Introduction
The LogJoin is a simple console utility written in C#, also it can be used as a good example of regex-driven file parser for beginners. In this tip, I'll show how to use it and what things it can do.
A few words about its features:
- It is simple: less code means less bugs
- Text parsing is based on user-defined Regular expressions (multiline is supported)
- Input files are not fully loaded into memory
- Multiple files can be selected as single input source (this is useful when logs are split into multiple files, there is no need to join them into one big file)
- It can join unlimited number of sources (limited only by computer resources)
- Currently, it supports output to CSV format only
Background
Sometimes developers or administrators need to collect small pieces of data from huge log files for further analysis. Often the file format does not conform to any standards like CSV or XML. Let's say they are unstructured. This is the first part of the problem. The second is that the data pieces (related to the same entity) may locate in different files where each file has its own unique format. This simple utility is designed to solve both problems.
Imagine the situation, you have log files from four applications, messaging clients, where the first, second and third clients are sending messages to the fourth client. Each client writes details about each event to its own log file, i.e., when sending a message, sender application writes a set of message attributes (message ID, title, sender account, when it was sent, etc.) to the log. Below is an example (full content is too large and I show only a part of it).
...
Message sent from account John. Message ID: 34, time: 2013-01-14 05:29:07;
title: eu pellentesque; words count: 62
Message body: risus lacus, interdum quis vehicula et, ...Aenean quis laoreet lacus.
Praesent et justo ut eros tristique pulvinar at sed urna. Integer
Message sent from account John. Message ID: 35, time: 2013-01-14 13:36:04;
title: tellus Donec; words count: 53
Message body: elit. Aenean sed ipsum ut ipsum ...Vestibulum a felis
...
I highlighted the data that has to be extracted from the log file.
The second and third logs have similar content:
...
Message sent from account Mike. Message ID: 17,
time: 2013-01-07 06:11:24; title: at elit; words count: 52
Message body: dolor sit amet, ...habitasse platea dictumst. Suspendisse a
Message sent from account Mike. Message ID: 18,
time: 2013-01-07 14:31:26; title: Suspendisse a; words count: 39
Message body: sollicitudin placerat. Curabitur porttitor, ...a lectus sit amet enim
...
...
Message sent from account Kate. Message ID: 17, time: 2013-01-07 07:36:39;
title: felis tellus; words count: 58
Message body: hac habitasse platea dictumst. ...pellentesque magna nibh, fringilla laoreet sapien
Message sent from account Kate. Message ID: 18, time: 2013-01-07 18:18:06;
title: sit amet; words count: 30
Message body: sollicitudin placerat. ...ipsum venenatis pulvinar at sed nunc. In hac
...
Recipient application log contains information about incoming messages, like message ID, sender's account name, title, time when it was chekced by a spam filter, spam flag, etc.
...
New message received, ID: 17, sender: John. Processing it.
Title: penatibus et
Current time: 2013-01-07 01:44:14
Is spam: True
New message received, ID: 17, sender: Mike. Processing it.
Title: at elit
Current time: 2013-01-07 06:11:56
Is spam: True
New message received, ID: 17, sender: Kate. Processing it.
Title: felis tellus
Current time: 2013-01-07 07:39:46
Is spam: False
New message received, ID: 18, sender: John. Processing it.
Title: turpis at
Current time: 2013-01-07 09:11:01
Is spam: True
New message received, ID: 18, sender: Mike. Processing it.
Title: Suspendisse a
Current time: 2013-01-07 14:32:48
Is spam: False
New message received, ID: 18, sender: Kate. Processing it.
Title: sit amet
Current time: 2013-01-07 18:20:55
Is spam: True
...
Assume the goal is to compare time when spam messages were sent and time when recipient detected them as spam. In the next section, I'll explain how to achieve this using LogJoin tool.
The Solution
As I said before, there are two main tasks:
- Extract values from unstructured text file (or files) and represent them as set of records (like a table in relational database). I call this set of records as Source.
- Join multiple Sources into single set of records (i.e. into other Source) using operation similar to Left Outer Join in relational databases.
For the first task, regular expressions are used. Regular expression defines rules that extract necessary values from the unstructured text and represent them as set of fields, each fileld has name and value (for example, messageID=17, messageAuthor=John). A set of fields is called Record (like record in relational table). Method GetRecord in class Source performs extraction of the values:
private Record GetRecord(string text, int recordNumber)
{
var match = this._recordRegex.Match(text);
if (!match.Success)
return null;
string[] keyParts;
keyParts = this._keyGroupNames != null
? this._keyGroupNames.Select(gn => match.Groups[gn].Value).ToArray()
: new[] {recordNumber.ToString(CultureInfo.InvariantCulture)};
if (keyParts.All(string.IsNullOrEmpty))
throw new ApplicationException(string.Format("Key not found in '{0}' text: {1}",
this.Name, text));
return new Record(string.Join("~", keyParts))
{
OtherFields = this.OtherColumnsNames.Select(cn => match.Groups[cn].Value).ToArray()
};
}
The second task is to join sources to a result set and export the result to output file. This logic is implemented in class Join. Method JoinSources joins records from all sources and method WriteRecords dumps result to output file.
private static IEnumerable<Record> JoinSources(IEnumerable<Source> sources)
{
IEnumerable<Record> allRecords = null;
foreach (var source in sources)
{
if (allRecords == null)
allRecords = source.GetAllRecords().GroupBy(_ => _.Key, (key, group) => @group.Last());
else
{
Source newSource = source;
allRecords = allRecords
.GroupJoin(newSource.GetAllRecords(), _ => _.Key, _ => _.Key,
(r, group) => new Record(r.Key)
{
OtherFields =
r.OtherFields.Concat(
@group.Any()
? @group.Last().OtherFields
: newSource.OtherColumnsNames.Select(_ => string.Empty)
).ToArray()
});
}
}
return allRecords;
}
private long WriteRecords(IEnumerable<Record> allRecords, TextWriter writer)
{
var s = Stopwatch.StartNew();
long count = 0;
foreach (var record in allRecords)
{
var line = string.Join(this._separator, new[] {record.Key}.Concat(record.OtherFields));
writer.WriteLine(line);
count++;
if (s.Elapsed.TotalSeconds > 3)
{
Console.WriteLine("{0} records written so far...", count);
s = Stopwatch.StartNew();
}
}
return count;
}
Using the Tool
All parameters are passed to the application from App.Config file, <parameters> section. It consists of two main parts: Regular expressions and Inputs. Details on each are shown in comments:
<parameters>
<expressions>
<expr name="recipientRecord" multiline="true">
<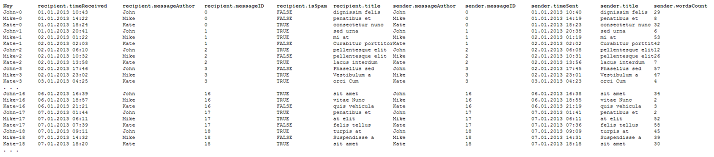
You can click on the image to enlarge.
Conclusion
You can download the sources and binaries.
If you have any questions, bug reports, suggestions regarding both this tip and the application, you're welcome to email me at dev.yuriy.n@gmail.com. Also, if you find the application useful, it would be nice for me to know about that.

