Introduction
This article and the accompanying source code provides one method of extracting from a block of text a brief excerpt that contains the most relevant portion of text that a user is searching based on the search terms entered.
The source code is "plug and play", just include the class in your project. This article outlines how it works and the issues involved.
Note that this is not intended to be a search solution, it is used for post processing the search results. If you are rolling your own search engine for an application, you might be interested in my Unicode multilingual word breaking article.
Background
In the course of building a search feature in a business application I am currently working on, it became necessary to show brief excerpts of the results that were found when the user performed a search. This is just like using a search engine on the internet which shows a brief excerpt of what can be found when clicking on the result.
This sounds easy on the surface but is actually fairly complex. It is difficult to pick out the most relevant portion of text of the user's search for display because the search terms may appear many times in the document but we only need a small portion to display.
This solution uses a sliding window technique. This may be a solution that is often referred to as "naive" in algorithm books and I am posting this here with the hope of fostering some discussion that may lead to improvements on the concept.
That being said, however it works and is fast enough for our purposes.
The technique
The technique I use incorporates a relevancy scoring system and a sliding window method for extraction. The goal is to be able to ultimately show a list of results ranked by potential relevancy with a brief excerpt that is no more than a selected number of characters in length and that shows the most relevant text for that result.
There are many different methods of scoring and ranking, each with pro's and con's related to the exact application, in our case the following method works well and should be applicable in many applications where nothing too serious is required.
The document text is scored by comparison with the search terms entered by the user. The scoring system I've settled on is a weighted system and relevancy is calculated within each result document itself, not against all the search result documents.
75% of the relevancy score is comprised of the ratio of total number of search terms the user has entered versus how many of them appear in the document in question. For example, if the user is searching for "apple pear peach" and the source document is examined and if every one of those terms appears then the base score so far is 75 out of 100 possible points. Note that each search term is only examined once to ensure it appears in the document, there is no bonus at this point if the same search term appears more than once, that is handled in the next step:
25% of the relevancy score is comprised of the ratio of search term text to non search term text in the document. In other words if the document contains 500 characters and 50 of those characters are from matching search terms then the formula is (50/500)*25=2.5, so in this case an additional 2.5 is added to the base score to come up with a total score.
This gives us a method of ranking documents against each other, however we still need to excerpt the best passage from the search result document to display to the user. Again, the same scoring system is used, however this time it's used to score a substring of the text within a sliding "window" over the search result document.
The "window" is a substring of the text that is not longer than the preset length, the default is 80 characters. To get the best excerpt, the window starts at the beginning of the search result document text, a score is calculated for the text within that window, the window is then slid over as many characters as the shortest word in the search terms provided and a score is again taken. If this score is greater than the previous score then this window of text is saved as the "best" window so far and the score is saved as the "best" score so far. This process continues until all the source document text has been "windowed" and scored. The end result is the best excerpt that fits within the preset length desired.
Using the code
The code is provided in a class ExtractAndRank. This class contains several properties that affect how it operates:
Properties
MaximumCharactersToExtract - Read/Write - this property should be set to the length of text you want to extract. The default value is 80.
ExtractionThresholdRank - Read/Write - the minimum relevancy rank that will trigger text extraction. The default value is 10.
FlattenExtract - Read/Write - if true will strip out carriage return line feeds to ensure a flat line of text. The default is true.
Extract - Read only - contains the most relevant excerpt after source text is processed.
Ranking - Read only - (float) contains the overall ranking of the document.
Public methods
public void Process (string rawText, string[]searchTerms) - rawText is the input document, searchTerms is a string array of the words being sought.
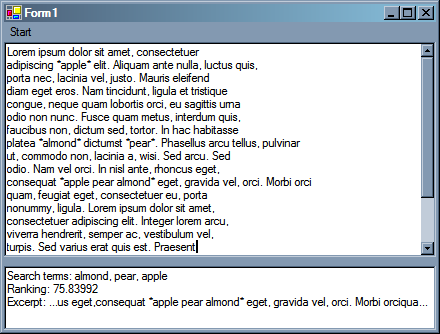
ExtractAndRank er=new ExtractAndRank();
er.Process(this.edRawText.Text,new string[]{"almond","pear","apple"});
this.edExcerpt.Text="Excerpt: " +er.Extract;
Hopefully this will be of some use to others requiring something similar. Any suggestions are welcome.
History
- 22nd-April-2005: Initially posted.
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




