Introduction
Performance optimization for reporting is a big deal for any application. It is more special when working with huge volume of data processing like tool like OLAP CUBE. In this tip, I will show a few techniques to improve the OLAP cube performance with huge volume of data (more than 10 million data in the fact table) with a negligible trade off. Slight modification in the Cube dimensions can get the following benefits:
- Significant performance improvement
- Reduced time to process the CUBE
- Less disk utilization during cube processing
- Less database size
- Cost minimization for cube maintenance
Background
I am working on a CUBE reporting project for the past 1 year. Initially, the CUBE was fine with its few dimensions and very little data. Now the data volume has increased about 10 times than the beginning. As a result, data warehouse size, CUBE size, data processing time and disk utilization have increased significantly and overall reporting performance and manageability became a big issue.
Usual Implementation
Usually, we create Dimension tables in the data warehouse for all unique dimensions. Later, we cross join the dimension tables to insert data into fact table of a star schema CUBE. Because of cross join, the fact tables become too large with huge database size and take a lot of time to process the CUBE. Moreover, any modification to the CUBE like adding new dimension becomes a pain for the developers. The budget also goes high for the modification.
For example, we have a client report with the following dimensions:
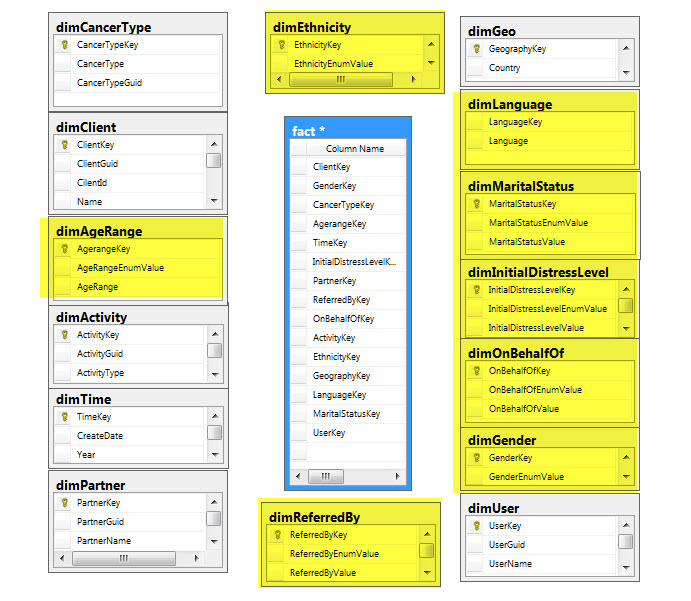
Here the fact table is constructed by cross joining 15 dimension tables. If the data volume is not so big, it’s not a big deal to insert data in these tables. But when the data volume increases, it becomes really a challenging issue to insert/update data in this table. In my case, for about 80000 clients in dimClient dimension, it took about total 1.5 - 2 hours to insert/update data and process the CUBE with relative values in the dimension tables. In Trade off section, we will show a comparison table before and after modification.
Here is the cube browser view to see Total Client Measure against Marital Status dimension:

You can see the Marital status dimension values are coming from ‘DimMaritalStatus’ Dimension’s ‘Marital StatusValue’ Member.
Findings and Solutions
Usually in fact table, we keep the primary key for reference and use the dimension table’s value property as dimension text. After a deep analysis, I have found that we can eliminate no of cross join by removing some of the dimensions and moving those dimension’s text values to some other dimension, i.e., we can remove the yellow highlighted dimensions and move their values into client dimension which are basically 1 to 1 property of a client.
Now, we have moved this property on the Client table as value property. In this case, we will use the Clients table’s value in the report as dimension. As the clientKey is already in the fact table, so there is no problem with the cube to count total no. of Clients associated with the dimensions.
So after modification, the schema will look like:
It’s much simpler and light weighted. The main thing is cross join has been eliminated by 8 times during data insertion in the fact table, which makes the difference by decreasing the no. of rows in the fact table.
Here is the cube browser view to see Total Client Measure against Marital Status dimension after modification:
You can see the marital status dimension values are coming from ‘DimClient’ Dimension’s ‘Marital Status’ Member instead of DimMaritalStatus dimension's MaritalStatusValue member. Please note that the count in the image before and after modification is not the same because the image is taken from a live DB which has increased over time, so don’t worry about the count mismatch.
Trade Off
The above proposed approach will increase your cube performance and decrease disk utilization, but it would be ideal when you use this type of Dimension for the huge volume of data. One limitation is here that is cube will process dimension values only which are used. E.g. In the above image, you can see there are nine dimension values (Divorced, Domestic Partnership, I prefer not to respond, Married, Partnered, Separated, Single, Widowed, Unknown) and they have a count for the Total client measure. That means each of the values is used by the clients. If any of the values are not used by any client, for instance, no client is widowed then ‘Widowed’ will not appear as Marital Status dimension value. This would be an issue if you want to see a zero count against Widowed if there is no client who is widowed. When each of the values of the dimension is associated with at least one client then all the dimension values will be available.
Here is the comparison before and after modification in my case:
So if you are not bothered with the dimension values which are not used, this is a very useful technique to optimize the cube processing by 80-90%.

