Introduction
Are you trying to use CString::Tokenize() to parse CSV files, HL7 messages or something similar, but running into problems because the function is not handling empty fields the way you expect it to? Then this is the tip you are looking for.
The problem is quite simple. You are trying to parse data with a fixed number of fields, where each field maps to a specific record in a structure or table in your application. In order to correctly insert the data, you need to know which fields the parsed data belong to, including the parsed fields that are empty.
As an example, let's just say you have a simple structure like this:
struct tSimpleRecord
{
CString strField1;
CString strField2;
CString strField3;
CString strField4;
CString strField5;
};
And you are parsing data from a CSV file, that might look like this:
Field 1,Field 2,Field 3,Field 4,Field 5
Field 1,Field 2,,Field 4,
When using the sample code for CStringT::Tokenize() from the MSDN page[^], parsing the first line returns all five fields separately as you expect, but when parsing the second line, the result looks like this:
"Field 1"
"Field 2"
"Field 4"
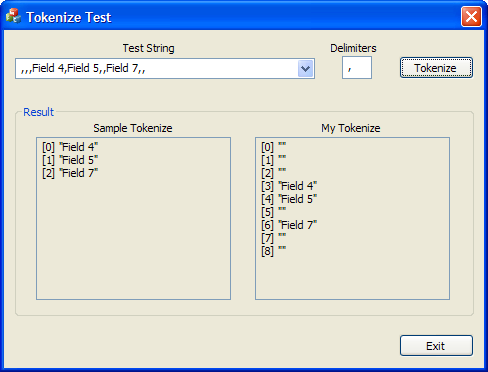
So, the sample code completely ignores the empty fields. I am not really sure why it is implemented like that, because although there are scenarios where this is what you want, I believe the majority number of cases call for the result to be:
"Field 1"
"Field 2"
""
"Field 4"
""
I figured out how to make it work as I wanted it to without too much overhead and I put together a basic sample program for you to play with. There is nothing special to it, but it allows you to test out my solution.
I know MFC is not as prominent as it once was and I know there are an incredible number of Tokenizer solutions out there already, but I am not trying to introduce yet another Tokenizer class. This is a simple tip to show you how to use the existing function to achieve what you are trying to do.
I wrote this tip because I did not find a similar solution anywhere when I was looking into this issue and I just hope it will help out a developer or two.
Background
A while back, I had to update an old MFC project. It had originally been written in Visual C++ 6 and since updated to Visual Studio 2010. The existing functionality was reading CSV data from a 3rd party system and the format had changed slightly, so we had to update things on our side.
The project already included a String Tokenizer class (which had been carried over from VC6), but much to my dismay it needed to be updated to handle the new data format so I figured, why not scrap it and use the 'new' CString::Tokenize() function. I grabbed the sample from the MSDN page[^], modified it slightly to fit my needs and ended up with this function:
void SimpleTokenizer(const CString& strFields, const CString& strDelimiters, CStringArray& arFields)
{
arFields.RemoveAll();
if (!strFields.IsEmpty() && !strDelimiters.IsEmpty())
{
int nPosition = 0;
CString strField = strFields.Tokenize(strDelimiters, nPosition);
while (strField != _T(""))
{
arFields.Add(strField);
strField = strFields.Tokenize(strDelimiters, nPosition);
}
}
}
When I tested it out, I was surprised to find that the resulting string array did not contain the number of strings I thought it would. I checked the code, stepped through it in the debugger a couple of times and took to Google to see how other developers had solved the problem.
Surprisingly, I did not find a solution, but plenty of suggestions to use other Tokenize methods, such as in the links below:
Solution
Sure, I could have packed it in at this point, modified the existing class or used something else, but I decided to look a little closer and see if I could come up with a code change that was simple enough to justify using this method instead of something else.
It didn't actually take me long to realize that the answer was right there in the parameters for the function, specifically the iStart variable, which (according to MSDN) "is updated to be the position following the ending delimiter character, or -1 if the end of the string was reached".
CStringT CStringT::Tokenize(PCXSTR pszTokens, int& iStart) const;
My solution is actually pretty simple: Store the previous position value before calling Tokenize(). After the call to Tokenize(), use the previous and the new position value to figure out how many characters the function processed, then by using the length of the returned string, calculate how many empty fields were skipped.
That is the basic logic and in my solution below, I just add that to nTotalFields, which gives me the index into the CStringArray where the newly returned field should be placed. By calling CStringArray::SetAtGrow(), I don't have to worry about adding those empty fields to the array myself as it will be done for me automatically.
void MyTokenizer(const CString& strFields, const CString& strDelimiters, CStringArray& arFields)
{
arFields.RemoveAll();
if (!strFields.IsEmpty() && !strDelimiters.IsEmpty())
{
int nPosition = 0, nTotalFields = 0;
do
{
int nOldPosition = nPosition;
CString strField = strFields.Tokenize(strDelimiters, nPosition);
if (nPosition != -1)
{
nTotalFields += (nPosition - nOldPosition - strField.GetLength());
}
else
{
nTotalFields += (strFields.GetLength() + 1 - nOldPosition);
}
arFields.SetAtGrow(nTotalFields - 1, strField);
} while (nPosition != -1 && nPosition <= strFields.GetLength());
}
}
I considered using the conditional operator[^] in the calculation of nTotalFields to reduce the number of code lines and make it very close to the number of lines in the first function, but I did not want to make it difficult for the reader to understand what is going on.
Points of Interest
I know you probably did not read every single line of code in the MyTokenizer() function, but if you did, perhaps you noticed the condition that ends the loop.
do
{
:
:
} while (nPosition != -1 && nPosition <= strFields.GetLength());
The reason I check for nPosition not being larger than the length of the input string is not because I am a bit paranoid. Although not directly mentioned in the description for iStart, the CString::Tokenize() function can actually set the value to strFields.GetLength()+1. Did you get that? It is obviously not a valid index in the string, so why would it do something like that?
To answer this question, let me show you the output of a simple TRACE I added and run the two sample inputs from earlier through the program.
Input: "Field 1,Field 2,Field 3,Field 4,Field 5" - Length: 39
"Field 1": OldPosition = 0, Position = 8, Field Length = 7
"Field 2": OldPosition = 8, Position = 16, Field Length = 7
"Field 3": OldPosition = 16, Position = 24, Field Length = 7
"Field 4": OldPosition = 24, Position = 32, Field Length = 7
"Field 5": OldPosition = 32, Position = 40, Field Length = 7
Input: "Field 1,Field 2,,Field 4," - Length: 25
"Field 1": OldPosition = 0, Position = 8, Field Length = 7
"Field 2": OldPosition = 8, Position = 16, Field Length = 7
"Field 4": OldPosition = 16, Position = 25, Field Length = 7
"" : OldPosition = 25, Position = -1, Field Length = 0
Looking at the final call in the first sample, you can see that nPosition is set to strFields.GetLength()+1. The last character it added to the returned string would have been at strFields.GetLength()-1 (the last valid index in the string), hence it expects the next delimiter to be at the position strFields.GetLength() and the beginning of the next field to be at the position strFields.GetLength()+1.
So, that explains why nPosition can be set to this value, but I would have preferred the function to set the value to -1 if it is not a valid index.
History
- November 11, 2013: First submission
- November 23, 2013: Fixed the misspelled 'delimiter' in the article text and source code. Added Points of Interest section.

