Introduction
This article is composed of a program that I developed in the past and I completed today because I can renew the theory of Chomsky. I diffuse this article to present my solution. She may be known elsewhere but I do not know. I am a developer for 30 years and I graduated from high computer and I worked in companies in France.<o:p>
I diffuse this article because I have traveled the Loyc LL(K) project which is a great project, a project possessing highly developed and probably unsuspected abilities. In my article, I will propose a program to define different rules of grammar programming language and, more generally, text and numeric data. <o:p>
Why is this Useful?<o:p>
I always found that to specify a programming language to analyze the lexicon and grammar, everything must be detailed and Chomsky forces us to specify a programming language there retailer hundreds of more or less complex rules of perspective paradigm.<o:p>
My solution is in fact practical, because there are more complicated grammar rules to specify: for example, a mathematical expression grammar is written in BNF (Backus-Naur Form):<o:p>
E -> E + E
E -> E - E
E -> E / E
E -> E * E
E -> (E)
E -> T
E -> N
T -> [a-zA-Z _] [a-aA-Z_0-9] *
N -> [0-9] +<o:p></o:p>
But it lacks the information that the operator + and * are left operators - and / are operators on the right. It is clear that the definition of a mathematical expression can become very complicated especially if one adds to it functions such as trigonometric functions or with several parameters.<o:p>
The Backup-Naur form is not practical for the representation of rules I set because this information is immediately based on the algorithm I developed.
The problems are as follows:
- "How to increase the speed of analysis if the shift and Reduce operations are many?"<o:p>
- "How to quickly write grammar rules by focusing on content rather than its form?"<o:p>
- "How to solve the hierarchy problem blocks of instructions following a context in which all the blocks form a set incomplete?"<o:p>
Technically, if there are many rules, then treatment is longer; at the same time, the rules are present to make deterministic something that is nondeterministic in nature. Indeed, the grammar rules define how it organizes the target programming language added to the uncertainty of each component programs specified for meet a specific algorithm but endlessly replicating a single format.
Background
My training is very complete and I am extremely well trained to create and develop programming languages the compiler will be most able to respond to all the possibilities offered by language. This is one of my best skills programming skills of lexical and grammatical analysis software. In addition, the software always needs this type of media: text media containing various forms of information and logical answers by following a path on the purpose of the software: a path that must be followed but that should not write in "raw" in high-level languages.<o:p>
These are small files or configuration files, XML or INI or other form that contain specific information and relationship between them. Sometimes, it is even better to develop a school program to find and create these text files as they are very complex and require to pay close attention to everything runs well (including the objectives and risks of bugs or errors in the data to be processed.<o:p>
After my training, I wanted to create a most syntactic and grammatical analysis software. Universal because the software is intended to chart and it allows to ignore the difficulties of writing grammar rules. This difficulty is very large and representative forms are difficult to understand: it takes several days to fully finalize all rules of a specific language: sometimes the language is impossible to analyze using tools such as lex and yacc programs. This is particularly the case of context-free grammars and written languages. If the lex program analyzes the terms and can "eat" the spacing of characters, they are nevertheless required in some languages.<o:p>
It takes several decades of projects and programming languages to see which algorithmic prowess seeing because software companies want to acquire great fame and high technical lead for it under the absolute secret research in this direction. The results are sometimes drugs including in the means that invested in them.<o:p>
This is the case with Microsoft and other large companies. But the amounts of knowledge are kept private and can only be undertaken by a handful of people able to create real innovations: the programming language Microsoft has created in over 15 years is probably: Visual Basic.<o:p>
Admittedly, the source of the program that processes files VB is still well kept. Indeed, it is very different from other because these do not have the ability to easily compile this language. One shows the syntax:<o:p>
Function Call (param1, param2, _<o:p></o:p>
param3, param4, _<o:p></o:p>
param5)<o:p></o:p>
This is the underscore character that betrayed the specific algorithm. If lex program should compile VB, while it should take into account the context and the carriage return character separation through a parsing following the underscore character contextually used in this case to continue instruction on the line below as VB does not accept multiple lines!<o:p>
The new system C # .NET significantly more advanced than Java, we must recognize it, also has enormous changes. And the most spectacular is that the processing source file compilation far exceeds the speed of the basic algorithms of compilation. Not because the code is simply converts IL but because parsing is much more advanced in techniques Chomsky.<o:p>
Let's face it: Chomsky is automata theory (such as syntactic analyzes are) but they are outdated theories long by private companies of the world and even new algorithms probably contradict Chomsky had made to limit the time the computers are still treated as binary files and not thousands of pages of text in 1/10 of a second.<o:p>
In 2010, XML-FO is able to convert large files in all formats to PDF format (for example) is far simple iterative PLC defined by simple and limited rules. We move away more and more of binary and bytes go towards the treatment of direct and texts written in Unicode (which doubles or even quadruples the size of the text file) without reducing the file a binary sequence with small additions to make!<o:p>
In 2015, all the websites displayed formatted and analyzed feedback and perform a syntax highlighting all instructions and automatically indented source programs even automatically moderate what is said without losing sight of the national and international laws and sometimes make a manual moderation replace or complement.<o:p>
All this is not the action of one, but a community of people able to provide each company with a targeted and reliable expertise and which does not escape the attention of persons between them. Social networks are an example and the open-source community extends to the plurality of capacities and made many interested in the manna of knowledge art.<o:p>
One could say that computers and programming represents the universe of people very high level ... even the kings of the world. But it is not without forgetting the wrong choice: as elsewhere and especially in the field of knowledge, it is easy to live the financial perspective, while many prefer the financial interest over the interest of knowledge.<o:p>
Recall that computing is still somewhat prone area to disseminate knowledge and knowledge not because it is a closed circle but because sometimes it is not within the reach of any intellectual; This is actually an area where you have cognitive capacities not easily acquired. Let's put in place, those who wish to teach new programming in a few days are as charlatans Sunday.<o:p>
Using the Code
Application
I first present a description of the use of the software. The software is called precedence because I use a concept original definition of precedence with a single parameter: a number of prior. The number of the lowest priority is 1. It is the priority for all terms (numbers and names). The higher numbers define the priority for operators knowing that the following operators are sorted in ascending order of priority: + - * /. Parentheses may be attached and in this case, the precedence is changed.
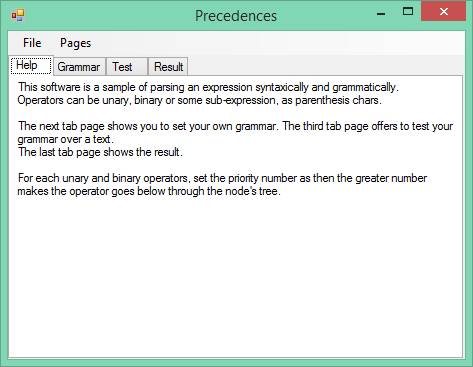
The application displays a single window. There are 4 tabs and a menu: Help, Grammar, and Test Result. The menu and File Pages: File menu allows to load / save a file extension *.f containing examples of rules grammar. The second menu displays the tabs.

The Grammar tab corresponds to the configuration of a set of separate rules. The example below shows the rules to identify additions, multiplication, subtraction and division of integers, and variable names. Parentheses are used to change the precedence.
The third tab allows you to choose a sample test. The drop-down list is to select a test. The text to be analyzed is in the entry area; the area is editable; a button to add a new test or keep the changes to the text. Click on the button "Validate" performs parsing of the text in accordance with the rules of grammar defined in the tab "Grammar".
The fourth tab shows the results of the analysis. The result is the XML representation of the tree hierarchy parsing.
Defining the Rules of Grammar
- A rule is first identified by a target, i.e., its type:
- No action: If nothing happens: this rule is useful for "eat" certain words
- Expression list: This action creates a new expression and stores it in a list; it creates a series of successive expressions.
- Open brackets: This action opens a parenthesis in an expression
- Close brackets: This action ends a parenthesis; a closing parenthesis followed an opening parenthesis, otherwise a parser error occurs.
- Open sub-expression: This action starts a sub-branch of the tree
- Close sub-expression: This action goes in the sub-branch of the tree
- Unary operator: Indicates a unary operator; you must specify a priority number
- Binary operator: Binary; you must specify a priority number
- Statement: Indicates that this is an instruction
- Term: Indicates that it is a term
- A unary or binary operator must have a higher priority number or equal to 1.
An instruction or term still has the lowest priority, that is to say 1. The higher the priority number, the operator is secondary to the other: so, whenever a priority operator larger is encountered, it is below the smallest priority number of operators. For example, the addition operator + has a lower priority than the multiplication operator * is a priority because the multiplication with respect to addition; also, the multiplication is automatically placed below a + operator if there is one. Similarly, if a multiplication followed by an addition, then the addition takes place automatically in the shaft above multiplication. The priority number is therefore the sole indicator of how operators and terms are stored in the tree. The terms and instructions have the level of the lowest priority because it will always be the leaves of the syntax tree. - The objects to build in the tree are uniquely identified by a regular expression.
- Attributes can be specified:
Attributes are named by name and contain a value. The suite name = value [, ...] form the set of attributes. The attributes are added to the XML representation of the resulting syntax tree.
Developments
The FIFO class implements a provider / consumer algorithm. The class provides FifoWriter subsequently recognized tokens. Lexical units are read once for all; no other reading or read-only product; the construction of the tree is optimal because the sub-branches are added successively without being replayed.
The FifoReader class implements a thread that processes the lexical data received subject to the form of expression objects whose class indicates the type of object to insert into the tree. The reading of data causes an immediate search for the position in the parse tree. An error can occur for example, when two successive binary operators. In this case, the resulting treatment may become chaotic. Class Expression encompasses all actions towards sending FifoWriter class. The methods of this class are applied to each type item send: an opening or closing parenthesis, as a phrase, a list of expressions, a unary or binary operator, a term or instruction.
A Terminate method indicates that the treatment is over and must complete the execution of the thread. The insertion system object in the tree is implemented by three major classes: Movement, nodule and NoeudNAire. The nodule class and its derived classes NoduleOperateurBinaire, NoduleOperateurUnaire, NoduleTerme and NoduleInstruction are stored items in the tree. Each class implements the virtual function Print () that writes the representation in an XML document. NoeudNAire class is the one that performs the search of the insertion position in the graph taking into account the type of object to be inserted and its priority over other existing nodes already in the graph: It is possible to insert the top of the tree node or inserting instead of an existing node and this node move in a subgraph. According to the priority, if it is larger than that of an object of the shaft while the object to be inserted arises below. The tree may have two branches; with over two legs, it indicates that the grammar rules defined should be reviewed.
Class Movement performs the actual insertion functions in the resulting syntax tree. It corresponds to the end of the processing of a node to be inserted in the tree.
If the implementation was carried out in this way, by using a thread in the background, it's because treatments are so detailed time consuming over reading treatment of lexical units. Also, an underlying system could allow other situations such as error detection, treatment and their indications (row, column, error description) to help the developer to correct his grammar rules or fix the source of its program.
Points of Interest
This is a great advanced technology in the field of parsing. Chomsky has always considered the text analysis and compilation as the most difficult technique to master and the longest to develop.<o:p>
With this program, and creative use of a priority number, recursive forms disappear in favor of a simple list of lexical units identified by a regular expression; reading the text to be analyzed is made from start to finish without proofreading and no state is required to follow the progress of grammar rules.<o:p>
With this program, the definition of grammar becomes easy, simple, fast, intuitive and uncomplicated.
History
In a future article, I will present the evolution of this software such as:<o:p>
- Context<o:p>
- Type inference (whole, real, operators with feedback data)<o:p>
- The definition of n-items operators (three or more sub-nodes)<o:p>
- Syntax highlighting<o:p>
- Preparing to direct compilation (or conversion code)<o:p>
- Reverse-engineering<o:p>
- Attributes with expressions and calculation functions

