Introduction
This article presents a benchmark application which pits the red-black binary tree containers(map, set, etc.) against hash containers. This article is not a tutorial on the data structures. For more information on how a red-black binary tree works, you can refer to this Wikipedia link. For hash containers, you can read this excellent Codeguru article by Marius Bancila.
Red-black binary tree is a very fast search tree data structure: it can find any item in 4 billion items in 32 steps or less. Its O notation is O(log2n) while hash container's average case is O(1) and its worst case is O(Total number of elements). The only time the hash container's time-taken-to-search is not O(1) is due to the searched item sharing the same hash with other different item(s) and the hash container has to compare them one-by-one to find an exact match. For more information on the performance comparison, look at this Boost library link.
Benchmark
For the map and multimap benchmark, the key in key-value pair is a word(string) in English dictionary while the value in key-value pair is a random number. This is okay because the value is not used in the search. For the set and multiset benchmark, the element is a word(string) in English dictionary. Set is a data structure similar to map without the value pair. The multimap and multiset, unlike map and set, allow the same key/element to be insert more than once and doesn't enforce the uniqueness. The reason I use std::wstring for the key/element is because hash containers have a predefined hash function written for std::wstring. If I use my own custom data types, I may have to write my own custom hash function.
For map, multimap, set and multiset insertion, I called the insert method. For multiset and multimap insertion, I insert the same item twice. For map and set search, I called the find method. For multiset and multimap search, I used equal_range method.
For the benchmark, we will benchmark STL, legacy hash container(more on this later), Visual C++ 10 unordered containers and Boost 1.44 unordered containers. Legacy hash containers which I have just mentioned exist in the stdext namespace since Visual Studio 2003. We will benchmark them as well to see how they fare against the C++0x unordered containers. By the way, in case you are not aware, C++0x and Boost hash containers are called unordered_xxx(eg, unordered_map). The benchmark application will populate the containers before running the benchmark if it hasn't been populated but population time is not included in the benchmark results. The reason I did not benchmark the container population is that I found the population to be quite fast.
The benchmark used a random number to index into the std::vector for an item(string) to search in the above containers. You can change the random number generation seed in the benchmark application.
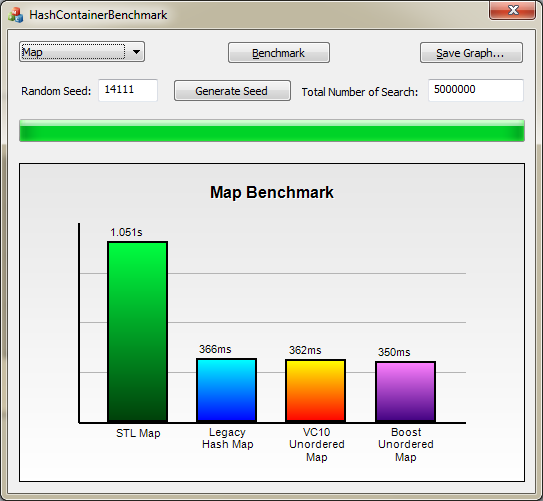
Map Benchmark
The benchmark is done over 5 million searches. The lower the score, the better it is.

We can see that the hash containers performs 2 times better than STL map. The timing for the hash containers are roughly the same.
MultiMap Benchmark
The benchmark is also done over 5 million searches. The lower the score, the better it is.
We can see Boost unordered_multimap timing is 4 times better than STL multimap.
Set Benchmark
We can see that the set benchmark results are similar to the earlier map results.
MultiSet Benchmark
We can see that multiset benchmark results are similar to the earlier multimap results. As we can see, the hash containers consistently outperform their red-black tree equivalents, we may be tempted to use the hash containers in our code. For most cases, the hash containers are a drop-in replacement for their red-black tree equivalent except some methods may be missing and it is required to write hashing function for your custom data type. For example, when you get their iterators, they are unordered unlike the red-black tree versions. You have to investigate their difference yourself.
Building Benchmark Application
Please build the application in release mode. The debug build application runs too slowly. The readers have to download Boost 1.44 and point your Visual C++ 10 include path to Boost 1.44 if you haven't had Boost library on your development machine.
Benchmark Framework
The application is a benchmark framework; Each benchmark test suite is a self-contained Win32 DLL. The benchmark application will load all DLLs with certain function signatures on startup. For some reasons, you want to add your own benchmark DLL (for example, you want to benchmark SGI hash container) to the application folder, the benchmark application will pick it up as well. There is virtually no limit on the number of DLLs you can add. Of course, the more you add, the benchmark time gets longer, and the graph's bars get thinner. To write your own benchmark DLL, just create a new Win32 DLL project and copy source code from any of the existing DLLs. You could just change the included headers to the new container headers which you want to benchmark and you may have to change the container class names as well. There you go, you have a new benchmark DLL. The sequence in which the DLLs are benchmarked is according to GetIndex().
- STL DLL
GetIndex() returns 5. - Legacy Hash DLL
GetIndex() returns 10. - VC10 unordered DLL
GetIndex() returns 15. - Boost unordered DLL
GetIndex() returns 20.
So to insert your own DLL in front of other DLLs, your GetIndex() should return between 1 and 4.
Conclusion
I welcome any feedback(good or bad) as to how I am doing this benchmark correct or wrong and how I could improve it. If my benchmark is not a good representation of how the data search is used in the real-world scenario, please let me know as well. I wrote this article not to teach but to learn from my readers who are far better programmers than I am. Thank you for reading!
A word of caution: Using string key in unordered_map for millions of records increase the probability of collisions, may result in worse performance than STL map. See link.
History
- 8th September, 2010: Initial post
- 28th December, 2010: Source code and binary (attached) are updated to fix an integer (calculation) overflow bug for progressbar if the user specifies > 50+ million searches for the benchmark

