values in common, we:
SELECT * FROM A JOIN B ON A.Bid = B.Bid
If you are a SQL aware coder, this should be obvious. The other sections of the graph are also interesting. A rows that have no B, also simple.
SELECT * FROM A WHERE Bid IS NULL
The most interesting one is the last possibility. Most programmers start writing something like:
SELECT * FROM B as B1 WHERE NOT EXISTS(SELECT * FROM A WHERE A.BID=B.BID)
This looks settish, but it is bad. The reason it is bad is that the NOT EXISTS SQL gets called once for each row in the B table. And the select has to go through all the joins every time to find if something exists. The better way to do it is something I call a marching join. I will explain the name at the end. For now, let's imagine that I want all the rows in B. I also want a match on all the B rows that have one available. In SQL syntax, we have something called a left join that can give us this.
SELECT * FROM B LEFT JOIN A ON A.BID=B.BID
gives me just that result set. Now where there is a B record that has no corresponding A record, that B record will have NULL values for all the A table items. And it will produce this join set by doing a scan through the A table, and the B table, joining up rows as it goes. But there is only one scan for each table, which is a much better situation. So then our final statement might be:
SELECT B.* FROM B LEFT JOIN A ON A.Bid = B.Bid WHERE B.Bid IS NULL
The name marching join comes from the observation that we do a left join, remove the non-null right rows, and what is left is the right answer. Left, right, left, right - marching. I also note that my bad pun seems to be quite memorable despite the groans it sometimes creates.
Let's make another observation here and extend this simplest possible join a bit. I leave it as an exercise for the reader but consider that our A here, or our B could be a query and not just a table. You can start playing with this by considering A or B as views. When I first used this pattern, that is how I would implement stuff. Then consider that the output of any flavor of join we want in the above list can be an input to a new join. Again, views will make this clear for you. Another observation, you can join results from multiple joins using UNION statements where that makes sense. And as a result of all this, literally anything you might want to do can be done as a set.
As a programmer, you won't likely face the problem of doing data updates or inserts on tables based on existing data. But the principle to do so is exactly the same.
You should also be able to write SQL to detect problems in your database. MySQL databases are notorious for lacking referential integrity constraints and other sensible database stuff because the templates you use don't generate them, or can't use them without crashing. Now you can write SQL to go in and clean up the messes that are left behind from failed clients and other stupidity that is the baggage of such practices.

