Concurrency is everywhere.
J. Duffy. "Concurrent Programming on Windows"
Introduction
Parallel processors are now widespread on all kinds of mainstream devices. Even if your device contains only processor, a hundred to one is multicore in its architecture. The benefits of parallel computing are obvious: reducing lead time.
But providing us with the opportunity to decompose an operation into constituent parts so that independent parts can run on separate processors (cores), multitasking creates new set of problems: synchronization of separate tasks. Used shared resources must be protected against the simultaneous modification by the parallel tasks. Such modifications must be serialized. In case of separate tasks, use and modify some shared resources developer must create a tasks communication protocol to prevent shared resources damage.
Concept
Hereinafter, I'll discuss my approach to user-mode application threads synchronization. Since Windows 95, we have a set of syncronization objects: critical sections, events (notifications), mutexes, semaphores. We can check the state of all of these objects (signaled or nonsignaled) any time it's needed. But in many cases, shares resources can be in 3 (three) states: unused, reading and writing. As you can understand, unused state means resource can be read or written, reading state means resource can read (by several threads simultaneously) and writing means only thread owns resource and modifies it. All other threads expect resource state changing. Since Vista, we have slim reader/writer (SRW) lock (with condition variables) objects that give us the possibility to synchronize resources with shared (read) and exclusive (write) states. But:
- we can't examine state of such objects (there are no functions like
TryEnterExclusiveMode or TryEnterSharedMode in Windows). Thread can only wait for enter shared or exclusive mode; - we can't introduce priorities for read and write operations;
- we can't change recursion call behavior strategy.
Why it is important ?
Let's imagine you implement some sophisticated algorithm that renders some quirk data structure (graph for instance) in memory. Every node is created in allocated memory. All nodes sizes are different. As soon as node is created and embedded in structure by thread, any other thread can read and modify it, i.e., node can be reallocated or even released. What memory model will be preffered? Obviously, using only memory heap is not good idea. In concurrent enviroment, you must use serialization on the heap. And these will bring to naught
of use parallel threads. Better way is to use several heaps to allocate nodes, so every thread from threads' set can check heap's state to pick up other may be unused heap. All these can be applied to nodes. In any time, every node can be unused, read or written to. Naturally, if a particular node is important for thread's control flow, it must wait for this node state changed. But if thread is looking for unused node by some criteria, used nodes can be skipped. So you have to use synchronization objects with satisfying properties.
Mechanics
Above all things, objects are state machines. So you have to define states' set of such objects. But content of this set depends on strategy will be used. Below I suggest my own approach in this topic. Obviously only thread can own synchronization object while it changing state. All other threads must wait while object state changing. In other words, all object's state queries must be serialized in time. Second but not less important is level of atomicity. Atomicity of synchronization object is obvious: states are atoms, state chaging performes in their entirety or not at all. But inside object atomicity is depend on enviroment, i.e. system, atomicity. Windows offers a plethora of "interlocked-" functions that ensure that operations are performed atomically. So I propose use them
(in respect with restriction of data alignment).
I start with simplest sychronization object type - critical code(section, monitor etc.) For such object will be 3 states: acquired, released and maintenance (as I call this state):
typedef enum
{
lsAcquired,
lsReleased,
lsMaintenanceMode
}
LATCHSTATE;
Maintenance mode means that some thread querying or changing state of object. So my simpliest synchronization object interface is follow:
class __declspec(novtable) ISyncLatch
{
public:
virtual void Acquire(void) = 0;
virtual void Release(void) = 0;
virtual BOOL TryAcquire(const DWORD dwMilliseconds) = 0;
};
Yes, all like as classic critical section. And follow is implementation:
class CLatch : public ISyncLatch
{
private:
DWORD mf_dwOwnerThread;
volatile __declspec(align(16)) LATCHSTATE mf_LatchState;
...
public:
...
virtual void Acquire(void);
virtual void Release(void);
virtual BOOL TryAcquire(const DWORD dwMilliseconds);
};
First of all we need to query object current state:
LATCHSTATE LatchState;
LONG lnSpinSwitchCount(0);
while (lsMaintenanceMode == (LatchState = static_cast<LATCHSTATE>(::InterlockedExchange(reinterpret_cast<volatile LONG*>(&mf_LatchState), lsMaintenanceMode))))
{
if (lnSpinSwitchCount < THREAD_WAIT_SPIN_COUNT)
{
::YieldProcessor();
lnSpinSwitchCount++;
}
else
::SwitchToThread();
}
As you can see, this is simple way to atomically change object's state to maintenance mode. If object is already in it, I do not change anything. Current object's state is stored in local LatchState variable. Here you can see Acquire() method implementation:
virtual void Acquire(void)
{
LATCHSTATE LatchState;
do
{
LONG lnSpinSwitchCount(0);
while (lsMaintenanceMode == (LatchState = static_cast<LATCHSTATE>(::InterlockedExchange(reinterpret_cast<volatile LONG*>(&mf_LatchState), lsMaintenanceMode))))
{
if (lnSpinSwitchCount < THREAD_WAIT_SPIN_COUNT)
{
::YieldProcessor();
lnSpinSwitchCount++;
}
else
::SwitchToThread();
}
if (lsAcquired == LatchState)
{
if (::GetCurrentThreadId() != mf_dwOwnerThread)
{
::InterlockedExchange(reinterpret_cast<volatile LONG*>(&mf_LatchState), LatchState);
::SwitchToThread();
}
else
{
::InterlockedExchange(reinterpret_cast<volatile LONG*>(&mf_LatchState), LatchState);
return;
}
}
}
while(lsAcquired == LatchState);
mf_dwOwnerThread = ::GetCurrentThreadId();
::InterlockedExchange(reinterpret_cast<volatile LONG*>(&mf_LatchState), lsAcquired);
}
You can change recursion acquire strategy as you need: skip it (as I did it), increase recursion count (as in native critical section) or throw exception for instance (i.e. emulate SRWLock). Choose way you need. mf_dwOwnerThread member is needed to define recursive calls. In Source code you can examine this object instance. In this way it's possible to emulate events, notifications (manual reset events) and semaphores.
Now lets implement synchronization object with shared and exclusive modes, i.e. "multi reader - exclusive writer" design pattern. Here states' set is:
typedef enum
{
lmUnused,
lmAnalyzed,
lmReadMode,
lmWriteMode
}
LOCKMODE;
Synchronization object interface:
class __declspec(novtable) IMultiReadExclusiveWrite
{
public:
virtual void BeginRead(void) = 0;
virtual void BeginWrite(void) = 0;
virtual void EndRead(void) = 0;
virtual void EndWrite(void) = 0;
virtual BOOL TryBeginRead(void) = 0;
virtual BOOL TryBeginWrite(void) = 0;
virtual BOOL IsReadBegan(void) = 0;
virtual BOOL IsWriteBegan(void) = 0;
virtual int WaitingReadCount(void) = 0;
virtual int WaitingWriteCount(void) = 0;
virtual int ActiveReadersCount(void) = 0;
};
This object implemetation test is in Source code. Result of test may looks like:
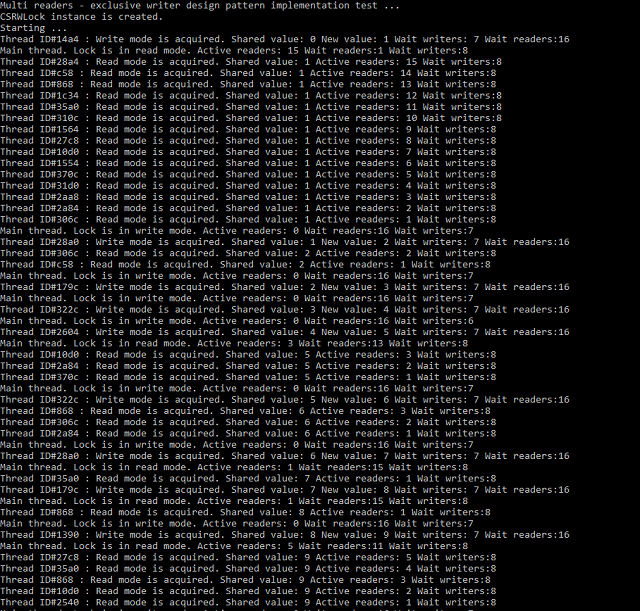
And last, most sophisticated and powerfull synchronization object is "multi reader - exclusive writer" with "upgradebale read" mode. It means the thread that owns object in "upgradable read" mode can upgrade it state to write mode or downgrade to read mode atomically. States set for this object is the same as for previous one, but interface is changed:
class __declspec(novtable) IUpgradableMultiReadExclusiveWrite
{
public:
virtual void BeginRead(void) = 0;
virtual void BeginWrite(void) = 0;
virtual void EndRead(void) = 0;
virtual void EndWrite(void) = 0;
virtual BOOL TryBeginRead(void) = 0;
virtual BOOL TryBeginWrite(void) = 0;
virtual void BeginUpgradableRead(void) = 0;
virtual BOOL TryBeginUpgradableRead(void) = 0;
virtual void EndUpgradableRead(void) = 0;
virtual BOOL IsReadBegan(void) = 0;
virtual BOOL IsWriteBegan(void) = 0;
virtual int WaitingReadCount(void) = 0;
virtual int WaitingWriteCount(void) = 0;
virtual int WaitingUpgradeCount(void) = 0;
virtual int ActiveReadersCount(void) = 0;
}
In "upgradable read" mode it's possible to build such code:
BOOL fbWrite(FALSE);
Lock.BeginUpgradableRead();
__try
{
...
ReadSharedResource(...);
...
if (SomePredicate)
{
Lock.BeginWrite();
fbWrite = TRUE;
...
WriteSharedResource(...);
...
}
}
__finally
{
if (fbWrite)
Lock.EndWrite();
else
Lock.EndUpgradableRead();
}
You can implement your strategy for readers and writers threads in your synchronization object, can introduce priorities for operations etc.
Now it's time to discuss the negatives of this approach. If you run this object implementation test from Source code, you can see huge latencies while code running. In reality as you can see a lot of threads are receive it's time slice only for invoke SwitchToThread() function. If you run Source code, you will see the price we payed for this approach. First of all, I modify code for very beginning object implementation:
while (lsMaintenanceMode == (LatchState = static_cast<LATCHSTATE>(::InterlockedExchange(reinterpret_cast<volatile LONG*>(&mf_LatchState), lsMaintenanceMode))))
{
if (lnSpinSwitchCount < THREAD_WAIT_SPIN_COUNT)
{
::YieldProcessor();
lnSpinSwitchCount++;
}
else
SpinOnce();
}
And introduce two new methods:
void CSpinWaitingLatch::SpinOnce(void)
{
switch((::InterlockedIncrement(reinterpret_cast<LONG volatile*>(&mf_lnSpinSwitchCount)) - 1) % 3)
{
case 0:
::SwitchToThread();
break;
case 1:
::Sleep(0);
break;
case 2:
::Sleep(1);
break;
}
}
void CSpinWaitingLatch::WaitOnce(void)
{
::InterlockedIncrement(reinterpret_cast<LONG volatile*>(&mf_lnWaitSwitchCount));
::SwitchToThread();
}
For 8 threads (on 2 cores CPU) results are:

There are 643470 + 206 switches of threads' contexts here. This number is depend on vary factors, such as you network activity, running tasks etc. In respect with every switching takes thousands of CPU cycles, huge number of cycles is wasted. Obviously redundant switchings must be avoided by freezing of waiting threads.
Windows gives us complementary pair of functions: SuspendThread and ResumeThread. As argument they use thread's handle. But if thread calls SuspendThread to block self, how to unblock it ? Who knows about blocked threads ? So it's need to store and manage bookeeping information about blocked threads somewhere in application, in other words it's need some kind of threads scheduler. So I have to introduce separate thread to control and dispatch (schedule) these threads. All bookeeping work I implemented in this thread.
Threads interact with dispatcher thread via messages since Windows has rich set of functions to do this.
Approach #1.
Threads post messages to dispatcher via PostThreadMessage call. Message queue in dispatcher thread is created by standard call:
::PeekMessage(&msg, NULL, WM_USER, WM_USER, PM_NOREMOVE);
As results I have the follow:
Yet again, you will have different results. Not bad, but not enough. Main negative of this approach is weak synchronization between dispatcher and target thread. Message dequeued not immidiatelly, it waits some time in queue to be dequeued. And this latency can be dramatic. Since message is posted till dequeded and handled, thread is running and can acquire state of syncronization object (i.e. transfer it into maintenance mode). If scheduler blocks it at this moment we obtain deadlock: thread is own object is blocked, other threads are waiting for object state changing. That's why I have to post unblock message before querying object state:
LONG lnSpinSwitchCount(0);
::PostThreadMessageW(dwThreadDispatcherID, DM_THREAD_UNBLOCK, static_cast<WPARAM>(::GetCurrentThreadId()), 0);
while (lsMaintenanceMode == (LatchState = static_cast<LATCHSTATE>(::InterlockedExchange(reinterpret_cast<volatile LONG*>(&mf_LatchState), lsMaintenanceMode))))
{
if (lnSpinSwitchCount < THREAD_WAIT_SPIN_COUNT)
{
::YieldProcessor();
lnSpinSwitchCount++;
}
else
SpinOnce();
}
This is done only just to avoid deadlocking. So I need to build strong dispatching model:
Approach #2.
Threads send messages to dispatcher via SendMessage call. Dispatcher thread creates message-only window ("Message" class name). Don't forget to subclass window procedure. What is this for ? As you know, ::SendMessage call blocks calling thread, calls target window procedure directly and return result of this call (or result of ReplyMessage if window procedure use it). So thread is blocked since SendMessage is invoking. As result:
Much better.
Conclusions
1. All described objects are for use inside your application process. Naturally you can't pass it's reference outside of it (system or third-party modules, if this third-party is not you of course).
2. You can improve dispatchers by providing it with additional information. For example, you can introduce following interface into sinchronization object:
typedef enum
{
soCritical,
soNotification,
soEvent,
...
}
SYNC_OBJ_TYPE;
class __declspec(novtable) ISycnObjectTypeInfo
{
public:
virtual SYNC_OBJ_TYPE GetObjectType(void) = 0;
};
Each of object will return it own type. So you can provide messages with thread handle and pointer to syncronization object and your dispatcher can know what particular thread is blocked on what particular object. And by implementing interface above dispatcher will able to cast pointer to object properly.
3. Abandoned objects. If you ever used mutexes, you must know about abandoned mutexes. In available literature on Windows programming there are no unambiguous interpretation of abandoned objects (in any case I have not found it). As for me it means you loose your application flow control (logical error in one of threads). But in some cases you need to track such situations to log this event and save information or try to recover it (at least at stage of debugging). Vista threads' pools are good for this. Let your registered waits on thread handles send (or post) message to dispatcher. If your dispatcher knows all tracked threads and synchro objects it can try to switch state of synchronization object to avoid deadlock.
That's all.

