Introduction
This class was created in order to replace POD C string (CS) concept, which obviously is a subject to the poor design (personally i consider this as one of the worsests solutions along with the null pointers). Compared to CS the StaticallyBufferedString significantly boosts both speed, safety and functionality.
Background
With the introduction of a C++ there comes an alternatives to the original C-style things: pointers -> references, POD C strings -> std::string, malloc/free -> new/delete, struct -> class, macro -> template, #define MAX 127 -> static const int MAX = 127 etc.
The std::string class is a good, acceptable solution, except the one thing: pooling memory model. It's dynamic by default. Although it benefits with the possibilty of a real-time size control, the cost of using a heap memory sometimes is too high. Both locks (if we don't use a private heap somehow) and fragmentation leads to it. Optimizing memory allocation by prereserving memory is a good way to boost up an overall performance, but it still involves all heap-based allocation problems. Of course you can provide your own allocator to be used by the std::string class, but writing your own allocator is not really an easy problem and that was not my point was originally up to.
Another reason to use a containers with the fixed capacity memory pools is (espically with the strings) that in the most cases the average and maximum size of the object is generatlly well known (due to the predefined limitations) or at least not to hard to be forecasted (usally by a statistics gathering).
There is also a mathematical guarantees against memory allocation failures when using memory pooling (assuming you correctly calculates the minimum required pool size).
Class description
The class methods generally designed to provide std::string like interface, but there are notable things to mention and some specific methods to describe.
The class template was designed to work with the different types of symbols
template<typename TElemType, const size_t MaxLen>
(through i tested it precisely with the basic chars only as the other char types i personally does not reallly require and other developers use it rarely too).
The main class traits is:
The class provides an auto generated hash functor
ADD_HASHER_FOR(TThisType, hasher)
from the HashUtils module
#define ADD_HASHER_FOR(ClassName, HasherName) \
template <typename T = ClassName>\
struct HasherName {\
auto operator()(const T& obj) const throw() -> decltype(obj.hash()) {\
return obj.hash();\
}\
};
to support hash containers.
To provide some compatibility with the STL standart, class defines a mock object type as an internall allocator type (as no allocator really involved here)
typedef AllocatorInterface<TElemType> allocator_type;
AllocatorInterface module is pretty simple and self-descriptive
ifndef AllocatorInterfaceH
#define AllocatorInterfaceH
#include <memory>
template <class T>
class AllocatorInterface : public std::allocator<T> {
public:
typedef typename std::allocator<T> TBaseAllocatorType;
typedef typename TBaseAllocatorType::pointer pointer;
typedef typename TBaseAllocatorType::const_pointer const_pointer;
typedef typename TBaseAllocatorType::reference reference;
typedef typename TBaseAllocatorType::const_reference const_reference;
typedef typename TBaseAllocatorType::size_type size_type;
AllocatorInterface() = default;
AllocatorInterface(const AllocatorInterface&) = default;
template <class U>
AllocatorInterface(AllocatorInterface<U>&&) throw() {}
virtual ~AllocatorInterface() = default;
virtual pointer address(reference ref) const throw() {
return std::allocator<T>::address(ref);
}
virtual const_pointer address(const_reference ref) const throw() {
return std::allocator<T>::address(ref);
}
virtual pointer allocate(size_type count, std::allocator<void>::const_pointer hint = nullptr) = 0;
virtual void deallocate(pointer addr, size_type count) = 0;
virtual size_type max_size() const throw() {
return size_type();
}
private:
};
template <typename T, class U>
bool operator==(const AllocatorInterface<T>&, const AllocatorInterface<U>&) throw() {
return false;
}
template <typename T, class U>
bool operator!=(const AllocatorInterface<T>& alloc1, const AllocatorInterface<U>& alloc2) throw() {
return !(alloc1 == alloc2);
}
#endif // AllocatorInterfaceH
String is iterable as it uses a Generic Random Access Iterator
typedef GenericRAIterator<StaticallyBufferedStringLight,
value_type, false, false> iterator;
typedef GenericRAIterator<StaticallyBufferedStringLight,
value_type, true, false> reverse_iterator;
typedef GenericRAIterator<StaticallyBufferedStringLight,
value_type, false, true> const_iterator;
typedef GenericRAIterator<StaticallyBufferedStringLight,
value_type, true, true> const_reverse_iterator;
but the none-constant irterators should be used very carefully as using them to modify an internal character sequence is a clear and easy way to broke the object state (for example, a simple way to do so is to put a string terminator - '\0' in the middle of a sequence altering so an actual string length) and relevance (of the cached hash), those requiring the class to forcefully restore it's state which is does't directly supported currently.
I provide none-const irterators in order to increase overall flexebility and versatality of the class, through i suppose they should't be used unless the user is clearly undestands what he is doing.
(There is a way to fix that behaviour by providing a proxy object instead of the real char reference by the subscript operator, but i am not sure is It really required).
Most functions of the class is templated to provide compatibility with the other possible storrage types (if they satisfys the requirements).
template<typename TStorageType>
StaticallyBufferedStringLight& operator=(const TStorageType& str) throw() {
Custom strCmp function from the MemUtils module used to comapre the strings of characters of a multiple (and a different) types
template<const size_t CmpChunkSize = sizeof(std::uintptr_t), const bool SignedCmpChunk = false, typename TElem1Type, typename TElem2Type>
typename IntegralTypeBySize<CmpChunkSize, true>::Type
strCmp(const TElem1Type* mem1, const TElem2Type* mem2) throw()
{
typedef typename IntegralTypeBySize<sizeof(*mem1), false>::Type TUE1T; typedef typename IntegralTypeBySize<sizeof(*mem2), false>::Type TUE2T;
typedef typename IntegralTypeBySize<CmpChunkSize, true>::Type TReturnType;
static_assert(sizeof(TReturnType) > sizeof(*mem1) &&
sizeof(TReturnType) > sizeof(*mem2), "Incorrect elem. type size");
if (mem1 == mem2) return TReturnType(); typename IntegralTypeBySize<CmpChunkSize, SignedCmpChunk>::Type elem1, elem2;
while (true) {
elem1 = static_cast<decltype(elem1)>(static_cast<TUE1T>(*mem1));
elem2 = static_cast<decltype(elem2)>(static_cast<TUE2T>(*mem2));
if (!elem1 || elem1 != elem2)
return static_cast<TReturnType>(elem1) - elem2;
++mem1, ++mem2;
}
}
There are also stream-like operators defined to concat. the numbers to the string:
template<typename TValueType,
class = typename std::enable_if<std::is_arithmetic<TValueType>::value &&
!std::is_pointer<TValueType>::value && !std::is_same<TValueType, TElemType>::value>::type>
StaticallyBufferedStringLight& operator<<(const TValueType value) throw() {
append(value);
return *this;
}
StaticallyBufferedStringLight& operator<<(const TElemType* const str) throw() {
append(str);
return *this;
}
as you can see the SFINAE through std::enable_if and other type traits utilities is involved here to ensure that those operators is used with the correct types only.
Standart namespace was elso enhanced to increase STL compatibility
namespace std {
template<typename TElemType, const size_t MaxLen>
bool operator==(const std::string& dStr,
const StaticallyBufferedStringLight<TElemType, MaxLen>& sStr) throw() {
return sStr == dStr;
}
template<typename TElemType, const size_t MaxLen>
bool operator==(const TElemType* const cStr,
const StaticallyBufferedStringLight<TElemType, MaxLen>& sStr) throw() {
return sStr == cStr;
}
template<typename TElemType, const size_t MaxLen>
std::ostream& operator<<(std::ostream& stream,
const StaticallyBufferedStringLight<TElemType, MaxLen>& str) {
stream << str.c_str(); return stream;
}
template<typename TElemType, const size_t MaxLen>
std::istream& operator>>(std::istream& stream,
StaticallyBufferedStringLight<TElemType, MaxLen>& str) {
auto symb = stream.get(); while (true) {
symb = stream.get(); switch (symb) {
case '\n': case '\r': return stream; }
if (!stream) break; if (!str.push_back(symb)) break;
}
return stream;
}
};
As the str. had a very restricted capacity, there is a specific method presented to determine is the last string altering operation leads to the actual data truncation (this method just returns an internall flag, indicating the truncation event)
bool truncated() const throw() {
return truncated_;
}
Performance tweaks
The memory pool size is auto aligned to the 64-bit word size (as most modern processors is x64):
static const auto BUF_SIZE =
MaxLen + 1U + (((MaxLen + 1U) % 8U) ? (8U - (MaxLen + 1U) % 8U) : 0U);
(through is's may be better to align it to the natural pointer size - sizeof(std::uintptr_t))
One of the optimization methods here is to provide a specific handling of the specific cases, for example a comparison operator used to comapre the class instance with an array of characters (holding a C str.) can benefit on the known array size
template<const size_t ArrayElemCount>
bool operator==(const TElemType (&str)[ArrayElemCount]) const throw() {
if (str == data_) return true;
if (checkAddrIfInternal(str)) return false;
if (ArrayElemCount < (length_ + 1U)) return false;
const auto thisStrMemChunkSize = sizeof(*data_) * (length_ + 1U); return isEqualMemD<>(data_, str, thisStrMemChunkSize);
}
(but it looks like it is not work as intended, as, at least in my MS VS 2013 Community update 5, it is simlpy doesn't called).
The comparing here is performed by a custom isEqualMemD function from the MemUtils module
template<const bool SignedCmpChunk = false>
bool isEqualMemD(const void* const mem1, const void* const mem2, const size_t memSize) throw() {
typedef const typename IntegralTypeBySize<8U, SignedCmpChunk>::Type T64Bit;
typedef const typename IntegralTypeBySize<4U, SignedCmpChunk>::Type T32Bit;
typedef const typename IntegralTypeBySize<1U, SignedCmpChunk>::Type T8Bit;
if (memSize < 8U) {
return !memcmp(mem1, mem2, memSize);
}
switch (CPUInfo::INSTANCE.is64BitCPU) {
case true: assert(memSize >= 8U);
if (!isEqualMem<8U, SignedCmpChunk>(mem1, mem2, memSize / 8U)) return false;
return *(reinterpret_cast<T64Bit*>(static_cast<T8Bit*>(mem1) + memSize - 8U)) ==
*(reinterpret_cast<T64Bit*>(static_cast<T8Bit*>(mem2) + memSize - 8U));
default: assert(memSize >= 4U);
if (!isEqualMem<4U, SignedCmpChunk>(mem1, mem2, memSize / 4U)) return false;
return *(reinterpret_cast<T32Bit*>(static_cast<T8Bit*>(mem1) + memSize - 4U)) ==
*(reinterpret_cast<T32Bit*>(static_cast<T8Bit*>(mem2) + memSize - 4U));
}
}
This function is just a dispatcher, which calling an actual comparing function based on the CPU type (to benefit on the CPU register size)
bool isEqualMem(const void* const mem1, const void* const mem2, const size_t iterCount) throw() {
typedef typename IntegralTypeBySize<CmpChunkSize, SignedCmpChunk>::Type TCmpChunkType;
if (mem1 == mem2) return true; auto mem1re = static_cast<const TCmpChunkType*>(mem1); auto mem2re = static_cast<const TCmpChunkType*>(mem2);
const auto end = mem1re + iterCount;
while (mem1re < end) {
if (*mem1re != *mem2re) return false;
++mem1re, ++mem2re;
}
return true;
}
A detection of where the current CPU is x32 or x64 is performed by the HardwareUtils module
#ifndef HardwareUtilsH
#define HardwareUtilsH
#ifdef _MSC_VER
#include <cstring>
#include <intrin.h> // Microsoft Specific
#elif __GNUC__
#include <cpuid.h> // GCC
#endif
class CPUInfo {
public:
static const CPUInfo INSTANCE;
const bool is64BitCPU = false;
private:
CPUInfo() throw()
: is64BitCPU(findIs64BitCPU())
{}
~CPUInfo() = default;
CPUInfo(const CPUInfo&) throw() = delete;
CPUInfo(CPUInfo&&) throw() = delete;
CPUInfo& operator=(const CPUInfo&) throw() = delete;
CPUInfo& operator=(CPUInfo&&) throw() = delete;
static bool findIs64BitCPU() throw() {
static const auto GET_MAX_CMD_SUPPORTED = 0x80000000U;
unsigned int cpuInfo[4U] = {0}; #ifdef _MSC_VER
auto const cpuInfoRe = reinterpret_cast<int*>(cpuInfo); __cpuid(cpuInfoRe, GET_MAX_CMD_SUPPORTED);
const auto maxFuncIDSupported = *cpuInfo; #elif __GNUC__
const auto maxFuncIDSupported = __get_cpuid_max(GET_MAX_CMD_SUPPORTED, nullptr);
#else
static_assert(false, "Unsupported complier"); #endif
static const auto GET_EXTENDED_INFO = 0x80000001U; if (maxFuncIDSupported < GET_EXTENDED_INFO) return false;
#ifdef _MSC_VER
memset(cpuInfo, 0, sizeof(cpuInfo));
__cpuid(cpuInfoRe, GET_EXTENDED_INFO);
#elif __GNUC__
if (!__get_cpuid(GET_EXTENDED_INFO, cpuInfo, cpuInfo + 1U, cpuInfo + 2U, cpuInfo + 3U))
return false;
#endif
static const auto LONG_MODE_BIT = 536870912U; return 0U != (LONG_MODE_BIT & cpuInfo[3U]); }
};
#endif // HardwareUtilsH
size_t hash() const throw() {
static_assert(1U == sizeof(TElemType), "'TElemType' SHOULD be 1 byte long!");
if (modified_) { hash_ = MathUtils::getFNV1aHash(data_);
modified_ = false;
}
return hash_;
}
Comparison operator is also benefits on the hash caching: if comparing the two storage instances of some compatible types, which allows the hash code calculation & caching, assuming the hash code is already calculated (with the same hashing algorithm) and still relevant for both instances - if the hash codes is different then the instances are not equal (those making comparison complexity constant rather then linear)
template<class TStorageType>
bool operator==(const TStorageType& str) const throw() {
if (str.length() != length()) return false;
static const auto SAME_HASHING_ = (hashAlgoID() == hashAlgoID::ExecIfPresent(str));
if (SAME_HASHING_) {
const auto thisHash = getHashIfKnown(); if (thisHash) { const auto otherHash = getHashIfKnown::ExecIfPresent(str);
if (otherHash && otherHash != thisHash) return false; }
}
static const auto SAME_CHAR_TYPE_ = std::is_same<typename std::decay<decltype(*c_str())>::type,
typename std::decay<decltype(*str.c_str())>::type>::value;
switch (SAME_CHAR_TYPE_) {
case true: return isEqualMemD<>(data_, str.c_str(), sizeof(*data_) * length());
default: return *this == str.c_str();
}
}
hashAlgoID and getHashIfKnown helper functions used here, they are pretty self-explainable
static size_t hashAlgoID() throw() {
static const size_t ID_ = 'F' + 'N' + 'V' + '-' + '1' + 'a';
return ID_;
}
size_t getHashIfKnown() const throw() {
return modified_ ? size_t() : hash_;
}
Both of them is actually called using the ExecIfPresent idiom
EXEC_MEMBER_FUNC_IF_PRESENT(getHashIfKnown, size_t())
EXEC_MEMBER_FUNC_IF_PRESENT(hashAlgoID, size_t())
so storage types which is not support this mechanism (like standart std::string) can still be used with this class, those making it more versatile and flexible.
An equality comparison operator can also benefits on the hash code caching if (and only if) proven that the hash code generating algorithm generates a hash value in such manner that the hash of a larger (in terms of the comparision) string is always larger too
template<class TStorageType>
bool operator<(const TStorageType& str) const throw() {
static const auto SAME_HASHING_ = (hashAlgoID() == hashAlgoID::ExecIfPresent(str));
if (SAME_HASHING_ && HashCodeChecker::INSTANCE.hashOfLargerStrLarger) {
const auto thisHashCached = getHashIfKnown(), otherHashCached = str.getHashIfKnown();
if (thisHashCached && otherHashCached && (thisHashCached != otherHashCached)) {
return thisHashCached < otherHashCached;
}
}
static const auto SAME_CHAR_TYPE_ = std::is_same<typename std::decay<decltype(*c_str())>::type,
typename std::decay<decltype(*str.c_str())>::type>::value;
switch (SAME_CHAR_TYPE_) {
case true:
if (static_cast<const void*>(data_) == static_cast<const void*>(str.data())) return false;
return 0 > memcmp(data(), str.data(),
sizeof(*data_) * (std::min<>(length(), str.length()) + 1U));
default:
return *this < str.data(); }
}
FNV-1a algorithm, through, does not satisfys this requirement as proven by an automated test module <span style="background-color: rgb(255, 255, 255);">HashCodeChecker</span>
#include "StaticallyBufferedStringLight.h"
struct HashCodeChecker::HashChecker {
size_t operator()(const std::string& str) const throw() {
if (!COLLECT_STATS && !NEXT_HASH_LARGER_OR_EQ) return 0U; STR = str;
const auto currHash = STR.hash();
const auto nextLargerOrEq = (currHash >= PREV_HASH);
nextLargerOrEq ? ++STATS[1U] : ++*STATS;
NEXT_HASH_LARGER_OR_EQ &= nextLargerOrEq;
PREV_HASH = currHash;
return currHash;
}
static bool COLLECT_STATS; static size_t STATS[2U]; static size_t PREV_HASH; static bool NEXT_HASH_LARGER_OR_EQ; static StaticallyBufferedStringLight<char, 7U> STR;
};
bool HashCodeChecker::HashChecker::COLLECT_STATS;
size_t HashCodeChecker::HashChecker::STATS[2U];
size_t HashCodeChecker::HashChecker::PREV_HASH;
bool HashCodeChecker::HashChecker::NEXT_HASH_LARGER_OR_EQ = true;
decltype(HashCodeChecker::HashChecker::STR) HashCodeChecker::HashChecker::STR;
template <const bool SkipStatistics>
bool HashCodeChecker::ishashOfLargerStrLarger() throw() {
static const auto MAX_LEN_ = 55U;
static_assert('A' + MAX_LEN_ < 128, "Incorrect max. len.");
StaticallyBufferedStringLight<char, MAX_LEN_> str;
decltype(str.hash()) prevHash = str.hash(), nowHash = 0U;
auto currChar = 'A'; auto nextHashLargerOrEqCount = 0U, nextHashLowerCount = 0U;
for (auto charIdx = 0U; charIdx < str.max_size(); ++charIdx) {
str += currChar;
++currChar;
nowHash = str.hash();
nowHash >= prevHash ? ++nextHashLargerOrEqCount : ++nextHashLowerCount;
if (SkipStatistics && nextHashLowerCount) return false;
prevHash = nowHash;
}
char strBuf[4U] = {0};
HashTester::Params<std::extent<decltype(strBuf)>::value> params(strBuf);
const auto result = HashTester::createAndTestCharSeq<HashChecker>(params, false);
return !nextHashLowerCount && result && HashChecker::NEXT_HASH_LARGER_OR_EQ;
}
#ifdef _MSC_VER
const HashCodeChecker HashCodeChecker::INSTANCE;
#endif
(This moduIe uses the HashTester module).
There is also a specific append method presented which is used to do an optimized (as it skips double buffered copying / temporary object creation and destroying / heap memory usage, unlike standart std::to_string, for example) concatenation of string representation of a number
template<typename TValueType,
class = typename std::enable_if<std::is_arithmetic<TValueType>::value &&
!std::is_pointer<TValueType>::value && !std::is_same<TValueType, TElemType>::value>::type>
StaticallyBufferedStringLight& append(const TValueType value) throw() {
const auto spaceLeft = std::extent<decltype(data_)>::value - length_;
if (spaceLeft < 2U) { truncated_ = true;
return *this;
}
const char* mask = "";
auto returnFlag = false; auto getMask = [&]() throw() {
typedef typename TypeTag<decltype(value)>::TypeTags_ Tags;
switch (TYPE_TAG(value)) {
default: assert(false); case Tags::NULLPTR: returnFlag = true; break;
case Tags::BOOL: mask = value ? "true" : "false"; break;
case Tags::SIGNED_CHAR: mask = "%hhi"; break;
case Tags::SIGNED_SHORT_INT: mask = "%hi"; break;
case Tags::SIGNED_INT:
case Tags::WCHAR: mask = "%i"; break;
case Tags::SIGNED_LONG_INT: mask = "%li"; break;
case Tags::SIGNED_LONG_LONG_INT: mask = "%lli"; break;
case Tags::UNSIGNED_CHAR: mask = "%hhu"; break;
case Tags::UNSIGNED_SHORT_INT: mask = "%hu"; break;
case Tags::UNSIGNED_INT: mask = "%u"; break;
case Tags::UNSIGNED_LONG_INT: mask = "%lu"; break;
case Tags::UNSIGNED_LONG_LONG_INT: mask = "%llu"; break;
case Tags::FLOAT:
case Tags::DOUBLE:
mask = "%f"; break;
case Tags::LONG_DOUBLE: mask = "%Lf";
}
};
getMask();
if (returnFlag) return *this;
#ifdef _MSC_VER // MS VS specific
auto count = _snprintf_s(data_ + length_, spaceLeft, _TRUNCATE, mask, value);
if (count < 0) { count = spaceLeft - 1U;
truncated_ = true;
}
#else
auto count = snprintf(data_ + length_, spaceLeft, mask, value);
if (count < 0) {
data_[length_] = '\0'; return *this; }
if ((count + 1U) > spaceLeft) { count = spaceLeft - 1U;
truncated_ = true;
}
#endif
length_ += count;
modified_ = true;
return *this;
}
Speed comparison
And now the true test!
(ALL tests performed in the release mode with the ALL optimizations turned on, built x32 in MS VS Community 2013 update 5, runned on my lenovo IdeaPad S400 x64 laptop under x64 Win 8.1)
This test performs many (~400 000) smallest (by the one single char) concatenations to the string instance. It is a good case for the std::string (as ony a small percent of concatenations will lead to the situation where length will became larger then the current capacity requiring so to do a reallocation, and that percent will probably even decrease in time, depends on the actual string realization), worst case for the C str. (as it require to determine [with the linear complexity] the string length before doing an actual addition, which results in a time complexity growth in a an arithmetic progression withing each call) and don't-care case for the static str.
std::string:
- best: all the required space is preallocated before the concat.
- worst: addition of a strings whose length is growth in a geometry progression in such a manner that each addition will require to do a reallocation
C str.:
- best: one single addition to the empty string
- worst: many smallest concatenations to the long initial string
Static str.: all cases are equal
Test code:
static const auto STR_BUF_SIZE_ = 440U * 1024U;
CStr<STR_BUF_SIZE_ - 1U> cstr___1_;
StaticallyBufferedStringLight<char, STR_BUF_SIZE_ - 1U> static_str___1_;
std::string dynamic_str___1_;
cstr___1_.clear();
std::cout << cstr___1_.strBuf; const volatile auto cstr_test_time_ =
TestConcat(cstr___1_, STR_BUF_SIZE_ - 1U).count();
cstr___1_.clear();
std::cout << cstr___1_.strBuf;
static_str___1_.clear();
std::cout << static_str___1_; const volatile auto static_str_test_time_ =
TestConcat(static_str___1_, STR_BUF_SIZE_ - 1U).count();
cstr___1_.clear();
std::cout << cstr___1_.strBuf;
dynamic_str___1_.clear();
std::cout << dynamic_str___1_; const volatile auto dynamic_str_test_time_ =
TestConcat(dynamic_str___1_, STR_BUF_SIZE_ - 1U).count();
cstr___1_.clear();
std::cout << cstr___1_.strBuf;
std::cout << "static str: " << static_str_test_time_ << std::endl;
std::cout << "dynamic str: " << dynamic_str_test_time_ << std::endl;
std::cout << "cstr: " << cstr_test_time_ << std::endl;
std::cout << "\nStatic str.: 1.0, dynamic str.: "
<< static_cast<double>(dynamic_str_test_time_) / static_str_test_time_
<< ", POD C str.: "
<< static_cast<double>(cstr_test_time_) / static_str_test_time_ << std::endl;
template <class TStrType>
auto TestConcat(TStrType& str, const size_t maxLen) throw()
-> decltype(std::chrono::system_clock::now() - std::chrono::system_clock::now())
{
static const auto MIN_CHAR_ = 'a';
static const auto MAX_CHAR_ = 'z';
static_assert(MIN_CHAR_ < MAX_CHAR_, "Invalid chars");
std::default_random_engine gen;
std::uniform_int_distribution<int> distr(MIN_CHAR_, MAX_CHAR_);
char strToAdd[2U] = {0};
str.clear();
const auto startTime = std::chrono::high_resolution_clock::now();
for (size_t charIdx = 0U; charIdx < maxLen; ++charIdx) {
*strToAdd = distr(gen); str += strToAdd; }
const auto endTime = std::chrono::high_resolution_clock::now();
return endTime - startTime;
}
template <const size_t MaxLen>
struct CStr {
CStr() throw() {
clear();
}
void clear() throw() {
*strBuf = '\0';
}
void operator+=(const char* const str) throw() {
strcat(strBuf, str);
}
char strBuf[MaxLen + 1U];
};
Results:

2) Memory comparison routines speed test
This test involves testing speed of the standart C memcmp / strcmp and my custom comparing functions from the MemUtils module.
Test code:
const auto SIZE_ = 1024U * 1024U * 8U;
auto mem1 = new char[SIZE_];
memset(mem1, 200, SIZE_ - 1U);
auto mem2 = new char[SIZE_];
memset(mem2, 200, SIZE_ - 1U);
mem1[SIZE_ - 1U] = '\0';
mem2[SIZE_ - 1U] = '\0';
decltype(std::chrono::system_clock::now()) time1, time2;
static const auto COUNT_001_ = 7U;
static const auto TEST_COUNT_001_ = 40U;
decltype((time2 - time1).count()) counts[COUNT_001_] = {0};
auto memCmp_faster_then_memcmp_count = size_t();
auto memCmp_faster_then_quickCmp = size_t();
unsigned long long avg[COUNT_001_] = {0};
const auto iterCount_1_ = 40U;
for (size_t idx = 0U; idx < iterCount_1_; ++idx) {
time1 = std::chrono::system_clock::now();
volatile long long int r0 = 0LL;
for (size_t testIdx = size_t(); testIdx < TEST_COUNT_001_; ++testIdx) {
r0 = strCmp<>(mem1, mem2);
}
time2 = std::chrono::system_clock::now();
*counts = (time2 - time1).count();
*avg += *counts;
time1 = std::chrono::system_clock::now();
volatile long long int r1 = 0LL;
for (size_t testIdx = size_t(); testIdx < TEST_COUNT_001_; ++testIdx) {
r1 = quickCmp(mem1, mem2, SIZE_);
}
time2 = std::chrono::system_clock::now();
counts[1] = (time2 - time1).count();
avg[1U] += counts[1];
time1 = std::chrono::system_clock::now();
volatile long long int r2 = 0LL;
for (size_t testIdx = size_t(); testIdx < TEST_COUNT_001_; ++testIdx) {
r2 = memcmp(mem1, mem2, SIZE_);
}
time2 = std::chrono::system_clock::now();
counts[2] = (time2 - time1).count();
avg[2U] += counts[2];
time1 = std::chrono::system_clock::now();
volatile long long int r3 = 0LL;
for (size_t testIdx = size_t(); testIdx < TEST_COUNT_001_; ++testIdx) {
r3 = strcmp(mem1, mem2);
}
time2 = std::chrono::system_clock::now();
counts[3] = (time2 - time1).count();
avg[3U] += counts[3];
time1 = std::chrono::system_clock::now();
volatile long long int r4 = 0LL;
const auto count_1_ = SIZE_ / sizeof(std::uintptr_t);
for (size_t testIdx = size_t(); testIdx < TEST_COUNT_001_; ++testIdx) {
r4 = memCmp<>(mem1, mem2, count_1_);
}
time2 = std::chrono::system_clock::now();
counts[4] = (time2 - time1).count();
avg[4U] += counts[4];
time1 = std::chrono::system_clock::now();
volatile bool r5 = false;
for (size_t testIdx = size_t(); testIdx < TEST_COUNT_001_; ++testIdx) {
r5 = isEqualMemD(mem1, mem2, SIZE_);
}
time2 = std::chrono::system_clock::now();
counts[5] = (time2 - time1).count();
avg[5U] += counts[5];
time1 = std::chrono::system_clock::now();
volatile bool r6 = false;
const auto count_02_ = SIZE_ / 8U;
for (size_t testIdx = size_t(); testIdx < TEST_COUNT_001_; ++testIdx) {
r6 = isEqualMem<8U>(mem1, mem2, count_02_);
}
time2 = std::chrono::system_clock::now();
counts[6] = (time2 - time1).count();
avg[6U] += counts[6];
std::cout << "\n";
std::cout << "count6 - isEqualMem<8U> : " << counts[6] << "\n";
std::cout << "count5 - isEqualMemD : " << counts[5] << "\n";
std::cout << "count4 - memCmp<> : " << counts[4] << "\n";
std::cout << "count3 - strcmp : " << counts[3] << "\n";
std::cout << "count2 - memcmp : " << counts[2] << "\n";
std::cout << "count1 - quickCmp : " << counts[1] << "\n";
std::cout << "count0 - strCmp<> : " << *counts << "\n";
std::cout << "\n" << static_cast<double>(counts[3]) / counts[1] << "\n";
assert(r1 == r2);
if (counts[4] < counts[2]) ++memCmp_faster_then_memcmp_count;
if (counts[4] < counts[1]) ++memCmp_faster_then_quickCmp;
}
std::cout << "\nmemCmp_faster_then_memcmp_count: "
<< memCmp_faster_then_memcmp_count << " / "
<< iterCount_1_ << std::endl;
std::cout << "memCmp_faster_then_quickCmp: "
<< memCmp_faster_then_quickCmp << " / "
<< iterCount_1_ << std::endl << std::endl;
const char* const names_001_[]
= {"strCmp<> ",
"quickCmp ",
"memcmp ",
"strcmp ",
"memCmp<> ",
"isEqualMemD ",
"isEqualMem<8U> "};
auto idx_0001_ = 0U;
for (volatile auto& currAvg : avg) {
currAvg /= iterCount_1_;
std::cout << "avg " << names_001_[idx_0001_] << " - #" << idx_0001_ << ": " << currAvg << std::endl;
++idx_0001_;
}
delete[] mem1, delete[] mem2;
Results:
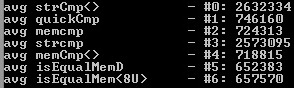
Static str. uses best suitable (not always fastest) functions: strCmp<>, isEqualMemD<>, memcmp.
Static str. uses isEqualMemD<> rather then memcmp if possible as it is faster, strCmp<> rather then strcmp as it capable of multiple char types comparing and memcmp rather then strCmp<> if possible as it is faster.
Through this page says that standart memcmp function had an intrinsic form on all architectures and i compiled my test cases with the '/Oi' compiler option, test shows that the custom isEqualMemD<> is slightly faster (which possibly should't be).
Testing 'less than' operators speed.
Test code:
const decltype(s_str_01_) s_str_02_ = static_chars_01_;
const decltype(dstr_01_) dstr_02_ = static_chars_01_;
volatile auto result__01_ = false;
time1 = std::chrono::system_clock::now();
for (size_t testIdx = size_t(); testIdx < 100000U; ++testIdx) {
result__01_ = s_str_01_ < s_str_02_;
}
time2 = std::chrono::system_clock::now();
counts[1] = (time2 - time1).count();
time1 = std::chrono::system_clock::now();
for (size_t testIdx = size_t(); testIdx < 100000U; ++testIdx) {
result__01_ = dstr_01_ < dstr_02_;
}
time2 = std::chrono::system_clock::now();
counts[2] = (time2 - time1).count();
time1 = std::chrono::system_clock::now();
for (size_t testIdx = size_t(); testIdx < 100000U; ++testIdx) {
result__01_ = strcmp(s_str_01_.c_str(), s_str_02_.c_str()) == 0;
}
time2 = std::chrono::system_clock::now();
counts[3] = (time2 - time1).count();
volatile auto diff = static_cast<double>(counts[2]) / counts[1];
std::cout << "\nStatic str. 'operator<' " << diff << " times faster then the dynamic one\n";
diff = static_cast<double>(counts[3]) / counts[1];
std::cout << " and " << diff << " times faster then the 'strcmp'\n";
Results:

4) Mass allocation/deallocation speed test
Shows why the concept actually was born :)
Firstly, the PerformanceTester module which used to do the test:
#ifndef PerformanceTesterH
#define PerformanceTesterH
#include <chrono>
#include <iostream>
class PerformanceTester {
public:
struct TestResults {
typedef decltype(std::chrono::system_clock::now()) TTimePoint;
typedef decltype((TTimePoint() - TTimePoint()).count()) TTimeCount;
void clear() throw() {
time1 = TTimeCount(), time2 = TTimeCount();
}
TTimeCount time1 = TTimeCount(), time2 = TTimeCount();
};
template <class TFunctor1, class TFunctor2, const bool onScreen = true>
static double test(TFunctor1& subj1, TFunctor2& subj2,
const size_t testCount, TestResults& results)
{
results.clear();
if (!testCount) return 0.0;
auto time1 = TestResults::TTimePoint(), time2 = TestResults::TTimePoint();
auto testIdx = size_t();
auto testSubj = [&](const bool isSecondSubj) throw() {
time1 = std::chrono::system_clock::now();
for (testIdx = size_t(); testIdx < testCount; ++testIdx) {
switch (isSecondSubj) {
case true: subj2(); break;
default: subj1(); }
}
time2 = std::chrono::system_clock::now();
return (time2 - time1).count();
};
results.time1 = testSubj(false);
results.time2 = testSubj(true);
const auto diff = static_cast<double>(results.time2) / results.time1;
if (onScreen) {
auto const potfix = (diff < 1.0) ? "faster" : "slower";
const auto diffReinterpreted = (diff < 1.0) ? (1.0 / diff) : diff;
std::cout << "\nSecond is " << diffReinterpreted << " times " << potfix << std::endl;
}
return diff;
}
};
#endif // PerformanceTesterH
Test code:
struct Funct1__ {
volatile int operator()() throw() {
volatile StaticallyBufferedStringLight<> str;
return 0;
}
} funct1__;
struct Funct2__ {
volatile int operator()() throw() {
std::string str;
str.reserve(127U);
return 0;
}
} funct2__;
PerformanceTester::TestResults results1;
PerformanceTester::test(funct1__, funct2__, 9999999U, results1);
Results:

Testing 'not equal' operators speed in case of the static str. hash code is already calculated.
Test code (diff. symbol towards the end) :
static auto const STR1
= "cam834mht8xth,a4xh387th,txh87c347837 g387go4 4w78t g34 3g7rgo bvgq7 tgq3874g478g8g oebgbg8 b"
"cwmc8htcw,o7845mt754cm8w4gcm8w4gc78w4gcw4cw4yc4c4xn34x63gc7sch74s4h5mc7h7cn34xm7xg78gxm7384x";
static auto const STR2
= "cam834mht8xth,a4xh387th,txh87c347837 g387go4 4w78t g34 3g7rgo bvgq7 tgq3874g478g8g oebgbg8 b"
"cwmc8htcw,o7845mt754cm8w4gcm8w4gc78w4cw4cw4yc4c4xn34x63gc7sc_74s4h5mc7h7cn34xm7xg78gxm7384x";
struct Funct1__ {
Funct1__() throw() : str1(STR1), str2(STR2) {
str1.hash();
str2.hash();
}
volatile int operator()() throw() {
volatile auto result = (str1 != str2);
return 0;
}
StaticallyBufferedStringLight<char, 255U> str1;
StaticallyBufferedStringLight<char, 255U> str2;
} funct1__;
struct Funct2__ {
Funct2__() throw() : str1(STR1), str2(STR2) {}
volatile int operator()() throw() {
volatile auto result = (str1 != str2);
return 0;
}
std::string str1;
std::string str2;
} funct2__;
PerformanceTester::TestResults results1;
PerformanceTester::test(funct1__, funct2__, 9999999U, results1);
Results:

Same test with the very first diff. symbol:

Points of Interest
Class using TypeHelpers, GenericRAIterator + CompareUtils, FuncUtils, and MathUtils + HashUtils modules.
This module is just a small part of the library, which uses C++11 features and which I am working under now, I decided to make it a public property.
History
Update 1: more speed tests added.
Update 2: downloadable archive is replaced with the new fixed, updated AND redesigned version 1.04.
Note that actual changes maded are NOT described NOR even mentioned in the article's text
(which is represents the original version), you can see them in the GitHub repository:
1) hash caching bugs fixed, hash calculation optimized & redesigned
2) move/copy constructors & operators fixed
3) added 'conditional raw copy on assignment' optimization
4) fixed possible rare inadequate action in 'zero hash of none empty str.' situation;
fixed bug leading to the performance degradation when comparing strs;
added hash compromisation mechanic to protect str. from some inadequate user action in case of user unawareness;
other minor optimizations
Update 3:
Tests (functional, performance AND integration) are now presented in the downloadable (as long as in the GitHub repository).
Some minor fixes (see history).

