Introduction
This article covers:
- Extracting data, and performing GET/POST submissions using
HTTPWebRequest and HTTPWebResponse.
- Parsing regular expressions through RegEx. This toolkit has two parts:
- An extensible library for extracting and submitting forms.
- A tool that implements the library, so that a user can interact with tags in a form directly.
This is a toolkit that provides a simple HTML parser in order to allow the user to interact with web based forms. There are two parts to this toolkit.
- An extensible library that can perform simple HTML parsing as well as form extraction and submission. There is also an extensible object that forms an adapter with a
DataSet and web based information. An implementation is given for inserting information in a simple table into a DataSet.
- A form extraction tool that implements the library. This tool allows the user to extract information from web based forms. This tool displays all the form tags as well as all the tags inside the form tags. Furthermore the submission method and the URL of each form tag is displayed as well. The user can change the values and attributes of any of these tags and submit it to see the results.
The whole thing started as an experiment, a proof of concept of sorts before I started doing some data extraction. Since I implemented quite a bit of functionality, and experimented quite a bit, I figured somebody might benefit from my folly :). This is not the fastest or the most elegant solution, but it probably is one of the simplest complete C# solutions. If you want an even simpler solution you can use the WebControl, but that's a topic of another write up.
Background
- A post using the HTTPWebRequest/Response (MSDN article)
- HTTP Web Request class (MSDN)
- Get vs. Post, what's the difference
- Form tags (W3 standards)
- Regular expressions in C#
Extracting data from a web page
The main functionality of this program depends on extracting and submitting data to a web server. To do this the HttpWebRequest and the HttpWebResponse objects are used. This is how it's done, quite simple really:
public void getUrlData(String url)
{
conn = url;
HttpWebRequest myHttpWebRequest =
(HttpWebRequest)WebRequest.Create(conn);
HttpWebResponse myHttpWebResponse =
(HttpWebResponse)myHttpWebRequest.GetResponse();
Stream receiveStream = myHttpWebResponse.GetResponseStream();
Encoding encode = System.Text.Encoding.GetEncoding("utf-8");
StreamReader readStream =
new StreamReader( receiveStream, encode );
page = readStream.ReadToEnd();
}
Submitting data to a form (POST and GET)
The other part to this tool is submitting the data. There are two ways of doing this; GET and POST. The link I have provided above gives you a detailed explanation, but as far as programming is concerned GET is encoded in the URL while POST is in the HTTP body.
The values are passed using key value pairs. They are passed in the format:
name1=value1&name2=value2
For a GET request the values are passed in the format:
URL?name1=value1&name2=value2
Keep in mind that the names and values must be encoded according to the standard. Certain characters (space etc.) must be passed as ASCII value between the two % signs. Read the standard for more info. Now for the code:
The simplest of the two to implement is the GET. So, here it is:
public string postURL()
{
else
{
webreq =
(HttpWebRequest)WebRequest.Create(this.formurl+"?"+valpairs);
}
res= (HttpWebResponse)webreq.GetResponse();
Stream receiveStream = res.GetResponseStream();
Encoding encode = System.Text.Encoding.GetEncoding("utf-8");
StreamReader readStream = new StreamReader( receiveStream, encode );
return readStream.ReadToEnd();
}
And now for the POST. Since POST requires the data in the HTTP header a little bit of ASYNC talk has to happen. I got it off the MSDN article I posted in the background section. This is the top bit of the method posted above and a bit more.
public static ManualResetEvent allDone =
new ManualResetEvent(false);
private static byte[] b;
public string postURL()
{
if(formurl==null) return null;
HttpWebRequest webreq ;
HttpWebResponse res;
string valpairs="";
IEnumerator i= valuelist.Keys.GetEnumerator();
while(i.MoveNext())
{
ValueNameTag v=
(ValueNameTag)valuelist[i.Current];
v.SetNVPairs(ref valpairs);
}
if(!Regex.IsMatch(formmethod,"get",
RegexOptions.IgnoreCase))
{
ASCIIEncoding encoding=new ASCIIEncoding();
b = encoding.GetBytes(valpairs);
webreq =
(HttpWebRequest)WebRequest.Create(this.formurl);
webreq.ContentLength=b.Length;
webreq.Method = this.formmethod.ToUpper();
webreq.ContentType=
"application/x-www-form-urlencoded";
webreq.BeginGetRequestStream(
new AsyncCallback(ReadCallback), webreq);
allDone.WaitOne();
}
else
{
webreq = (HttpWebRequest)WebRequest.Create(
this.formurl+"?"+valpairs);
}
res= (HttpWebResponse)webreq.GetResponse();
Stream receiveStream = res.GetResponseStream();
Encoding encode =
System.Text.Encoding.GetEncoding("utf-8");
StreamReader readStream =
new StreamReader( receiveStream, encode );
return readStream.ReadToEnd();
}
private static void ReadCallback(
IAsyncResult asynchronousResult)
{
HttpWebRequest request =
(HttpWebRequest)asynchronousResult.AsyncState;
Stream newStream=
request.EndGetRequestStream(asynchronousResult);
newStream.Write(b,0,b.Length);
newStream.Close();
allDone.Set();
}
Parsing the tags
The data that is read from a web page is read as a text stream. Since each tag needs to be manipulated, the tags must be extracted from the stream. The solution is regular expressions and the RegEx object/toolkit.
Here is a simple example:
public class TextAreaTag : Tag
{
string parsestring=@"<\s*textarea[\s|\w\|=]*>";
public override ArrayList GetValueTags(String page)
{
ArrayList vals= new ArrayList();
Match m = Regex.Match(page,parsestring,
RegexOptions.IgnoreCase);
while(m.Success)
{
string name =@"name\s*=\s*"+'"'+@"(\w+)"+'"';
string curr = m.ToString();
Match name_match = Regex.Match(curr,name,
RegexOptions.IgnoreCase);
ValueNameTag tg;
if(name_match.Success )
{
tg =
new ValueNameTag(name_match.Groups[1].ToString(),
TagTypes.TEXTAREA);
}
else
{
throw new SystemException("Incorrect " +
"Area tag no name found", null);
}
vals.Add(tg);
m.NextMatch();
}
return vals;
}
}
There are probably better ways to write the expressions. I just found it easier to break up the whole thing into segments.
The design
We have figured out how to extract data, submit data, parse data and now what remains to be done is to put it all together.

The premise behind the design is that an HTML page can contain many FORM tags. The FORM tag in turn contains fields that describe the form. The HTMLSet is the facade to this whole setup. It also holds a list of FORM tags. The user is able to interact with these FORM tags by getting a reference (an instance) of one of the FORM tags in the HTMLSet. Each tag inside a form is stored as a ValueNameTag no matter what type it is. The ValueNameTag does hold an enumerated type that describes what type it is.
The builder pattern is used to generate the ValueNameTags. Each tag that inherits the Tag class contains information on how the specified HTML tag is parsed and how the ValueNameTags should be generated. Note that the Input tag can be used to describe many tag types (see W3 standards above).
The tool
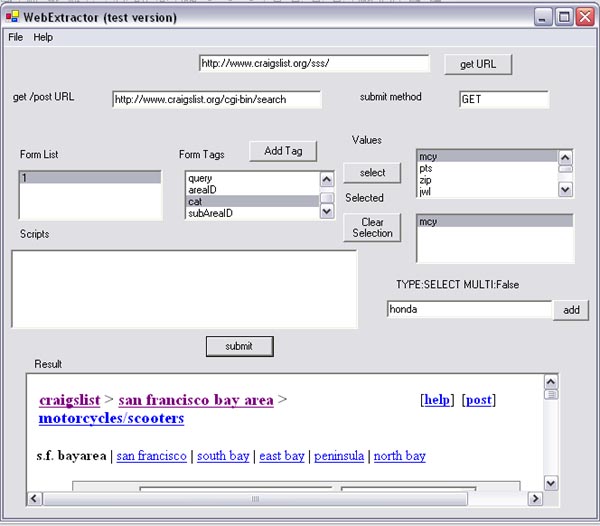
The Web Extraction tool implements the library that was discussed earlier. Below is a screenshot of it:
In order to interact with a web site, enter the URL into textbox (1) and click on submit. Once the web page is parsed the tag information will be displayed. Select a FORM tag from ListBox (6) and the tag information for that page will be displayed in ListBox (7). If a tag is selected in ListBox (7), the value information will be displayed in boxes 9 and 11.
To set a value for tag, select the form, and then the tag. Then, either select the value from the value list in textbox (9) and click the select button, or add a value to the value list by typing in the value to textbox (13) and then click on the add button. The values that are selected are displayed in box (11). Please note that multiple values are only allowed if the tag is specified as multiselect (see the standards).
Once the values are set, select the desired form from box (12), and click the submit button (15).
Note that the JavaScript in the form (except listeners) is displayed in box 12. It helps to figure out why certain pages won't work.
Points of interest
I just want to point out that I don't format the values according to the standard (replacing spaces with the ASCII values and such), but it still seems to work. I am not sure if it really works for all web pages but because it worked when I tested I have been too lazy to implement the formatting.
If you experiment with the program, you will begin to realize that certain pages don't work (dice for example). Most of the time this is because there are JavaScripts involved that manipulate the values submitted. The solution for this is to use the WebControl (IE DLLs) to submit the form.
Conclusion
Oops for some reason, links to the source and executable didn't work. Apologies.
Home page

