Layout
- Introduction
- Representation of a mathematical sequence in programming languages
- Can a tree provide an efficient sequence?
- Level-linked perfect binary tree
- Rank algorithm
- Array representation with data compression
- Summation algorithms
- Applications
- Notes
Introduction
The standard sequential summation has linear running time. The algorithms discussed in this article compute a sum of consecutive elements in logarithmic time. They are general and can run on simple single-processor systems. Alternative parallel computations require supercomputers to achieve the same running time. However, even in an ideal machine with an infinite number of processors, the parallel summation has high linear computational cost in terms of the total number of operations.
There are several types of data structures that support fast summation algorithms with logarithmic running time. In this article, we consider a perfect binary tree, which can be represented as a linked structure of nodes and an array. The comparison of different representations helps better explain various aspects of fast summation algorithms.
The first interesting fact is that we arrive at the same summation algorithm, which was first proposed by Fenwick for the array representation of binomial trees [1]. The attractive features of this algorithm are the small size of code and the ease of writing the implementation. However, this advantage comes at the expense of the superficial simplicity. The implementation hides the idea behind the fast summation algorithm. It is not obvious how it works and what the limitations of the array representation are. This fact should not be surprising, since the algorithm was designed for data compression. Its implementation can be regarded as a "zipped" one.
Another interesting fact is that the same array representation can support not only the optimal, but also "unzipped" longer variants of fast summation algorithms, which are similar to those in linked trees of nodes [2]. The "unzipped" implementations can be used to illustrate the basic principles of fast summation algorithms. The description of these algorithms using only linked trees would require more space for code and explanation.
Representation of a mathematical sequence in programming languages
The summation algorithms are applied to sequences, which can store both ordered and unordered data sets. The fundamental property of a sequence is counting of elements for identification purposes. By definition, in a mathematical sequence each element is identified by its rank, which is the number of elements before that element. According to this definition, the rank of a given element in a sequence is a special sum of the same integer values 1. This fact suggests that fast algorithms for computing a partial sum and a rank of an element should be closely related to each other. Jumping forward, we can say that the former algorithm can be regarded as an extension of the latter algorithm.
The most widely-used representations of a sequence are based on arrays and linked lists. An array is the main basic data structure, which can represent a sequence in a user algorithm. Array-based containers are a good choice for many applications due to fast random access to elements through the subscript or index operator: value=array[index]. In the design and analysis of algorithms, the running time of this operator is considered to be constant. Another well-known data structure that can represent a sequence is a linked list. The linked structure of nodes in a list efficiently supports fast sequential processing only. Access to distant elements is slow: it has linear running time.
Can a tree provide an efficient sequence?
At first glance, it may appear that a sequence based on a linked tree is not a good idea. Most practical applications use balanced search trees, which store ordered data sets to guarantee the high efficiency of various operations. The elements in such trees are ordered by their keys. The rank of an element has no effect on the order, because it is not an inherent property of an element. It is an external label assigned to an element by a user algorithm. It also specifies position of the element in a container. The rank value depends on the key ordering. The efficiency of random access in an ordered tree is basically the same as in a linked list. That is why, unlike an array and similar to a linked list, a typical search tree does not support the subscript operator.
The efficient representation of a sequence uses a special type of linked tree. Improved performance of random access in these trees is achieved by applying the method of augmenting [3]. This method allows us to design and fine-tune algorithms through the insertion of new data to nodes of an existing data structure. An augmented tree can store several types of data sets for different algorithms. A tree that represents an unordered sequence supports only a fast rank algorithm, which is an alternative to the subscript operator in arrays. For an ordered sequence, an augmented tree provides two fast search algorithms by rank and by key. In this article, we discuss only unordered sequences. Random access to elements in an augmented tree is not as fast as in an array. It has logarithmic time, which is worse than constant time. However, logarithmic time is significantly better than linear time offered by basic search trees and linked lists.
The difference between the array and linked tree variants of a sequence can be summarized as follows. An array is equipped with the subscript operator directly supported by a programming language. A linked tree must provide a fast search method to access an element by rank. A tree stores not only elements of a given sequence, but also representation specific data. In terms of space and time efficiency, arrays are often superior to trees.
Level-linked perfect binary tree
In this article, we consider a level-linked variant of a binary tree, which is illustrated in Figure 1. The main data structure consists of square nodes connected by black links. In structural aspects, it is similar to a skip list. The additional tree of child-parent relationship, which is shown in green, is usually called a perfect binary tree. This tree is also a complete and full binary tree.
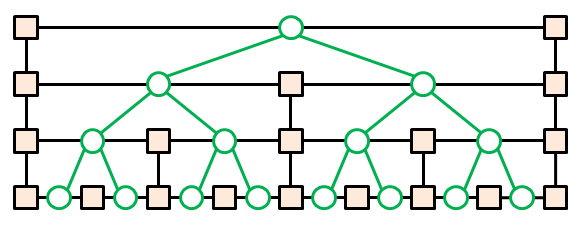
Figure 1: A level-linked perfect binary tree. The child-parent relationships are drawn in green.
For the algorithms discussed in this article, this type of tree offers important advantages. The set of links from any node to its parent, child and sibling nodes supports efficient traversal of the tree. The tree enables a geometric interpretation, which simplifies the illustration and explanation of summation algorithms.
Within the geometric model, the length of a horizontal link between two nodes represents a value stored in one of the connected nodes. A vertical link does not have a length for summation algorithms. The vertical links are responsible only for the connectivity of nodes at different levels. The summation operations and traversal of such a tree follow simple rules. Traversal of a horizontal link is equivalent to the addition or subtraction of a value, while traversal of a vertical link makes no contribution to an accumulated sum.
Figure 2 illustrates the main idea of fast summation algorithms. The length of one segment at an upper level of the shown tree is equal to the sum of lengths of many segments at the deepest level, which stores all of the elements of a given sequence. Although there are many ways to obtain the sum of consecutive elements at the deepest level, it is intuitively obvious that a fast method should use upper rather than lower levels of this data structure. The most efficient algorithm should use the minimum number of segments.

Figure 2: An illustration of top-down traversal of a level-linked binary tree. The path shown in red color is more efficient than the path in blue color.
We intentionally show no data in Figure 2 at this stage of the discussion. Even if a specific data set is quite complex, the efficiency of a fast summation algorithm depends primarily on the number of links on a path between the first and last nodes. The resultant value is computed by the summation of values in visited nodes.
Rank algorithm
The simplest of all possible data sets is the set of counts of sequence elements. Figure 3 illustrates such a data set using a tree, which stores in each node at the deepest level the integer value 1. The accumulated value of a count is shown in the right node of a horizontal link. Each such internal node in the tree is a parent of a sub-tree rooted at the node. Thus, a count in an internal node provides the number of consecutive elements of a given sequence in a corresponding sub-tree, which is equal to the number of elements in a range of the sequence. Note the simple and important property of a perfect binary tree that each count is a power of 2. The counts have the same value at each level of the tree.
Figure 3: A level-linked perfect binary tree with a data set of counts. The bottom line shows values of ranks of sequence elements, which are stored in nodes at the deepest level of such a tree.
The fast rank algorithm represents a top-down search for a node at the deepest level that contains a sequence element specified by its rank. The search involves addition operations on counts stored in internal nodes of the tree and comparison operations on an accumulated value against a given rank. Except for the use of the addition operation, the search is similar to the search by key in search trees. The path in red illustrates the search and computations on counts for the node with rank 5.
Array representation with data compression
As discussed earlier, array implementations of binary trees offer the advantage of better performance and space efficiency compared to data structures of linked nodes. The classical example of using such an efficient array implementation is a heap based on a complete binary tree. This approach can be applied to the level-linked perfect binary tree, but in this article it is interesting to consider a more space efficient array implementation.
The data compression method is based on the property that each parent stores a sum of values of its children. In such a binary tree, a value of one child allows us to find a value of another child. Thus, a fast summation algorithm can work even if a tree stores values of only one child. In addition to this, for the best performance, such an algorithm should avoid using second child horizontal links. This traversal can make a path longer compared to a path through suitable parents.
Figure 4 shows a tree with a reduced data set for the computation of a rank of a node at the deepest level. The tree stores all of the significant data in the first child of each group. All of the unused values in second child nodes are set to zero. The corresponding dotted links are not used by optimal summation algorithms. For comparison, the tree in Figure 3 has the same structure, but stores the complete data set.
Figure 4: A perfect binary tree with the minimal set of significant data. The counts of sequence values are shown in the binary representation. The path in red illustrates the optimal computation of rank 5.
The binary representation of counts helps illustrate the following aspect of the discussed algorithms. When the fast top-down rank algorithm passes through all of the levels of the tree, it produces exactly the same sequence of bits as in the binary representation of a specified rank value. Each visited level contributes to a result the value 1 or 0 in the binary representation. The example in Figure 4 provides for the integer 5: (0101) = 0x8 + 1x4 + 0x2 + 1x1 = 4 + 1.
Figure 5 illustrates how a conventional array, which stores an unordered sequence, can be converted to a compressed array that supports much faster summation. An input array is shown at the bottom. In order to simplify code, this array has the additional zero value at the first position. All of the array values are passed to nodes of the deepest level of a level-linked perfect binary tree. As the tree construction algorithm moves up, it computes for each parent node a sum of values of its children and decreases the number of nodes at a new level by a factor of 2. The significant values, which are written to a resulting compressed array, are stored in top nodes of vertical chains. All other pre-computed data are not used by optimal summation algorithms, but they are required for the construction of the tree. In terms of the geometric representation, the compressed array saves the lengths of solid horizontal links only. Dotted links are not traversed by optimal summation algorithms. Their lengths are not saved in the resulting array. In the algebraic form, given the sequence { a, b, c, d, e, f, g, h }, the compressed array stores the following sums: { 0, a, a+b, c, a+b+c+d, e, e+f, g, a+b+c+d+e+f+g+h }.
Figure 5: A diagram of the bottom-up construction of a compressed array using a level-linked perfect binary tree. Each node in this tree stores a count and a sum of the values of a range of sequence elements from the bottom array.
The resulting compressed array can be also viewed as a flattened level-linked perfect binary tree. It is achieved by removing 0 bit nodes (see Figure 4) from vertical chains of the tree. In the resulting array, each vertical chain of the linked tree is represented by a value in the top node, which is a 1 bit node in Figure 4. The number of vertical chains in the tree is determined by the number of values in a given sequence. Thus, all of the significant tree data can be saved in an array of basically the same length as the original sequence. The constructed array has only one additional zero value at the first position.
Summation algorithms
The compressed array representation supports a number of fast summation algorithms that mirror the computation of a rank in the binary representation. The comparative discussion of algorithms is based on the fact that in a perfect binary tree the level-linked structure of nodes with the minimal data set of counts matches the sequence of bits in the binary representation of a rank (see Figure 4). We start the discussion from the simple variant, which is equivalent to the top-down summation in a level-linked perfect binary tree. This algorithm is illustrated in Figure 2.
int sum_top_down ( const int k ) const
{
int sum = 0 ;
int count = 0 ;
for ( int bit = 1<<30 ; count < k ; bit >>= 1 )
{
if ( k & bit )
{
count += bit ;
sum += m_tree [ count ] ;
}
}
return sum ;
}
In short, this algorithm scans a sequence of bits of the binary representation of input rank k and extracts data from the compressed array m_tree to compute the sum of first k values. In more detail the algorithm works as follows. The code uses the variable bit, which is a power of 2 and has a single 1 bit during the execution of the algorithm. This test bit is initialized to the most significant bit of 32-bit integer (1<<30) and is shifted using the operation bit >>= 1 (division by 2). The operation (k & bit) is important to select for processing the correct data associated with the bits in the binary representation of the rank k. All of the computations of a result are performed when a current bit of k is 1. The variable count accumulates the number of first elements that have been processed. Its value is increased by the size of a current range of a given sequence count += bit. Simultaneously, a precomputed sub-sum of values of the same range is added to the result of this algorithm sum += m_tree[count].
Unlike a flat compressed array, a level-linked perfect binary tree has vertical dimension. The equivalent summation algorithm represents a top-down traversal combined with computational operations on data stored in nodes. The top level of the linked tree corresponds to the most significant bit in the size of the compressed array. No processing for a 0 bit of the binary representation of the rank k in a linked tree is equivalent to a vertical traversal that passes through a 0 bit node (see Figure 4). A 1 bit in the rank k corresponds to a traversal of a horizontal link in the linked tree. The algorithm uses the same two addition operations on count and sum, with the difference that values of both count and sum for a current range of sequence elements are stored in nodes of the tree (see Figure 5).
In the function sum_top_down(), the for loop stops when the comparison operation ( count < k ) returns false. It means that all of the elements in a given range have been processed and that the result can be obtained before the algorithm reaches the deepest level of a binary tree. Such an early exit is useful to improve the running time of this summation algorithm. If we implement the same top-down algorithm with the following condition in the for loop:
for ( int bit = 1<<30 ; bit > 0 ; bit >>= 1 )
then the algorithm visits all of the levels of a tree and terminates at the node of the deepest level referred to by the rank k. In terms of the array implementation, the algorithm tests each bit of the rank k and the summation of counts represents the straightforward computation of a rank in the binary representation.
The fast bottom-up summation algorithm in a level-linked perfect binary tree is possible only when a user algorithm provides a pointer to a node at the deepest level. Since the node is identified by a client and the search for a first node at upper levels is relatively simple, the main task of this algorithm is counting the number of processed elements. It computes simultaneously both a rank of the specified node and a corresponding partial sum. Its performance is the same as that of the top-down algorithm.
Unlike the linked tree of nodes, the array representation does not place a similar pointer to node restriction, since it can take advantage of constant-time access by rank to any element it stores. The code is similar to the previous algorithm:
int sum_bottom_up ( const int k ) const
{
int sum = 0 ;
int count = 0 ;
int i = k ;
for ( int bit = 1 ; count < k ; bit <<= 1 )
{
if ( k & bit )
{
sum += m_tree [ i ] ;
count += bit ;
i -= bit ;
}
}
return sum ;
}
The main difference is that this algorithm scans tree data in reverse order. Initially, at the deepest level, the index into array m_tree is equal to the input rank i=k. As the algorithm moves one level up, the index decreases by the size of a processed range i -= bit (a power of 2).
The array algorithms based on counting the number of processed elements are quite fast. Nevertheless, they are not optimal, since unnecessary tests for a 0 bit in the rank k increase the number of iterations and the running time. Thus, we may ask the following question: is it possible to devise a more efficient algorithm that addresses this issue? The affirmative answer to this question is the algorithm that was originally obtained by Fenwick for binomial trees [1]:
int sum_optimal ( int k ) const
{
int sum = 0 ;
while ( k > 0 )
{
sum += m_tree [ k ] ;
k = k & ( k - 1 ) ;
}
return sum ;
}
This algorithm looks amazingly simple, but not all of its details might be clear. It is similar to the sum_bottom_up() algorithm, since both algorithms process data in the reverse bottom-up order. However, it is not so trivial, since it represents a "compressed" variant of the first bottom-up algorithm.
The key feature of this algorithm is the bit operation k&(k-1), which removes the least significant bit in the binary representation of rank k. This algorithm offers the following advantages. The code does not require a special variable, such as count for sequence elements that have been processed. The bit removal operation subtracts the size of a current range and updates the number of elements to be processed. As an index into the array, the updated value of k provides a new position in the compressed array m_tree[k] for a next iteration of this algorithm. This new position is always valid, which explains why this algorithm does not test each bit in the input rank k.
The number of iterations in this algorithm is equal to the number of 1 bits only. Avoiding tests for a 0 bit provides improved performance compared to other summation algorithms discussed above. In the algorithm sum_bottom_up(), which tests each bit in the rank k and counts processed elements, the number of iterations is determined by the position of the most significant bit in the input rank k. In the worst performing algorithm that tests each bit, the number of iterations is constant and is equal to the total number of bits in an integer type used by the algorithm.
In the general context of algorithms on linked trees, the variants of fast summation discussed here are based on shortest path algorithms. This fact may not be obvious for the level-linked perfect binary trees shown in figures of this article. The vertical traversal of useless 0 bit nodes has a measureable contribution to the total running time when the number of elements in a sequence is small. The performance benefit of using a shortest path for computations is more evident in a tree with a large number of children, such as a level-linked B+ tree [2].
The compressed array representation has the important advantage of constant-time access to a required element through the computation of its position. This advantage allows us to optimize the number of iterations in the fast summation algorithm and make it equal to the number of 1 bits in the binary representation of the input rank k. For the level-linked perfect binary tree, this optimality is impossible. It requires finding a shortest path that uses the minimum number of horizontal links only. However, a shortest path algorithm cannot avoid traversal of vertical links and visits of nodes that store a 0 bit. The fundamental limitation of the level-linked tree is that it provides fast access to neighbors of a given node only.
Applications
The fast summation algorithms are useful in many practical applications, particularly in large databases, big data and data science. They enable very efficient computation of important statistical parameters: mean values and standard deviations. The linear performance of the summation algorithm using a normal array is insufficient for such applications. This issue can be addressed with an array of pre-computed partial sums, which guarantees constant time of computing the sum of any consecutive elements. However, this array is too slow for the update operation that modifies the value of an existing element. In an array of prefix sums, it has linear running time, whereas in a normal array, it is a constant time operation. Each of these arrays has one inefficient operation that can cause a degradation in overall performance. The compressed array representation offers both the efficient summation and the efficient update operation. Despite this advantage, the compressed representation has a number of limitations that can make its use sub-optimal in some applications.
The insertion and erasure operations, which change the number of elements in a data set, require quite costly re-computation of the whole array, except for two operations: appending an element to the end of the array and removing the last element. The compression removes every second element of an original data set. Thus, either a copy of the original data set should be stored by a user algorithm, or each removed element should be re-computed as the difference between sums sum(k) - sum(k-1). The need for the re-computation of original data may lead to nontrivial issues. The high efficiency of this re-computation requires an inverse operation, which may not exist in some cases. In particular, the running time of the computation of minimum and maximum values in any range of elements is considerably worse than that of sum, mean value and standard deviation.
The limitations of array representations are usually addressed with augmented trees. In applications, which require a wide range of efficient insertion and erasure operations, the primary choice is a B, B+ or red-black tree. The article on semigroup in C++ explains how one data structure can be used to compute sums, minimum and maximum values with the same logarithmic running time.
Notes
There are numerous internet resources with different depths of descriptions of the compressed array representation. The various aspects of these and related data structures are discussed in articles on Fenwick tree, binary index tree, binomial tree and segment tree. Unfortunately, differences in terminology are a complicating factor in understanding these interesting data structures and the algorithms they support. Perhaps the main source of confusion is the use of the term "tree". Normally, this term denotes a container, which stores a data set. In addition to this, tree structures are used for illustration of the dynamics of algorithms. In the present article, the trees shown in figures represent containers for data sets. The dynamics of operations is illustrated with arrows parallel to links.
Another potential issue of the compressed array representation is associated with the additional zero value at the first position. This approach makes the representation of a given sequence 1-based. A 0-based array implementation does not use an additional element. The code, which combines 0- and 1-based array implementations, is not safe. It will lead to errors in a user algorithm.
References
1. P.M. Fenwick. A new data structure for cumulative frequency tables. Software-Practice and Experience, 24(3), pages 327-336, 1994.
2. V. Stadnik. Fast Sequential Summation Algorithms Using Augmented Data Structures. arXiv:1404.1560, 2014. (http://arxiv.org/abs/1404.1560)
3. T.H. Cormen, C.E. Leiserson, R.L. Rivest and C. Stein. Introduction to Algorithms. Second Edition, MIT Press and McGraw-Hill, Cambridge (MA), 2001.

