Save judiciously
Since we have seen in the previous articles
that, CRUD operations on the entities follow slightly different rules than the
ubiquitous sql tables and rows, we should save the data in a way that enables
us to do the CRUD operations faster.
Like, if I am storing an e-commerce
business’ data, say Myntra, where in, each item for sale is categorised based
on target audience, then on commodity group that it belongs to and then on the
genre. Something like this:
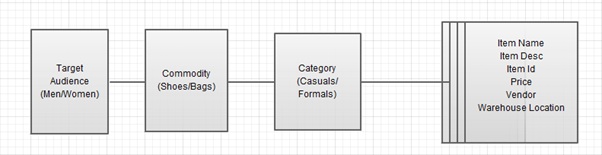
So, at the very first thought think of our
entities like this:

Where we think making item id as the
primary identifier makes our lives easy.
Which is correct from a DBA’s perspective,
the item id can indeed identify each record uniquely.
However, let’s put a little bit more
thought into how these sites are being used by its audience.
Each customer is in search of a specific
category of commodities and explores possibilities within them. Well most of
the time when the person is sure what he/she wants to buy J
In that case, most of the fetching of
records will happen based on category and not item.
So, we could modify our entity as below:
Here we are making category as the
partition key, so that, all items in the same category stay together and
retrieving them is quick.
Another advantage that comes as a
by-product of this entity structure is, whenever the business decides to stop a
category, deletion is also quick, since everything is on same partition, batch
operations are valid.
Also, notice, I have removed the “Vendor”
property from the entity. We will store the entities in tables named after
vendor ids, like tables named : HiDesign20114576Items.
This will enable us to mark all the items
to delete by any vendor whenever any vendor drops contract and the business
doesn’t want to sell their products anymore (which is quite a frequent
situation). Deleting a table is a less than a second’s work and a single url
request. Whereas, if we had kept the previous entity structure, we would have
to loop through each partition causing the whole table scan to find which items
match the vendor and then delete them. That would be pretty expensive.
Another example is the entries in
WADLogsTable. The entries keep on increasing exponentially, however, it takes
time for dev to be sure that the logs are unimportant now and could be deleted.
We can schedule a monthly job to archive
the logs in tables named by months like that shown in the below screen capture,
and delete those logs from WADLogsTable.
This arms us with the possibility to delete
the logs with a single request in a fraction of seconds, whenever the person in
charge feels they are not required anymore.
private void Background_PurgeAndArchive(object sender, DoWorkEventArgs e)
{
List<Object> genericlist = e.Argument as List<Object>;
SelectedTableName = genericlist[0].ToString();
DateTime StartDate = Convert.ToDateTime(genericlist[1]);
DateTime EndDate = Convert.ToDateTime(genericlist[2]);
TableQuery="PartitionKey ge '0"+StartDate.Ticks+"' and PartitionKey le '0"+EndDate.Ticks+"'";
if (!OpenAccount()) return;
try
{
CloudTableClient tableClient = CloudStorageAccount.CreateCloudTableClient();
TableServiceContext tableServiceContext = CreateTableServiceContext(tableClient);
IEnumerable<GenericEntity> entities = null;
entities = (from entity in tableServiceContext.CreateQuery<GenericEntity>(SelectedTableName) select entity);
if (!String.IsNullOrEmpty(TableQuery))
{
entities = (from entity in tableServiceContext.CreateQuery<GenericEntity>(SelectedTableName)
.AddQueryOption("$filter", TableQuery)
select entity);
}
var partitions = entities.Distinct(new GenericEntityComparer()).Select(p => p.PartitionKey);
IEnumerable<IEnumerable<GenericEntity>> ChunksOfWork = null;
foreach (string partition in partitions)
{
var ThisPartitionEntities = entities.Where(en => en.PartitionKey == partition).ToList();
if (ChunksOfWork != null)
ChunksOfWork = ChunksOfWork.Union(ThisPartitionEntities.Chunk(100));
else
ChunksOfWork = ThisPartitionEntities.Chunk(100);
}
string TableName = StartDate.ToString("MMMM", CultureInfo.InvariantCulture).Substring(0,3) + "Logs";
if (NewTableIfNotExists(TableName))
{
const bool forceNonParallel_A = true;
var options_A = new ParallelOptions { MaxDegreeOfParallelism = forceNonParallel_A ? 1 : -1 };
Parallel.ForEach(ChunksOfWork, chunk =>
{
CloudTableClient MonthlyTableClient = CloudStorageAccount.CreateCloudTableClient();
TableServiceContext tsContext = CreateTableServiceContext(MonthlyTableClient);
foreach (GenericEntity entity in chunk)
tsContext.AddObject(TableName, entity);
tsContext.SaveChangesWithRetries(SaveChangesOptions.Batch);
});
const bool forceNonParallel_P = true;
var options_P = new ParallelOptions { MaxDegreeOfParallelism = forceNonParallel_P ? 1 : -1 };
Parallel.ForEach(ChunksOfWork, chunk =>
{
TableServiceContext tsContext1 = CreateTableServiceContext(tableClient);
foreach (GenericEntity entity in chunk)
{
tsContext1.AttachTo(SelectedTableName, entity, "*");
tsContext1.DeleteObject(entity);
}
tsContext1.SaveChangesWithRetries(SaveChangesOptions.Batch);
});
}
int deleteCount = 0;
foreach (GenericEntity entity in entities)
{
tableServiceContext.DeleteObject(entity);
tableServiceContext.SaveChanges();
deleteCount++;
}
if (deleteCount == 1)
{
ReportSuccess("1 entity archived");
}
else
{
ReportSuccess(deleteCount.ToString() + " entities archived");
}
}
catch (Exception ex)
{
ReportException(ex);
}
}
The same code could be kept in controllers
and a scheduled url call to this code will do the trick.
So, to conclude, we have to put a bit of
thought on what could be a table, an entity and most importantly, which
property to designate as the partition key and which one will be the row key.

