Introduction
Ever wondered how that architecture diagram related to the source code? Ever looked at the source and really wondered? Have you looked at a file dependency graph and wondered what the point was given all the spaghetti? Then maybe you need an Architecture Development Environment (ADE). There are numerous ones on the market (Structure101, Lattix, NDepend, etc.) however this article describes another one; but why write yet another solution? The answer is dissatisfaction with the diagrams being drawn by the existing solutions.
What makes an ADE different from just another diagram of dependencies is that it associates a hierarchy which isn't necessarily that of the file system path, namespace or other artefact of the source code. Initially the software used the filter file associated with a Visual C++ project (for which there is an example that is subsequently refactored); subsequently the software has been generalised to just scan a directory, and then to read the output from a make command - in both cases the user must manually specify a set of filters. The first of these generalisations can be used to show the structure of the software itself, the latter was implemented to process the source of the Linux kernel.
The software implementation, written in Python, uses plug-ins to provide functionality. These plug-ins are loaded and executed by processing a JSON file. For output the options are:
- doxygen - create input for Doxygen/DoxyPress
- track - append the metrics to a file
- dependencies - save a JSON file containing the state from one of the other input options
For input the options are:
- visualstudio - reads a Microsoft Visual Studio solution file for C/C++ source and filters
- generic - traverses a directory structure for source
- maken - read the output from "make -n" or "make V=1"
- dependencies - read a saved JSON file containing the state
Different programming languages are supported, C/C++, C# and Python, as is additional processing. The source for various examples is provided in the repository.
Background theory
A graph is made up of nodes and the edges that connect them, in a directed graph the edges have a direction. Rather than being represented as a diagram, a graph can be represented by a matrix called a structure matrix. If there is a lack of cycles, then the order of the rows can be chosen so that the non-zero entries lie on one side of the diagonal.
Given that a graph has N nodes, E edges and P parts (the different parts of a graph have no edges connecting them to other parts) then cyclomatic complexity may be defined as E + P - N. For example, in a strictly layered architecture E + P - N = 0 and for complete mud the number of edges is twice the triangle number of N. i.e. E + P - N = N * N. Thus 0 <= (E + P - N) / N <= N. Note that this formula is invariant under code transforms that split a node into two connected by only one edge.
Visualising with Doxygen
Structure matrix
Firstly, the script calculates the structure matrix for the filters that contain files and attempts to order the rows so that the matrix is lower triangular. Note that the columns are in the same order as the rows and that the diagonal elements are denoted by a slash.
Linear\Algebra \
Linear\Solvers 1\
Tests\Utils \
Tests\Linear 111\
FEA\Core\Elements 1 \ 1
FEA\Core\Fields 1 1\
FEA\Assembly 1 11\
FEA\Core\SetOfElements 11 \
FEA\Surface 1 1\
FEA\Equations 1 11 11\
FEA\Mesh 1 11 \
FEA\FileIO 1 11 11 1\
Tests\Classes 1 11 11111\
FEA\Solver 11 111 11 \
Tests\App 1 11 1 11111\
App 1 11 11 1 \
In this case the presence of a cycle in the FEA group stops the matrix from being ordered into a lower triangular form.
Table of metrics
The script then combines the filters into a tree structure. For example, FEA\Core is created with 3 children given as Elements, Fields and SetOfElements.
Then it calculates the values of N, E + P - N and (E + P - N) / N for each of the tree nodes and creates a table sorted in (E + P - N) / N.
Graphs
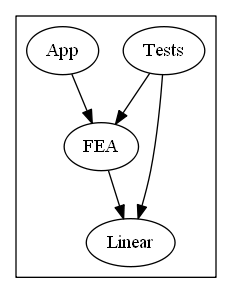
Each of these branches of the tree creates a new section in the HTML document. For example, at the top level, the script creates an input file for GraphViz to create the first diagram. Each of the nodes is hyperlinked to the appropriate section in the document. The script also calculates E + P - N as being 1 in this case.

The second diagram shows the FEA subsection and a problem in the architecture is evident. The dependence of FEA\Surface on FEA\Core creates a cycle in the graph, i.e., A circular dependency exists. The associated section of the HTML document also displays the value of E + P - N as being 8 and additionally states that FEA itself is dependent on the Linear Algebra library.
Finally, in the third diagram, we show a leaf node, i.e., one which consists of the inter-dependencies of files. Note this is not the usual spaghetti that one would expect to be displayed as we are only displaying a small number of files.
Tracking the metrics
As has been noted the value of E + P - N equals 0 for simple graphs, thus it is useful to track the sum of this metric over all the graphs generated off the source code. The script tracks this along with the maximum value and both values normalised by N.
The script plot.py plots the tracked values. For the code which the example is based on the output is given in complexity.txt. It is to be noted that the comments do mention the removal of unnecessary include files and the changing of filters.
As can be seen from the above diagrams that the effect of refactoring the code is not a monotonic reduction in the metric. Their utility lies in monitoring the long term trend.
Discussion
The Visual C++ example
Significant refactoring took place for the FEA::Core::Elements (original, refactored) filter of the example.
ElementShape was split off from IntegrationRule which was then grouped separately without creating a circular dependency at the next level up. i.e. the single responsibility principle of SOLID was applied.
There was also a factory implemented in ElementHandler that was separated out into ElementFactory and again moved into its own group without creating a circular dependency at the next level up. The effect of this was to bring out an uncluttered inheritance tree for ElementHandler. i.e. The diagram is now consistent with the design intent. It should be noted that this particular mistake may already be classified as an anti-pattern.
The applications own source
Within the Python source code unnecessary (in the context of dynamic typing) import statements are used so that correct dependency structure can be determined.
The Linux kernel
As a stress test the software was run on the Linux kernel 4.6 source code. Obviously there were no pre-existing filters, rather a large number of files and the classical split of an include directory to separate the general header files from the source. This latter point is significant as the whole contents of the include directory need to be redistributed so that the structure of the kernel source code can be determined.
The Boost 1.61 library
This C++ library was chosen for illustration because it used to be a header only library that caused a lot of pain due to the huge number of dependencies that were required when wanting to use just one little header file. In its modern form it uses some macros to define include files and thus when reading the source code these macros had to be substituted appropriately.
The Mono.Cecil library
This .NET library was chosen as an example simply because the tool that reads its assemblies uses it. As the tool doesn't read the source files it creates a tree with leaves corresponding to interfaces and classes and branches corresponding to the namespaces.
Conclusions
A tool for generating interlinked hierarchical architecture diagrams and associated metrics has been developed and shown to produce a clearer understanding of the state of a particular Visual C++ project. To the extent that that code base was refactored to a more flexible state. The tool is highly extensible due to its plug-in architecture and has been generalised to work on Python source, the Linux kernel and general input.
For the main example given, sustainability is enhanced by utilising Visual Studio as the GUI for grouping files together rather than having to separately specify a set of filters.
History
- 2016/05/10: First release
- 2016/05/24: Updated the script to hyperlink into the source code, change the complexity metric and produce the table of metrics. Added a link to demonstration on YouTube.
- 2016/05/29: Added scripts for tracking and for processing the Linux kernel. Modified the main code so that files and groups of files can exist at the same level. Removed the HTML output from the zip and referred the reader online. Subsequently enhanced the discussion given the new data.
- 2016/06/16: Refactored the tool, uploaded it to GitHub and rewrote the beginning and end of the article.
- 2016/07/07: Added discussion of Boost and .NET

