Introduction
This article demonstrates an easy way to built lexical analyzers. It evolves around a lexical analyzer generator called Quex. Initially, I started working on this tool as a 'let's-just-see' activity on a train trip; and it became a passion for about the last decade. Quex grew from the desire to make things more comfortable, easier, and faster than other available tools. Its prominent features, today are:
- Generates directly coded engines, not table driven.
- Customizable line and column number counting.
- Unicode and other coding support.
- Indentation based lexical analysis (such as Python does).
- Modes that can be related by inheritance.
- Include stacks for file inclusion support.
- Many event handlers for fine grained control.
- Path and template compression for code size reduction.
- ... and it comes with many examples to play with.
In the following sections a minimalist example gives a first impression how this tool is used. Further, three features shall be presented in more detail. First, it is discussed how line and column number information can be accessed easily. Second, the mechanism to handle indentation based scopes (such as in Python) is presented. Third, it is shown how converters may be used to analyze character streams of arbitrary character encoding.
Background
Lexical analysis represents the first stage of automatic interpretation of text. That is, it detects 'atomic chunks of meaning' and packs them into so called 'tokens'.
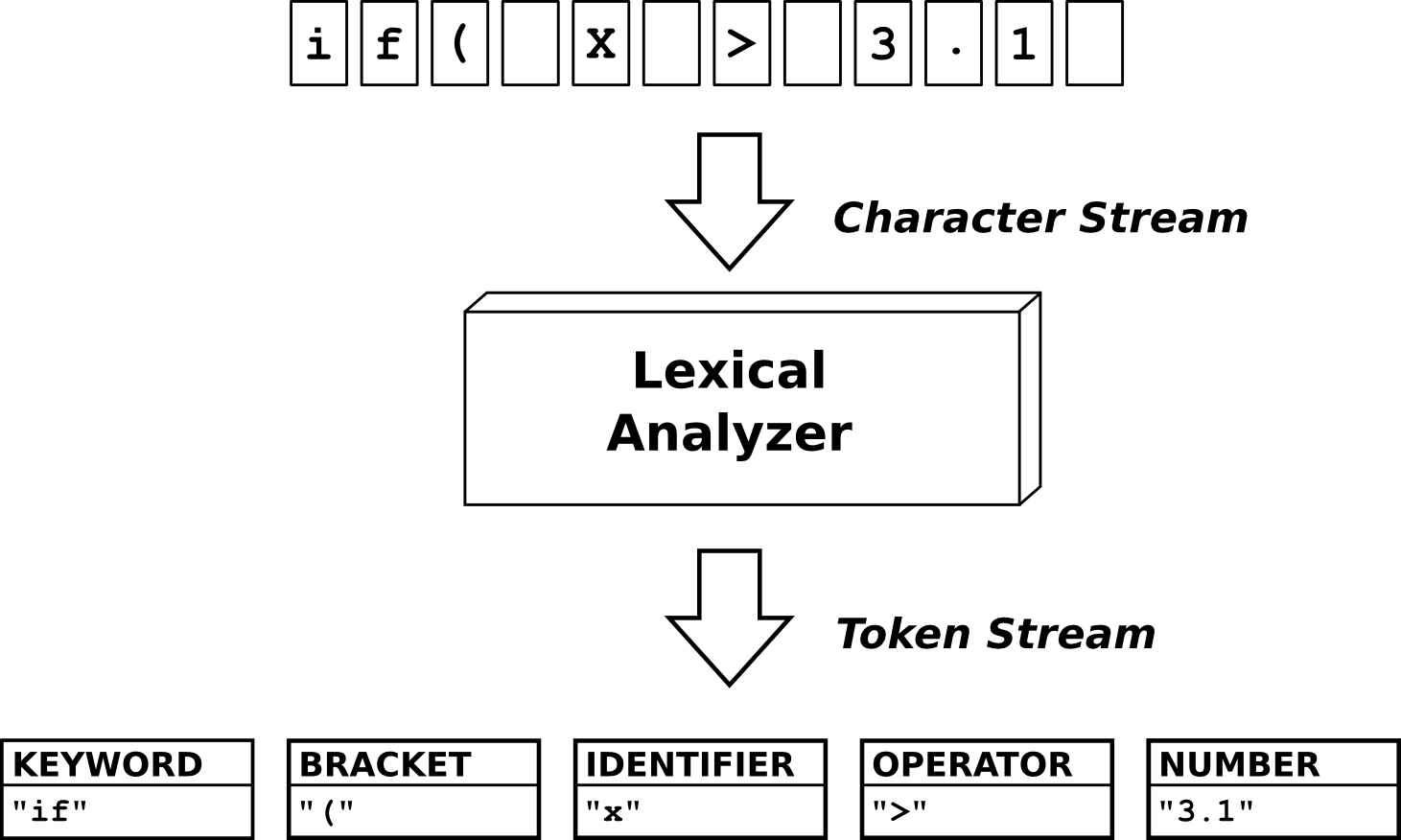
Detecting atomic chunks of meaning is done by pattern matching. In Quex patterns are described in terms of regular expressions in a form that has been popularized by lex and flex. Such patterns tell, for example, that an 'integer' consists of an aggregation of digits, an 'identifier' consists of an aggregation of letters, and some keyword may be defined as a specific character sequence such as while or if. A first impression of how to work with Quex is presented in a minimalist example detecting numbers and identifiers. It conveys enough knowledge to understand the following sections. For further reading, though, the extensive online documentation, or the manpage 'quex.1' which comes along with Quex may be reviewed.
To try the following, Quex must be installed, which is available for Linux, Windows, BSD, MacOS, Solaris, and on any system where Python2.7 is available (Indeed, Python2.7 is the primary dependency for Quex). It is assumed that the quex application's directory is in your system's PATH, and that the environment variable QUEX_PATH is set to the directory where Quex is installed.
The command line instructions work seamless on Unix systems. On Windows machines the string $QUEX_PATH must be replaced by %QUEX_PATH% and the relative path ./ must be replaced by nothing.
Minimalist Example
The behavior of a lexical analyzer is specified by means of pattern-action pairs. Whenever an incoming sequence of characters matches a pattern, a specific action shall be executed. It is generally a good idea to let this action produce a token. In these terms, a lexical analyzer transforms a stream of characters into a stream of tokens. An analyzer that produces tokens on detected numbers or identifiers is shown below.
mode PRIMER : <skip: [ \t\n]> {
[0-9]+ => QUEX_TKN_INTEGER(Lexeme);
[_a-zA-Z]+ => QUEX_TKN_IDENTIFIER(Lexeme);
}
The mode keyword opens a mode definition. Any analyzer action happens in a mode. The skip tag lets the analyzer ignore any white space. The 'pattern => action' pairs inside the curly braces define what token are triggered by what matches. With the above code fragment saved in the file "minimalist.qx" Quex can generate a lexical analyzer. On the command line, one may type
> quex -i minimalist.qx -o EasyLexer
which will generate a lexical analyzer engine "EasyLexer" and all its related files, namely
EasyLexer the analyzer's header file.EasyLexer-configuration containing the configuration parameters.EasyLexer.cpp the analyzer's implementation.EasyLexer-token the analyzer's token class file.EasyLexer-token_ids the definition of token identifiers.
Now, some driver code is required that initializes the analyzer and iterates over tokens. That is, an object of the class EasyLexer must be constructed and instructed to read from a file. To initiate the analysis cycle repeatedly, the member function receive() must be called.
#include "EasyLexer"
#include <iostream>
int main(int argc, char** argv)
{
using namespace std;
quex::Token* token_p = 0x0;
quex::EasyLexer qlex(argc == 1 ? "example.txt" : argv[1]);
do {
qlex.receive(&token_p);
cout << string(*token_p) << endl;
} while( token_p->type_id() != QUEX_TKN_TERMINATION );
return 0;
}
The output to standard cout is a placeholder for what the user might do with the token. Eventually, the end of the token stream is detected by means of a received token with QUEX_TKN_TERMINATION. With this fragment saved in the file "lexer.cpp" a complete lexical analyzer application can be built, for example using GNU's C++ Compiler:
> g++ -I. -I$QUEX_PATH lexer.cpp EasyLexer.cpp -o ./lexer
Now, it needs some input for lexer to chew on. Some numbers and identifiers in a sample text file "minimalist.txt" as shown below will do.
4711 hello world
Running the lexer with
> ./lexer minimalist.txt
delivers, eventually, the result of lexical analysis on the standard output as
INTEGER '4711'
IDENTIFIER 'hello'
IDENTIFIER 'world'
<TERMINATION> ''
The last few paragraphs took you the whole way from analyzer specification, driver implementation, and compilation to a display of analyzed data. If this has whetted your appetite, the following sections are for you. They show how easy it is to get line number information for error and warning outputs. It is explained how beautiful languages, such as Python, can be generated using the indentation based scope feature. For people living beyond the world of ASCII, the last section elaborates on lexical analysis of arbitrary character encodings.
Line Number Counting
When an interpreter chokes on some input that needs to be fixed, it better points precisely to where the error occurred. For that, at least, the line number, maybe also the column number, needs to be tracked. Tracking line and column numbers can be challenging, costly in terms of computing time, and add visual noise to the lexical analyzer description. So, it's a good thing that Quex does it implicitly. The command line flag "--no-column-counting" disables column number counting and "--no-line-counting" does so for line number counting. By default, both are enabled.
Quex is aware of the token class which is used to communicated analysis results. It uses the token to store the line and column number along with it. Thus, the line and column number can be read directly from the token as soon as it is received. Adding the following line to the fragment right before the standard output will add line and column information to the lexer's output.
...
cout << "(" << token_p->line_number() << ", "
cout << token_p->column_number() << ") \t";
cout << string(*token_p) << endl;
...
This is all that is required to keep track of column and line numbers. For customized counting, though, the mode tag counter is provided. This may be useful, for example, when working with typesetting systems, where an 'm' does not have the same horizontal width as an 'i'.
mode PRIMER :
<counter: [\t] => grid 8;
[i] => space 2;
[m] => space 5;
>
{
...
}
The above example specifies that a tab character lets the column number jump on a grid of eight column units. An 'i' is counted as two units and an 'm' is counted as five units.
Indentation Based Lexical Analysis
The Python programming language demonstrates beautifully how visual noise in code can be reduced by the so-called Off-Side Rule. That is, indentation limits statement blocks and no brackets are needed for that. A code fragment written in a syntax based on curly brackets might look like the following.
for x = 0 to N {
for y = x to M {
if array(x, y) == 0
return true;
}
}
}
return false;
Where OPEN_BRACKET and CLOSE_BRACKET are sent as reactions to { and }. They delimit statement blocks. The same functionality can be implemented in a language with indentation based scopes as follows.
for x = 0 to N
for y = x to M
if array(x, y) == 0
return true;
return false;
Here, statement blocks are delimited by INDENT and DEDENT tokens, as they are sent as reactions to change in indentation width. The syntactic content of the former and the latter is equivalent. But clearly, the latter is more concise. Quex supports the development of such languages. A mode that is defined with the indentation tag is equipped with a unit that produces the following tokens:
INDENT when a line with greater indentation occurs than its predecessor. It opens implicitly a 'block' for anything of greater indentation that follows.NODENT when a line with the same indentation occurs than its predecessor.DEDENT for each block that precedes with higher indentation than the current line. Those blocks are closed.
A file "indentation.qx" with the following content incites Quex to produce an indentation based lexical analyzer.
mode PRIMER :
<indentation: >
<skip: [ \t]>
{
[0-9]+ => QUEX_TKN_INTEGER(Lexeme);
[_a-zA-Z]+ => QUEX_TKN_IDENTIFIER(Lexeme);
}
The resulting engine can be run with the same driver code as before. So generating the lexical analyzer and compiling ...
> quex -i indentation.qx -o EasyLexer
> g++ -I. -I$QUEX_PATH lexer.cpp EasyLexer.cpp -o i-lexer
results in an application i-lexer. When fed with an example file "indentation.txt" as
4711
hello
beautiful
world
it produces the following analysis result on the standard output:
INTEGER '4711'
<INDENT> ''
IDENTIFIER 'hello'
<INDENT> ''
IDENTIFIER 'beautiful'
<DEDENT> ''
<DEDENT> ''
IDENTIFIER 'world'
<NODENT> ''
<TERMINATION> ''
Unicode and Codec Converters
The times when text is solely coded in ASCII are long times over. Nevertheless, many programming languages are centered around this codec. Would it not be nice to have mathematical operators such as '¬' and '≠', or greek letters for constants such as 'π' or 'ρ' as part of a programming language? This can be done by plugging converters to a Quex-generated analyzer. Quex comes with interfaces for the ICU and the IConv converter libraries. The minimalist example for Unicode might be specified as
mode PRIMER :
<skip: [ \t\n]> {
\G{Nd}+ => QUEX_TKN_INTEGER(Lexeme);
\P{ID_Start}\P{ID_Continue}* => QUEX_TKN_IDENTIFIER(Lexeme);
}
The above example also demonstrates how Unicode properties can be accessed and used in regular expressions. The \P{White_Space} matches anything in the Unicode character set that is considered white space. \G{Nd} matches any character within the general category 'numeric digit'. \P{ID_Start} and \P{ID_Continue} access the set of characters that may be used as identifier starters and identifier continue characters. For more information about the Unicode property mode, consider Unicode Technical Report #23.
For converters, the call to Quex needs some extra arguments. By means of "--iconv" or "--icu" the converter library is specified. To capture all Unicode characters, the buffer's element width is best chosen to four bytes, i.e "-b 4" should be given. Assume, we want to use the IConv library, we instruct Quex to generate an analyzer by
> quex -i converter.qx -o EasyLexer -b 4 <code>--iconv</code>
All that remains is to modify the driver code slightly. An additional argument tells the converter from which codec it needs to convert; Let it be UTF8.
...
quex::EasyLexer qlex(argc == 1 ? "example.txt" : argv[1], "UTF8");
...
On some systems "-liconv" must be added to the linker line (if it is not in the default arguments of g++) so that it pulls in the IConv library (ICU linker flags would be accessed by icu-config --ldflags). The compilation instruction becomes
> g++ -I. -I$QUEX_PATH lexer.cpp EasyLexer.cpp -o c-lexer -liconv
The resulting lexer c-lexer is now able to match numbers and identifiers from any character set. Consider an example file "converter.txt" with the content
١٤١٥٩ १४१५९ ๑๔๑๕๙ 大 schoen ยิ่งใหญ่
Running ./c-lexer converter.txt takes that input and delivers the result
INTEGER '١٤١٥٩'
INTEGER '१४१५९'
INTEGER '๑๔๑๕๙'
IDENTIFIER '大'
IDENTIFIER 'schoen'
IDENTIFIER 'ยิ่งใหญ่'
<TERMINATION> ''
The above example used UTF8 as input codec. However, any codec that is treated by ICU or IConv can be specified. The analyzer's codec is controlled by the last argument passed to the constructor of the analyzer. Passing "UTF16", for example, automatically lets the exact same analyzer run on "UTF16" coded files. Thus, the input codec can be modified dynamically without regenerating the analyzer itself.
Summary
The present article demonstrates with which extreme ease sophisticated functionality in lexical analysis can be accomplished using Quex. With a few lines of code a lexical analyzer is specified. A call to Quex produces the required source code. A small C++ program interfaces with the generated engine and receives the tokens found in the character stream. It was shown how to access line and column number information, how to implement an indentation based scope language, and how to treat character streams of arbitrary character encodings.
History
December, 2015: Initial Submission.

